







一、环境&配置
鲲鹏服务器 128c 512G *6
每台主机普通SSD *5
Kylin V10(arm)
| 主机 | TiDB | PD | TiKV |
| ecs001 | 4 node | 1node | 4 node |
| ecs002 | 4 node | 1node | 4 node |
| ecs003 | 4 node | 1node | 4 node |
| ecs004 | 4 node | 4 node | |
| ecs005 | 4 node | 4 node | |
| ecs006 | 4 node | 4 node |
每个TiKV对应独立mount的文件系统(普通SSD)
总体配置:24TiDB 3PD 24TiKV
二、 优化
2.1、系统层面
1.1、TiDB/PD/TiKV绑核
128c,4个node,通过参数numa_node各绑一个node
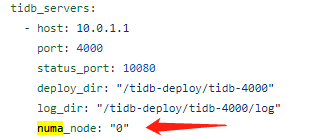
注:
1、理论上PD需要单独服务器部署(后期有机器再测:)
2、网络中断全绑一个node上(不用和tikv/tidb分开)
1.2、HAproxy绑核
HAproxy部署在单独的主机上,通过map参数绑核
global # 全局配置。
log 127.0.0.1 local2 # 定义全局的 syslog 服务器,最多可以定义两个。
chroot /var/lib/haproxy # 更改当前目录并为启动进程设置超级用户权限,从而提高安全性。
pidfile /var/run/haproxy.pid # 将 HAProxy 进程的 PID 写入 pidfile。
maxconn 4000 # 每个 HAProxy 进程所接受的最大并发连接数。
user haproxy # 同 UID 参数。
group haproxy # 同 GID 参数,建议使用专用用户组。
nbproc 64 # 在后台运行时创建的进程数。在启动多个进程转发请求时,确保该值足够大,保证 HAProxy 不会成为瓶颈。
daemon # 让 HAProxy 以守护进程的方式工作于后台,等同于命令行参数“-D”的功能。当然,也可以在命令行中用“-db”参数将其禁用。
stats socket /var/lib/haproxy/stats # 统计信息保存位置。
cpu-map 1 0
cpu-map 2 1
cpu-map 3 2
cpu-map 4 3
cpu-map 5 4
cpu-map 6 5
cpu-map 7 6
cpu-map 8 7
cpu-map 9 8
cpu-map 10 9
cpu-map 11 10
cpu-map 12 11
cpu-map 13 12
cpu-map 14 13
cpu-map 15 14
cpu-map 16 15
.....1.3、sysbench 和 tiup 绑核运行
# vi oltp_point_select.sh
nohup numactl -c 0-31 sysbench ... &
nohup numactl -c 32-63 sysbench ... &
nohup numactl -c 64-95 sysbench ... &
nohup numactl -c 96-127 sysbench ... &
<最后可加入文本处理语句,直接查看tps/qps>
<例:4000并发就每个sysbench启1000线程>tiup bench tpcc因为只测1000线程,所以只需要绑一个node;绑多个node会造成测试结果下降
2.2、数据库层面
Tidb:
log.level: "error"
prepared-plan-cache.enabled: true
tikv-client.max-batch-wait-time: 2000000
performance.txn-total-size-limit: 10737418240
txn-local-latches.enabled: true
tikv-client.grpc-connection-count: 10
tikv:
pessimistic-txn.pipelined: true
raftdb.allow-concurrent-memtable-write: true
raftdb.max-background-jobs: 16
raftstore.sync-log: false
raftstore.apply-max-batch-size: 2048
raftstore.apply-pool-size: 5
raftstore.store-max-batch-size: 2048
raftstore.store-pool-size: 5
readpool.storage.high-concurrency: 30
readpool.storage.normal-concurrency: 30
readpool.storage.low-concurrency: 30
readpool.unified.max-thread-count: 20
readpool.unified.min-thread-count: 5
rocksdb.max-background-jobs: 15
server.grpc-concurrency: 10
storage.scheduler-worker-pool-size: 20
server.enable-request-batch: false
Tidb全局:
set global tidb_hashagg_final_concurrency=1;
set global tidb_hashagg_partial_concurrency=1;
set global tidb_enable_async_commit = 1;
set global tidb_enable_1pc = 1;
set global tidb_guarantee_linearizability = 0;
set global tidb_enable_clustered_index = 1;
set global tidb_enable_tso_follower_proxy=true;
//5.3加入的新特性,高并发场景下点查延迟大幅度降低三、部分测试结果
3.1、sysbench
32张表,单表1亿,rand-type=uniform,测试先查后写
sysbench 1.0.20,github源码编译
| 场景 | 并发数(threads) | Tidb v5.3.0 | |
| point_select | 100 | tps | 229820.37 |
| 95th 延迟 | 0.49 | ||
| 300 | tps | 789232 | |
| 95th 延迟 | 1.1 | ||
| 1000 | tps | 1101896.89 | |
| 95th 延迟 | 2.53 | ||
| 4000 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









