








最近有个需求,实时统计pv,uv,结果按照date,hour,pv,uv来展示,按天统计,第二天重新统计,当然了实际还需要按照类型字段分类统计pv,uv,比如按照date,hour,pv,uv,type来展示。这里介绍最基本的pv,uv的展示。
id |
uv |
pv |
date |
hour |
|---|---|---|---|---|
| 1 | 155599 | 306053 | 20180727 | 00 |
| 2 | 255496 | 596223 | 20180727 | 01 |
| … | … | … | … | … |
| 10 | 10490270 | 12927245 | 20180727 | 10 |
关于什么是pv,uv,可以参见这篇博客https://blog.youkuaiyun.com/petermsh/article/details/78652246
分析
这是一个常用的实时数据统计需求,实时处理目前可供选择的有sparkStreaming和flink,使用sparkStreaming可以使用累加器,如果字段取值水平过多,不现实了,这时候考虑使用状态算子updateStateByKey或mapWithState(),或者使用redis、mysql等做累加,去重可以使用内存、redis的Set集合,或者使用算法bloomfilter过滤器、HyperLogLog近似去重,如果是数字还可以使用bitmap去重,这里的guid是38位字符串,选择使用redis的Set集合去重。
SparkStreaming实时统计pv uv
1、项目流程
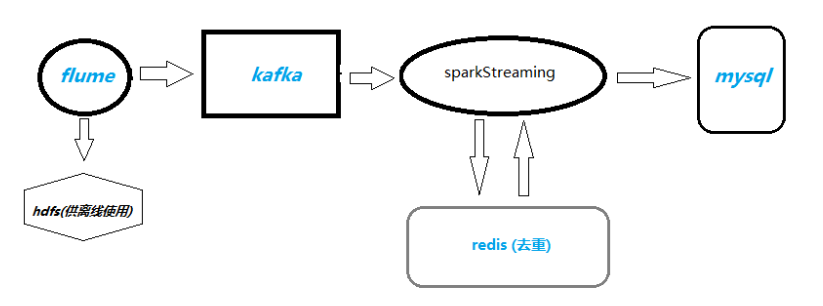
日志数据从flume采集过来,落到hdfs供其它离线业务使用,也会sink到kafka,sparkStreaming从kafka拉数据过来,计算pv,uv,uv是用的redis的set集合去重,最后把结果写入mysql数据库,供前端展示使用。
2、具体过程
1)PV的计算
拉取数据有两种方式,基于received和direct方式,这里用direct直拉的方式,用的mapWithState算子保存状态,这个算子与updateStateByKey一样,并且性能更好。当然了实际中数据过来需要经过清洗,过滤,才能使用。
定义一个状态函数
1 |
// 实时流量状态更新函数 |
1 |
计算pv |
这样就很容易的把pv计算出来了。
2)UV的计算
uv是要全天去重的,每次进来一个batch的数据,如果用原生的reduceByKey或者groupByKey对配置要求太高,在配置较低情况下,我们申请了一个93G的redis用来去重,原理是每进来一条数据,将date作为key,guid加入set集合,20秒刷新一次,也就是将set集合的尺寸取出来,更新一下数据库即可。
1 |
helper_data_dis.foreachRDD(rdd => { |
redis连接池代码RedisPoolUtil.scala:
package com.js.ipflow.utils
import com.js.ipflow.start.ConfigFactory
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool
/**
* redis 连接池工具类
* @author keguang
*/
object RedisPoolUtil extends Serializable{
private var pool: JedisPool = null
/**
* 读取jedis配置信息, 出发jedis初始化
*/
def initJedis: Unit ={
ConfigFactory.initConfig()
val maxTotal = 50
val maxIdle = 30
val minIdle = 10
val redisHost = ConfigFactory.redishost
val redisPort = ConfigFactory.redisport
val redisTimeout = ConfigFactory.redistimeout
val redisPassword = ConfigFactory.redispassword
makePool(redisHost, redisPort, redisTimeout, redisPassword, maxTotal, maxIdle, minIdle)
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8604
8604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











