







 本文探讨了Flink中window函数(如apply和process)的全量与增量聚合的差异,以及在keyBy后的processWindowFunction和keyedProcessFunction的不同,涉及状态使用和定时器的应用,重点讲解了计算PV和UV的方法实例。
本文探讨了Flink中window函数(如apply和process)的全量与增量聚合的差异,以及在keyBy后的processWindowFunction和keyedProcessFunction的不同,涉及状态使用和定时器的应用,重点讲解了计算PV和UV的方法实例。
0、总结
windows后面可以添加apply,process,然后apply传入WindowsFunction, process传入processWindowsFuction,是全量窗口函数。当然也可以用增量聚合函数agg,reduce等
直接keyby后面可以用process,然后传入KeyedProcessFunction,是一条一条处理数据。当然也可以用agg,reduce函数,它是带状态处理的,会把历史数据进行累加
1、只有window后的算子才区分增量聚合(sum,min,reduce)和全量聚合(appply,process)的区别
// Window process(传入processWindowFucntion),Window appply(传入windowFunction)全窗口计算,先把窗口的数据收集起来,等到窗口结束的时候会遍历所有的数据,效率低,有些场景增量聚合的数没太大用,比如排序、算中位数,
Window Apply(window窗口时间到了处理每个元素,属于传统的ProcessWindowFunction,没有 per-window keyed state)
def process[R: TypeInformation](
function: ProcessWindowFunction[T, R, K, W]): DataStream[R] = {
val cleanFunction = clean(function)
val applyFunction = new ScalaProcessWindowFunctionWrapper[T, R, K, W](cleanFunction)
asScalaStream(javaStream.process(applyFunction, implicitly[TypeInformation[R]]))
}
def apply[R: TypeInformation](
function: WindowFunction[T, R, K, W]): DataStream[R] = {
val cleanFunction = clean(function)
val applyFunction = new ScalaWindowFunctionWrapper[T, R, K, W](cleanFunction)
asScalaStream(javaStream.apply(applyFunction, implicitly[TypeInformation[R]]))
}
2、window 的增量聚合算子中可以加入全量聚合窗口函数
例如 Aggreate+ProcessWindowFunction:内部重写process方法
或者Aggreate+WindowFunction:内部重写apply方法
都是收集到全量数据再处理,唯一的不同是apply里面不能创建keyed_state状态,没有open方法
案例:
main{
val aggregateData: DataStream[String] = dataStream
.process(new getLastFunction)
.keyBy("itemId")
.window(TumblingProcessingTimeWindows.of(Time.seconds(15)))
.aggregate(new CountAggregate,new MyProcessWindowFunction)
aggregateData.print()
}
case class result(itemId: Long, count: Long)
//AggregateFunction<IN, ACC, OUT>
//ACC createAccumulator(); 迭代状态的初始值
//ACC add(IN value, ACC accumulator); 每一条输入数据,和迭代数据如何迭代
//ACC merge(ACC a, ACC b); add方法后的迭代数据如何合并
//OUT getResult(ACC accumulator); 当前分区返回数据,对最终的迭代数据如何处理,并返回结果。
class CountAggregate extends AggregateFunction[result, Long, String] {
override def createAccumulator() = 6L
override def add(value: result, accumulator:Long) =
value.count+accumulator
override def getResult(accumulator: Long) = "windows count is:"+accumulator.toString
override def merge(a: Long, b: Long) =
a+b
}
class MyProcessWindowFunction extends ProcessWindowFunction[String, String, Tuple, TimeWindow] {
def process(key: Tuple, context: Context, input: Iterable[String], out: Collector[String]) = {
val count = input.iterator.next()
out.collect("window end is :"+context.window.getEnd+"key is :"+key+count)
}
}
3、keyBy后的算子都是增量状态聚合,process传入KeyedProcessFunction,每次只处理一条数据,可以利用状态和定时器
所以总结上三条
windowFunction 和processWindowFunction都是处理全量数据,但后者可以用state状态
processWindowFunction和(keyby windowEnd后的)keyedProcessFunction的区别是没有window的后者每次处理一条数据,后者经常用状态编程和定时器,前者每次处理的是全量数据,而且没有定时器
4、计算pv(解决数据倾斜问题)
package flinkProject
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.{AggregateFunction, MapFunction}
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{ProcessWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.util.Random
//输入数据样例类
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timeStamp: Long)
//定义输出pv统计样例类
case class PvCount(windowEnd: Long, count: Long)
object PageViewAndUV {
def main(args: Array[String]): Unit = {
val executionEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
executionEnvironment.setParallelism(1)
executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //watermark周期性生成,默认是200ms
// val stream2: DataStream[String] = executionEnvironment.readTextFile("src/main/resources/pv.txt")
val stream2: DataStream[String] = executionEnvironment.socketTextStream("127.0.0.1", 1111)
val transforStream: DataStream[UserBehavior] = stream2.map(data => {
val tmpList = data.split(" ")
val simpleDateFormat = new SimpleDateFormat("dd/mm/yy:HH:mm:ss")
val ts = simpleDateFormat.parse(tmpList(3)).getTime
UserBehavior(tmpList(0).split("\\.")(0).toLong, tmpList(0).split("\\.")(1).toLong, tmpList(0).split("\\.")(1).toInt, tmpList(5), ts)
}).assignAscendingTimestamps(_.timeStamp)
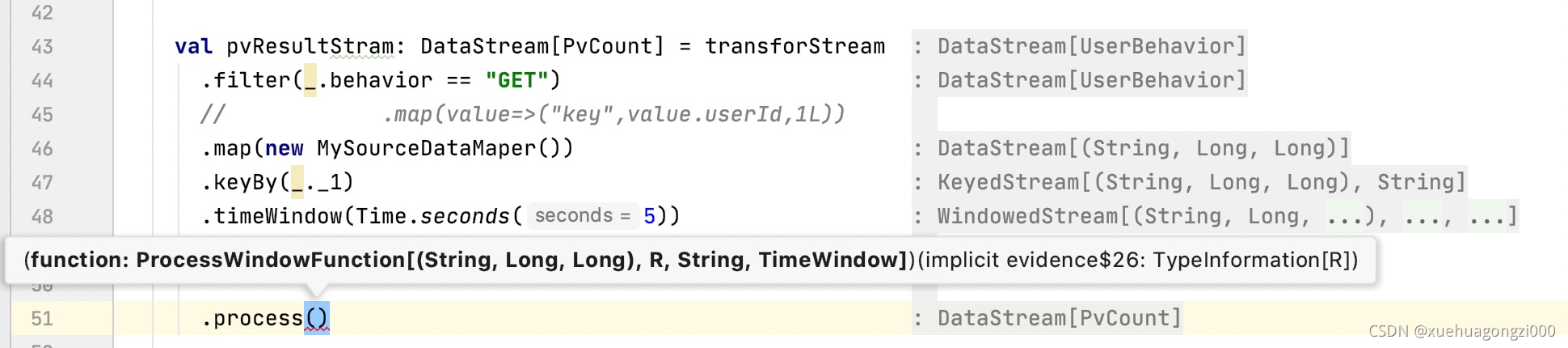
val pvResultStram: DataStream[PvCount] = transforStream
.filter(_.behavior == "GET")
// .map(_=>("key",1L))
.map(new MySourceDataMaper())
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.aggregate(new PvAggregateFunction(), new PvWindowFunction())
val totalDataStream: DataStream[PvCount] = pvResultStram
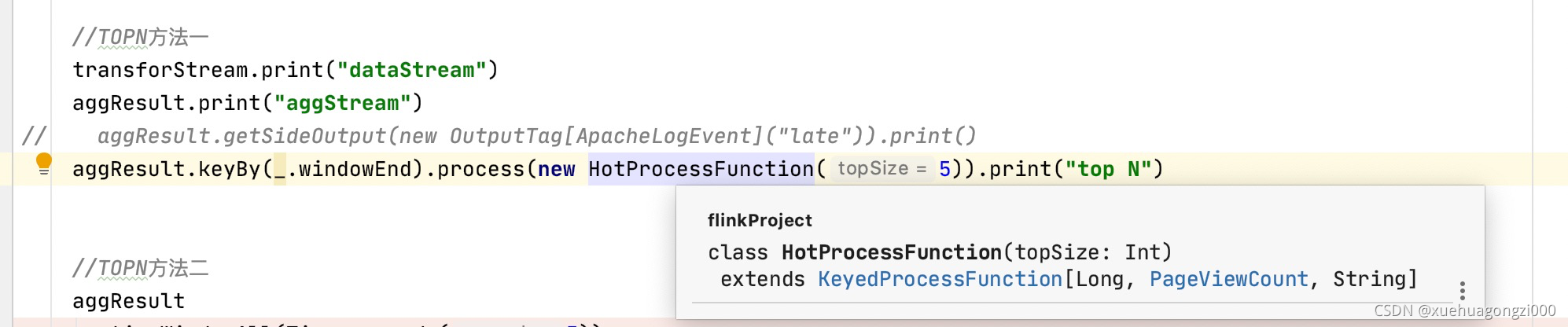
.keyBy(_.windowEnd)
// .sum("count")
.process(new TotalResultProcessFunction())
// pvResultStram.print()
totalDataStream.print()
executionEnvironment.execute("PageViewAndUV ")
}
}
class PvAggregateFunction extends AggregateFunction[(String, Long), Long, Long] {
override def createAccumulator(): Long = 0L
override def add(value: (String, Long), accumulator: Long): Long = value._2 + accumulator
override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a + b
}
class PvWindowFunction extends WindowFunction[Long, PvCount, String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[PvCount]): Unit = {
out.collect(PvCount(window.getEnd(), input.head))
}
}
class MySourceDataMaper extends MapFunction[UserBehavior,(String,Long)] {
override def map(value: UserBehavior): (String, Long) = {
(Random.nextString(10),1L )
}
}
class TotalResultProcessFunction extends KeyedProcessFunction[Long,PvCount,PvCount] {
var countState:ValueState[Long]=_
override def open(parameters: Configuration): Unit = {
countState=getRuntimeContext.getState(new ValueStateDescriptor[Long]("countState",classOf[Long]))
}
override def processElement(i: PvCount, context: KeyedProcessFunction[Long, PvCount, PvCount]#Context, collector: Collector[PvCount]): Unit = {
var tmpCount=countState.value();
tmpCount+=i.count
countState.update(tmpCount )
context.timerService().registerEventTimeTimer(context.getCurrentKey+1)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, PvCount, PvCount]#OnTimerContext, out: Collector[PvCount]): Unit = {
out.collect(PvCount(ctx.getCurrentKey,countState.value() ))
countState.clear()
}
}
5、计算UV:从开始就将user_id放入到set中进行聚合
package flinkProject
import java.{lang, util}
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.{AggregateFunction, MapFunction}
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{ProcessWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable
import scala.util.Random
//输入数据样例类
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timeStamp: Long)
//定义输出pv统计样例类
case class PvCount(windowEnd: Long, set: mutable.HashSet[Long], count: Long)
object PageViewAndUV {
def main(args: Array[String]): Unit = {
val executionEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
executionEnvironment.setParallelism(1)
executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //watermark周期性生成,默认是200ms
// val stream2: DataStream[String] = executionEnvironment.readTextFile("src/main/resources/pv.txt")
val stream2: DataStream[String] = executionEnvironment.socketTextStream("127.0.0.1", 1111)
val transforStream: DataStream[UserBehavior] = stream2.map(data => {
val tmpList = data.split(" ")
val simpleDateFormat = new SimpleDateFormat("dd/mm/yy:HH:mm:ss")
val ts = simpleDateFormat.parse(tmpList(3)).getTime
UserBehavior(tmpList(0).split("\\.")(0).toLong, tmpList(0).split("\\.")(1).toLong, tmpList(0).split("\\.")(1).toInt, tmpList(5), ts)
}).assignAscendingTimestamps(_.timeStamp)
val pvResultStram: DataStream[PvCount] = transforStream
.filter(_.behavior == "GET")
// .map(value=>("key",value.userId,1L))
.map(new MySourceDataMaper())
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.aggregate(new PvAggregateFunction(), new PvWindowFunction())
// .aggregate(new PvAggregateFunction(), new PvProcessWindowFunction())
val totalDataStream: DataStream[PvCount] = pvResultStram
.keyBy(_.windowEnd)
// .sum("count")
.process(new TotalResultProcessFunction())
// pvResultStram.print()
totalDataStream.print()
executionEnvironment.execute("PageViewAndUV ")
}
}
class PvAggregateFunction extends AggregateFunction[(String, Long, Long), (mutable.HashSet[Long], Long), (mutable.HashSet[Long], Long)] {
override def createAccumulator(): (mutable.HashSet[Long], Long) = {
(mutable.HashSet(), 0L)
}
//2、聚合的时候将userId添加到set中
override def add(value: (String, Long, Long), accumulator: (mutable.HashSet[Long], Long)): (mutable.HashSet[Long], Long) = {
(accumulator._1.asInstanceOf[mutable.HashSet[Long]].+=(value._2), accumulator._2 + value._3)
}
override def getResult(accumulator: (mutable.HashSet[Long], Long)): (mutable.HashSet[Long], Long) = accumulator
override def merge(a: (mutable.HashSet[Long], Long), b: (mutable.HashSet[Long], Long)): (mutable.HashSet[Long], Long) = (a._1.asInstanceOf[mutable.HashSet[Long]] ++= b._1, a._2 + a._2)
}
class PvWindowFunction extends WindowFunction[(mutable.HashSet[Long], Long), PvCount, String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[(mutable.HashSet[Long], Long)], out: Collector[PvCount]): Unit = {
//3、将每个key对应的set集合发送到下游
out.collect(PvCount(window.getEnd, input.head._1, input.head._2))
}
}
class PvProcessWindowFunction extends ProcessWindowFunction[Long, PvCount, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[Long], out: Collector[PvCount]): Unit = {
}
}
class MySourceDataMaper extends MapFunction[UserBehavior, (String, Long, Long)] {
override def map(value: UserBehavior): (String, Long, Long) = {
//1、将user_id传入到后续处理
(Random.nextString(10), value.userId, 1L)
}
}
class TotalResultProcessFunction extends KeyedProcessFunction[Long, PvCount, PvCount] {
var countState: ValueState[Long] = _
var mapState: MapState[String, Long] = _
override def open(parameters: Configuration): Unit = {
countState = getRuntimeContext.getState(new ValueStateDescriptor[Long]("countState", classOf[Long]))
mapState = getRuntimeContext.getMapState(new MapStateDescriptor[String, Long]("mapState", classOf[String], classOf[Long]))
}
override def processElement(i: PvCount, context: KeyedProcessFunction[Long, PvCount, PvCount]#Context, collector: Collector[PvCount]): Unit = {
var tmpCount = countState.value();
tmpCount += i.count
countState.update(tmpCount)
var tmpMutableHashSet: mutable.HashSet[Long] = mutable.HashSet[Long]()
tmpMutableHashSet = i.set
//4、将set存入到map中去重
tmpMutableHashSet.foreach(value => mapState.put(value.toString, value))
context.timerService().registerEventTimeTimer(context.getCurrentKey + 1)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, PvCount, PvCount]#OnTimerContext, out: Collector[PvCount]): Unit = {
var tmpMutableHashSet: mutable.HashSet[Long] = mutable.HashSet[Long]()
val value: util.Iterator[Long] = mapState
.values()
.iterator()
//5、将map中的值取出来存入set集合中
while (value.hasNext) {
tmpMutableHashSet.+=(value.next())
}
out.collect(PvCount(ctx.getCurrentKey, tmpMutableHashSet, countState.value()))
countState.clear()
mapState.clear()
}
}
输入数据
89.101 - - 17/05/2015:10:25:43 +0000 GET /presedent 87.101 - - 17/05/2015:10:25:46 +0000 GET /presedent 86.101 - - 17/05/2015:10:25:47 +0000 GET /presedent 85.101 - - 17/05/2015:10:25:51 +0000 GET /presedent 84.101 - - 17/05/2015:10:25:52 +0000 GET /presedent 83.101 - - 17/05/2015:10:25:53 +0000 GET /presedent 82.101 - - 17/05/2015:10:25:56 +0000 GET /presedent

















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









