







# 模型训练
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"\n评估结果:\nMSE: {mse:.2f}\nR²: {r2:.2f}")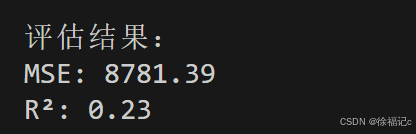
从这个评估结果来看,这个模型的表现是较差的。以下是具体分析:
1. MSE(均方误差)
-
MSE 是衡量模型预测值与真实值之间差异的指标。MSE 越小,模型的预测误差越小。
-
你提供的 MSE 是 8781.39,这个值的大小需要结合数据的范围来判断。如果目标变量的值范围较大(比如在几万以上),那么这个 MSE 可能并不算特别糟糕;但如果目标变量的值范围较小(比如在几百以内),这个 MSE 就显得非常大,说明模型的预测误差很大。
2. R²(决定系数)
-
R² 是衡量模型解释数据方差能力的指标,取值范围在 [0, 1]。R² 越接近 1,模型的解释能力越强;R² 越接近 0,模型的解释能力越弱。
-
你提供的 R² 是 0.23,这意味着模型只能解释目标变量 23% 的方差,其余 77% 的方差无法被模型解释。这表明模型的拟合能力较差,几乎接近随机预测的水平。
3. 综合判断
-
从 R² 的角度来看,模型的表现是非常差的,因为 R² 接近 0,说明模型几乎没有解释能力。
-
从 MSE 的角度来看,虽然无法直接判断好坏,但结合 R² 的结果,可以推测模型的预测误差较大。
4. 改进建议
-
特征工程:检查输入特征是否足够有效,是否遗漏了重要的特征,或者是否存在噪声特征。
-
模型调参:尝试调整 XGBoost 的超参数(如学习率、树的深度、正则化参数等),以提高模型的性能。
-
数据预处理:检查数据是否存在异常值、缺失值或分布不均的问题,必要时进行归一化或标准化。
-
模型选择:如果 XGBoost 的表现较差,可以尝试其他回归模型(如 LightGBM、CatBoost 或神经网络)。
总结来说,这个模型的表现较差,需要进一步优化。

















 1719
1719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









