







 本文探讨了在细粒度识别中,尤其在样本稀缺的情况下,如何利用PoseNorm改进神经网络建模能力。PoseNorm通过定位图片语义部分,增强特征提取的针对性,即使在只有少量标注数据时也能显著提升性能。研究还展示了PoseNorm在适应少样本学习和与传统黑箱方法的对比中的优势。
本文探讨了在细粒度识别中,尤其在样本稀缺的情况下,如何利用PoseNorm改进神经网络建模能力。PoseNorm通过定位图片语义部分,增强特征提取的针对性,即使在只有少量标注数据时也能显著提升性能。研究还展示了PoseNorm在适应少样本学习和与传统黑箱方法的对比中的优势。
沉睡在草稿箱很久的paper笔记
摘要
少样本的细粒度识别是在每一细粒度类只有很少量的样本的情境下,进行细粒度分类。 因此,它对于清晰度、目标姿势和背景有很显著的稳定性要求。其中一个的解决方法是:首先,定位每个图片的语义部分,使用每一个语义部分描述图片,虽然这种做法不是很适合全监督学习,但是已经很有效了。随着建模能力的增加,Pose Normalize的精度可以被提高很多,生成一个新的域,也是细粒度少样本的一个思路。
简介
对这种 minimal 细粒度识别更加看重神经网络的建模能力,不仅不可见数据,甚至不可见数据类型。比如只有某一个类别下,只有一个数据图片,我们也希望模型能够学习的很好,实际上,人类能够仅仅通过一张图很清楚的图片,学习到一个类别的鉴别方法。尽管最近的视觉识别的进步巨大,但是在少样本领域,还是有几个基线没有全监督的表现好(benchmark)。
由于细粒度识别的标签制作很困难,需要专家和专业知识,所以大体量的细粒度数据集是很难获得的,真实应用场景可能面对更多的是细粒度、少样本学习。
机器和人在这种情境下,完成任务有哪些差距?初始假设:人类拥有异常稳定的特征提取器,它甚至可以无视空间尺寸的变化,例如鸟类识别任务中,人类会捕捉翅膀、颜色、尾巴等特征,人类在捕捉特征时,不会因为照片姿势和清晰度而降低捕捉性能,它仍然能够获得不同类之间的相似性和差异性。
在深度网络之前,Pose Norm 是一个很有前途的研究方向,但是深度网络的黑箱即使不 Pose Norm 仍然能表现的很好,超过很多 benchmark,比如双线性。Pose Norm 已经渐渐的被遗忘了。
相反,大部分的黑箱架构是在那么一个情景下:细粒度分类是一个全监督问题,所有类的分布是先验的,每一类别都有着大量的数据支撑,训练数据已经出现了广泛的背景和姿势。Pose Norm 显得很多余,没什么意义了。然而如果在 细粒度少样本的场景下,Pose Norm 可以是一个很重要的方法。
我们重新调整 Pose Norm ,让这个方法适应细粒度少样本学习,并且证明它很适合这个 setting。Pose Norm 是一个简单有效的方法,增加了很少的参数,之前的方法增加的参数是神经网络的两倍。 我们将 Pose Norm 放置在各种深度架构网络下,实验我们的性能。
- 在没有 part 注释下,Pose Norm 显著提高了性能,甚至20%;【这一点感觉没有说清楚,应该是细粒度少样本情境下提高了那么多】
- Pose Norm 优于其他的黑箱调整比如 双线性
- 即使只有一部分数据使用了姿势标注,Pose Norm 带来的性能提升也很大
少样本学习
少样本学习的目标是建立一个学习器,能够对仅有少量样本标签的类别提供有效的分类。少样本学习可以使用预训练数据集
D
r
e
p
r
e
,
Y
b
a
s
e
D_{repre}, Y_{base}
Drepre,Ybase,然后面对新的样本集
D
r
e
f
e
r
,
Y
n
o
v
e
l
D_{refer},Y_{novel}
Drefer,Ynovel。学习器能够很好的适应少样本学习。
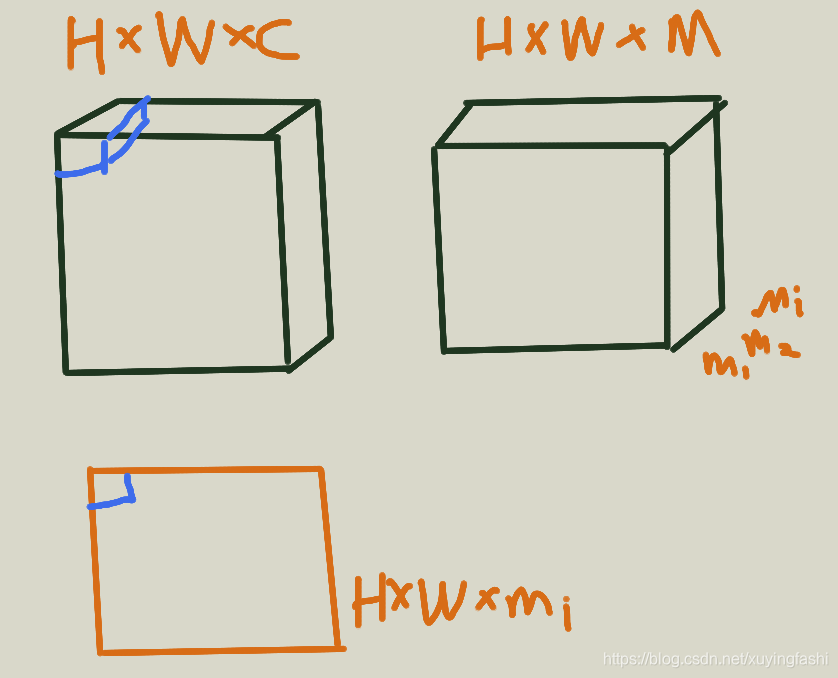
一般情况下,分为三个模块:f、g和h:
f:使用深度神经网络进行,正常的特征提取,输入图片,输出特征张量
F
∈
R
C
∗
H
∗
W
F\in R^{C*H*W}
F∈RC∗H∗W;
g:聚合函数,把 feature map 转化为全局特征向量,比如全局池化。得到的向量是
v
∈
R
d
v \in R^{d}
v∈Rd;
h:最后的使用概率的分类函数、
迁移学习是使用标准的网络进行预训练,然后进行微调。h 是简单的线性分类,使用了权重矩阵和softmax函数。f、g和h三者同时训练减少交叉熵损失。一般,为了进行迁移学习,特征提取器和聚合函数被冻结,微调分类函数。
Prototypical network 是一个比较有代表性的元学习方法:通过平均类内的特征向量得到一个类的元特征,h 是一个无参数的分类器,样本特征通过计算和元特征的距离,作为分类的概率,大概的过程是这样的:从样本集中抽取出支撑集和查询集,从支撑集中获得元特征,在查询集中进行损失计算和参数更新。
Dynamic few-shot learning 动态少样本学习
Pose Norm
我们的方法有两个灵感出发点:1. 少样本细粒度识别很难有例子来获得那些细小差别。Pose Norm 可以将特征提取器集中在信息最丰富的区域,从而有利于学习过程。2. 由于细粒度识别的特征,它们可能会分享共同的特征。
因此,我们可以在 base类上 做一个 Pose 估计,并且甚至能推广到不可见类。
我们假设识别对象上有 M 个关键部分,
D
r
e
p
r
e
D_{repre}
Drepre 中可以出现 Part 标注,但是新类中是没有的。我们规定每张图片 x 的 Part 注释表示为
m
∗
=
M
∗
H
∗
W
m*=M*H*W
m∗=M∗H∗W,H和W是 feature map 的空间尺寸。
如何进行 Pose Norm?
网络首先要估计 pose,我们使用一个额外的小型(只有两层)的神经网络 q作为姿势估计的网络。实验表明这个小网络是足够的,参数少,性能不错。它的输入是
F
′
∈
R
C
′
∗
H
′
∗
W
′
F' \in R^{C'*H'*W'}
F′∈RC′∗H′∗W′,输出是
m
=
q
(
F
)
∈
R
M
∗
H
∗
W
m = q(F) \in R^{M*H*W}
m=q(F)∈RM∗H∗W。
F
′
F'
F′ 是 feature map extractor 的中间输出。
已经得到的 姿势热图(pose heatmap)
m
m
m 和 特征图(feature map)
F
F
F,我们需要构建一个特征向量
v
v
v,
m
m
m 的每个通道都可以被作用在 feature map上,可以看做一个 mask。连接 M 个 Part 的特征,我们就可以得到最后的特征向量:
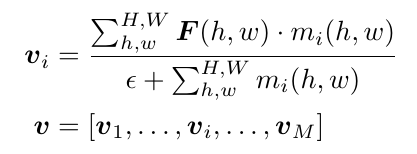
下面的这个图解释这个公式:
这个是一个全监督的方法,所以存在一个热图真实值
m
∗
m*
m∗:
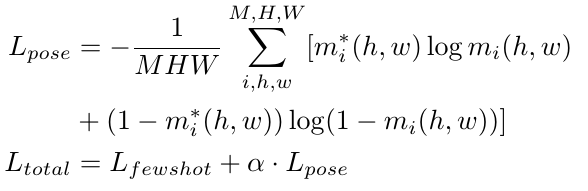
α
\alpha
α 是一个超参数,可以进行平衡调整。为了更好的进行分类,最开始的训练阶段, feature vector 可以使用
m
∗
m*
m∗,而不是
m
m
m。在测试阶段才使用 自己预测的
m
m
m,对分类进行微调。
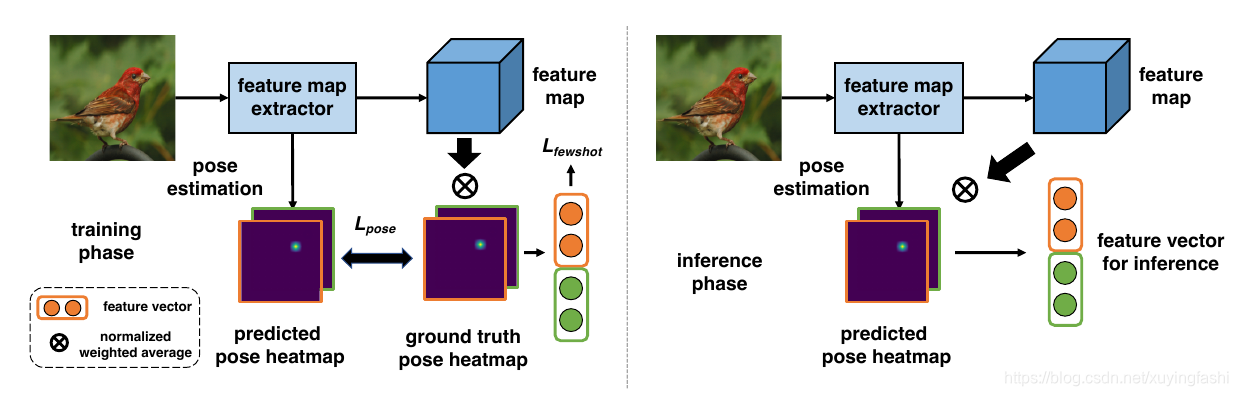
虽然我们的 Part 是固定的,但是我们不要求所有的 Part都存在或者允许出现一些个例。
实验
CUB 有 200个鸟类,划分出100个 base集,50个验证集, 50个查询集。base集是有 Part注释的,但是其他两种集合都没有。
训练模型使用
D
r
e
p
r
e
C
U
B
D_{repre}^{CUB}
DrepreCUB,超参数的调整使用验证集,验证使用的是限制标签数的查询集。我们采用的是 all-way 的方式进行训练。【all-way 是指所有的类别都参数训练, N-way 是指 N 个类别参与训练。】我们从 1-shot 到 5-shot 的进行对比实验。

uPN 是一种无监督的 Pose Norm:首先将 feature map 划分为若干个 soft region。然后引入类别未知的15个 pose vector。根据 soft region 和 pose vector的距离,判断是否作为 Part 区域,将15个 Part区域 像上面一样的处理就可以了。
条形图可以表现出一点,无论是复杂的还是简单的网络,PN方法都能够带来很大的性能提升;PN在性能上优于其他的聚合函数比如BP、bbx等。
Pose注释的数量的影响
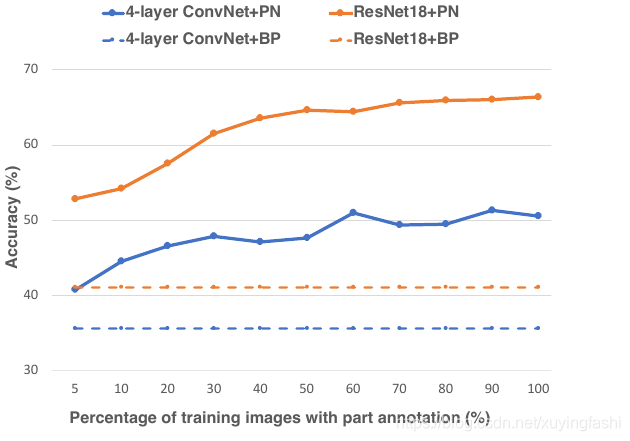
注释数量的百分比是一个 log 型的函数,也就是50% 其实和 70%的差距不是很大。
分析
每个种类的鸟在 Part 都有自己独特的区别,那么我们需要验证我们的模型的确学习到了这些区别。我们将某个 Part 独立的移出,然后观察精度的变化,从而证明 Part的确被有效的学习到了。
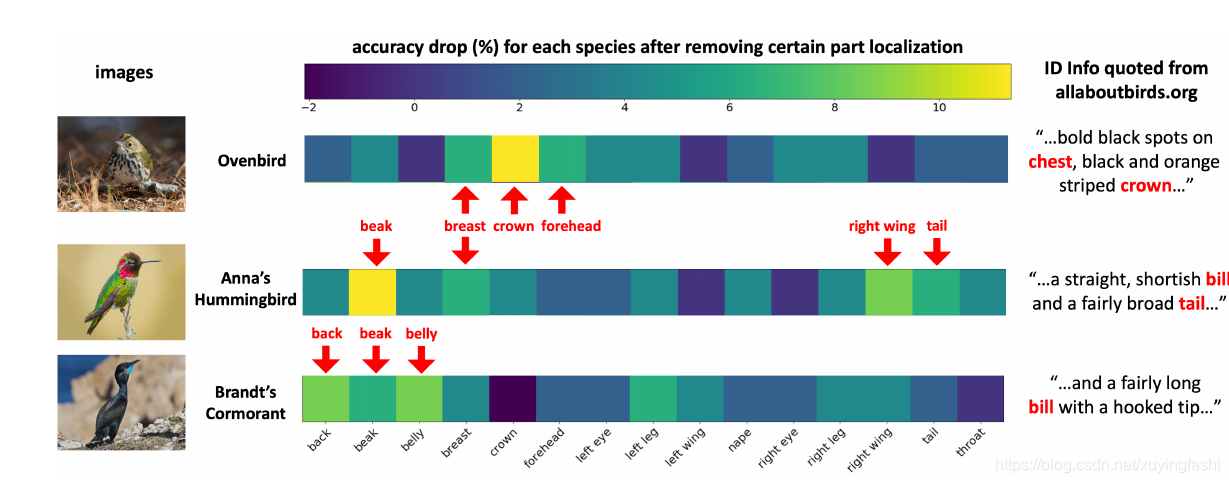
图片中,右侧是专家对该类鸟的一个特征描述,左边是鸟类的图片,中间是 Part 的影响直观表示。
特征相似
不同的鸟类在某个 part 的属性可能很相似,那么我们验证我们获得 part 也拥有这个性质。比如 A 类鸟和 B 类鸟有着相似的喙,那么它们 pose nom 之后的 part vector 应该也相似。我们从参考集中找到和查询集中 vector 最相似的前五个图片(某个 Part vector):
图中,可以发现 相似 vector 找到的相似图片的特征的确都相似。

Pose 估计
Posse估计这一节主要内容就是证明 它的Pose的估计 和真实 Pose 注释的重合程度很大:
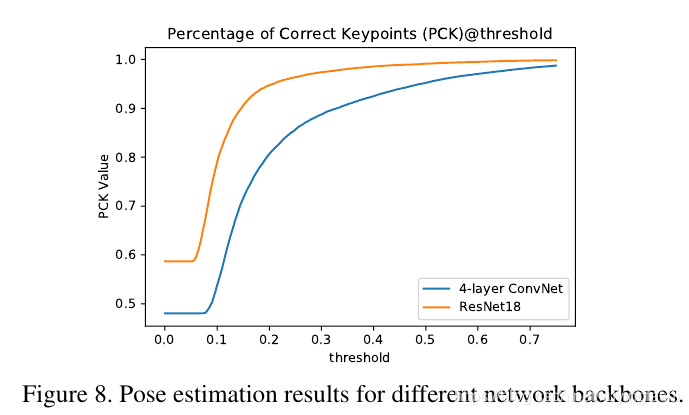 这个阈值搞得不是很明白:
这个阈值搞得不是很明白:
PCK 的意思:关键点正确估计的比例
计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例(the percentage of detections that fall within a normalized distance of the ground truth).

















 6864
6864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









