







 超级会员免费看
超级会员免费看
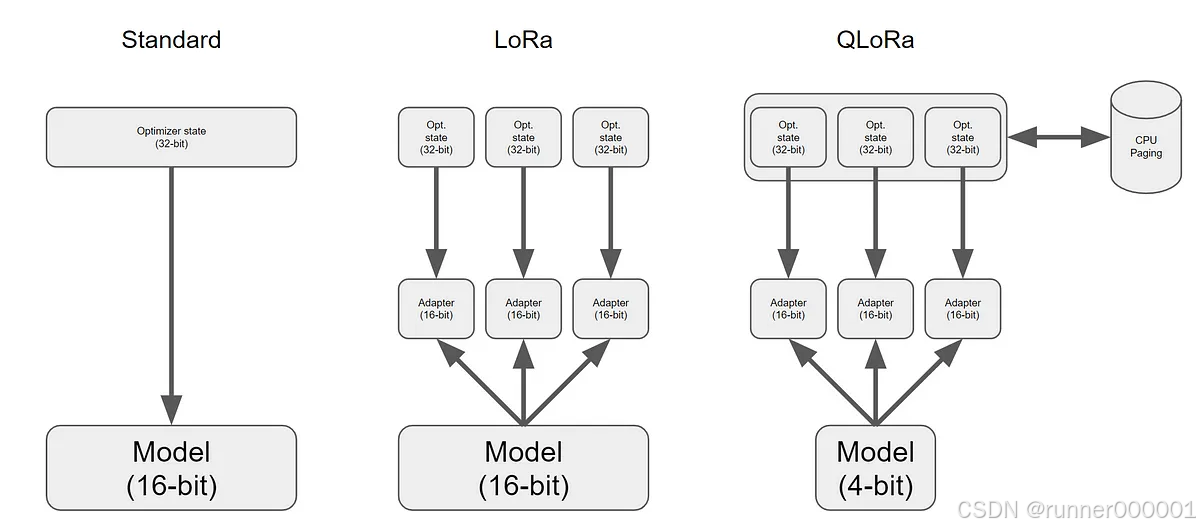
1️⃣ Standard(标准微调)
-
模型参数:16-bit(通常是 FP16)
-
Optimizer State:32-bit
-
直接更新整个模型,内存占用大
2️⃣ LoRA(Low-Rank Adaptation)
-
模型仍为 16-bit,只冻结预训练模型权重
-
添加多个小的可训练 Adapter(16-bit)
-
只训练 Adapter + 优化器状态(32-bit)
-
大幅减少可训练参数数量和内存使用
3️⃣ QLoRA(Quantized LoRA)
-
模型参数被量化为 4-bit(极大节省内存)
-
模型权重不可训练
-
只训练 16-bit 的 Adapter 层(与 LoRA 类似)
-
优化器状态仍为 32-bit
-
支持 CPU Paging:当显存不足时,将优化器状态分页到 CPU 内存中,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











