










1、简介
构建您的第一个流程
了解如何创建结构化的、事件驱动的工作流程,并对执行进行精确控制。
利用 Flows 控制 AI 工作流程
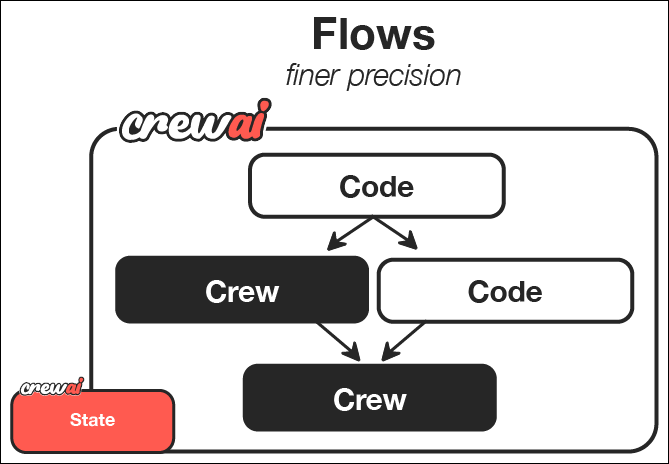
CrewAI Flows 代表了 AI 编排的全新境界,将 AI 代理团队的协作能力与程序化编程的精准性和灵活性相结合。团队擅长代理协作,而流程则让您能够精细地控制 AI 系统各个组件的交互方式和时间。
我将逐步讲解如何创建一个功能强大的 CrewAI Flow,它可以生成涵盖任何主题的全面学习指南。本教程将演示 Flows 如何通过结合常规代码、直接 LLM 调用和基于团队的处理,为您的 AI 工作流提供结构化、事件驱动的控制。
是什么让 Flows 如此强大
流程使您能够:
- 结合不同的 AI 交互模式:使用团队完成复杂的协作任务,直接调用 LLM 进行更简单的操作,并使用常规代码进行程序逻辑
- 构建事件驱动系统:定义组件如何响应特定事件和数据变化
- 跨组件维护状态:在应用程序的不同部分之间共享和转换数据
- 与外部系统集成:将您的 AI 工作流程与数据库、API 和用户界面无缝连接
- 创建复杂的执行路径:设计条件分支、并行处理和动态工作流
2、创建 CrewAI Flow 项目
首先,让我们使用 CLI 创建一个新的 CrewAI Flow 项目。此命令将设置一个脚手架项目,其中包含流程所需的所有目录和模板文件。
crewai create flow guide_creator_flow
cd guide_creator_flow

这将生成一个具有流程所需的基本结构的项目。
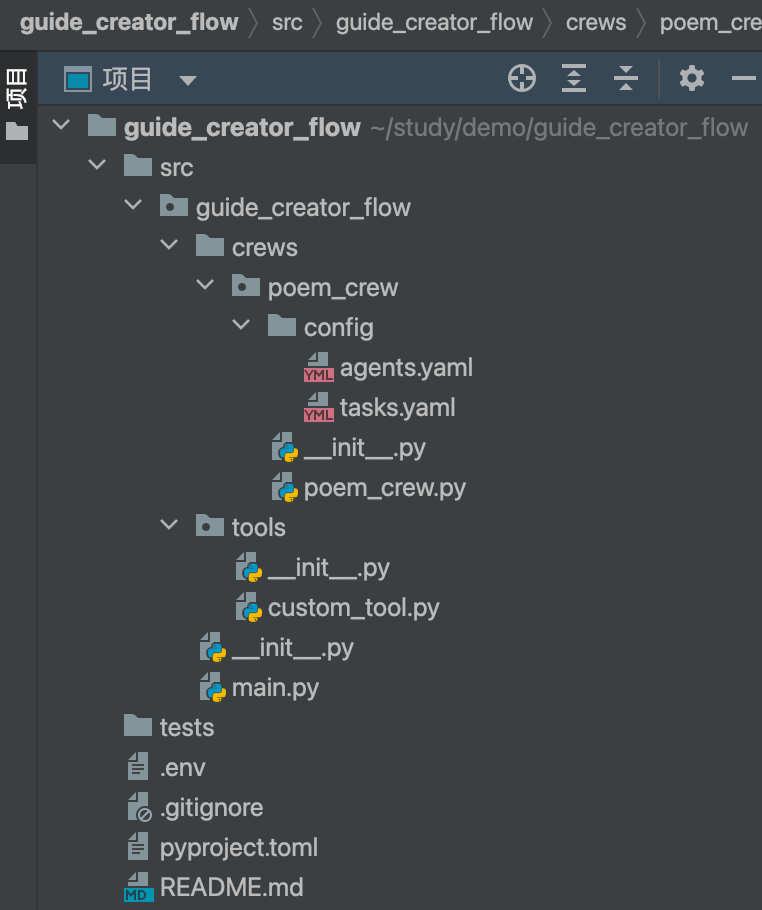
3、项目结构
此结构可以清晰地区分流程的不同组件:
- main.py文件中的主要流程逻辑
- crews目录中的专业团队
- tools目录中的自定义工具
4、添加团队
我们的流程需要专门的团队来处理内容创作过程。让我们使用 CrewAI CLI 添加一个内容创作团队:
crewai flow add-crew content-crew

此命令会自动为您的团队创建必要的目录和模板文件。内容编写团队将负责编写和审核指南的各个部分,并按照我们主应用程序安排的整体流程进行工作。
5、配置代理
# src/guide_creator_flow/crews/content_crew/config/agents.yaml
content_writer:
role: >
教育内容撰稿人 # 代理人的角色名称,用于标识其职责
goal: >
创作引人入胜且信息丰富的内容,能够全面解释分配的主题,
并为读者提供有价值的见解 # 此代理的目标或任务方向
backstory: >
你是一位才华横溢的教育内容撰稿人,擅长创作清晰、生动的内容。
你能够将复杂概念以通俗易懂的语言解释出来,并善于组织信息,
以帮助读者逐步建立理解。 # 背景故事,帮助模型扮演该代理角色时具备相应的“身份”与写作风格
content_reviewer:
role: >
教育内容审稿人与编辑 # 代理人的角色名称
goal: >
确保内容准确、全面、结构良好,并在多个部分之间保持一致性 # 审稿人的目标任务
backstory: >
你是一位严谨的编辑,拥有多年教育内容审校经验。
你擅长发现内容中的细节问题,提升内容的清晰度与连贯性。
你在保持原作者风格的同时,确保各个部分之间的质量和风格统一。 # 背景故事,指导模型如何理解并执行编辑任务
这些代理定义确立了特定角色和视角,这将决定我们的AI代理如何进行内容创作。请注意,每个代理都有其独特的目的和专长。
6、配置任务
更新任务配置文件来定义具体的写作和审阅任务:
# src/guide_creator_flow/crews/content_crew/config/tasks.yaml
write_section_task:
description: >
撰写一个关于主题“{section_title}”的全面章节内容
章节描述:{section_description}
目标读者:{audience_level} 水平的学习者
请确保你的内容符合以下要求:
1. 以简短的引言开始,介绍章节主题
2. 清晰地解释所有关键概念,并提供示例
3. 如适用,请包含实际应用或练习
4. 以关键要点的总结结尾
5. 字数控制在大约 500–800 字之间
使用 Markdown 格式进行排版,包括合适的标题、列表和强调标记。
以下是前面已写的章节:
{previous_sections}
请确保你的内容与先前章节保持一致,并在已有概念基础上进一步延伸。
expected_output: >
一篇结构清晰、内容全面的章节,使用 Markdown 格式,能够充分解释所选主题,并适合目标读者水平。
agent: content_writer # 指派给 content_writer 代理人来执行此任务
review_section_task:
description: >
请审阅并改进以下关于“{section_title}”的章节内容:
{draft_content}
目标读者:{audience_level} 水平的学习者
以下是前面已写的章节:
{previous_sections}
请确保你的审阅工作包括:
1. 修正所有语法或拼写错误
2. 提高内容的清晰度与可读性
3. 确保内容全面且准确
4. 检查与之前章节内容的一致性
5. 优化整体结构与逻辑流畅性
6. 补充缺失的关键信息(如有)
请以 Markdown 格式提供改进后的章节内容。
expected_output: >
一篇改进后的高质量章节内容,保持原始结构不变,
但增强了清晰度、准确性和一致性。
agent: content_reviewer # 指派给 content_reviewer 代理人来执行此任务
context:
- write_section_task # 指定此任务与 write_section_task 有上下文关联,用于提供审阅时的背景信息
这些任务定义向我们的代理提供了详细的指示,确保他们创作的内容符合我们的质量标准。请注意,context审核任务中的参数如何创建一个工作流,让审核人员可以访问作者的成果。
7、配置船员
配置船员实施文件以定义我们的代理和任务如何协同工作:
# 导入 CrewAI 所需的核心模块
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from crewai.agents.agent_builder.base_agent import BaseAgent
from typing import List
# 使用装饰器 @CrewBase 定义一个 Crew 项目类,表示一个内容创作小组
@CrewBase
class ContentCrew():
"""内容创作小组"""
# 定义代理人列表,类型为 BaseAgent 的列表
agents: List[BaseAgent]
# 定义任务列表,类型为 Task 的列表
tasks: List[Task]
# 定义内容撰稿代理人
@agent
def content_writer(self) -> Agent:
return Agent(
config=self.agents_config['content_writer'], # 从配置中读取 content_writer 的配置
verbose=True # 启用详细日志输出
)
# 定义内容审稿代理人
@agent
def content_reviewer(self) -> Agent:
return Agent(
config=self.agents_config['content_reviewer'], # 从配置中读取 content_reviewer 的配置
verbose=True # 启用详细日志输出
)
# 定义“撰写章节”任务
@task
def write_section_task(self) -> Task:
return Task(
config=self.tasks_config['write_section_task'] # 从任务配置中获取 write_section_task 的内容
)
# 定义“审阅章节”任务,并设置上下文为写作任务的输出
@task
def review_section_task(self) -> Task:
return Task(
config=self.tasks_config['review_section_task'], # 从任务配置中获取 review_section_task 的内容
context=[self.write_section_task()] # 设置写作任务的输出为该任务的上下文
)
# 定义最终的团队编排方法,将代理人和任务组装为一个 Crew 实例
@crew
def crew(self) -> Crew:
"""创建内容创作团队"""
return Crew(
agents=self.agents, # 使用定义好的代理人列表
tasks=self.tasks, # 使用定义好的任务列表
process=Process.sequential, # 按顺序执行任务(可选值还有 parallel 等)
verbose=True # 启用详细运行日志
)
这个团队定义确立了我们的代理与任务之间的关系,并建立了一个连续的流程:内容撰写者创建草稿,然后审阅者对其进行改进。虽然这个团队可以独立运作,但在我们的流程中,它将作为更大系统的一部分进行协调。
8、创建流程
创建流程来协调整个指南的创建过程。在这里,我们将把常规 Python 代码、直接 LLM 调用以及我们的内容创作团队整合成一个紧密结合的系统。
我们的流程将:
- 获取主题和受众级别的用户输入
- 直接致电法学硕士 (LLM) 以创建结构化的指南大纲
- 使用内容编写团队按顺序处理每个部分
- 将所有内容合并成最终的综合文档
让我们在main.py文件中创建流程:
# 导入标准库模块
import json
import os
from dotenv import load_dotenv
from typing import List, Dict
# 导入 pydantic,用于定义结构化数据模型
from pydantic import BaseModel, Field
# 导入 CrewAI 相关核心类
from crewai import LLM
from crewai.flow.flow import Flow, listen, start
# 导入自定义的内容创作团队定义
from guide_creator_flow.crews.content_crew.content_crew import ContentCrew
load_dotenv()
# -------------------------------
# 定义结构化数据模型
# -------------------------------
class Section(BaseModel):
"""指南的每个章节结构"""
title: str = Field(description="章节标题")
description: str = Field(description="章节需要涵盖的简要描述")
class GuideOutline(BaseModel):
"""整本指南的大纲结构"""
title: str = Field(description="指南标题")
introduction: str = Field(description="对主题的简介")
target_audience: str = Field(description="目标读者描述")
sections: List[Section] = Field(description="指南中各章节的列表")
conclusion: str = Field(description="指南的结语或总结")
# -------------------------------
# 定义流程的状态结构(状态持久化用)
# -------------------------------
class GuideCreatorState(BaseModel):
"""指南创作过程中的状态记录"""
topic: str = "" # 指南主题
audience_level: str = "" # 目标受众水平(beginner/intermediate/advanced)
guide_outline: GuideOutline = None # 整体大纲
sections_content: Dict[str, str] = {} # 各章节的内容(按标题保存)
# -------------------------------
# 定义主流程类 GuideCreatorFlow
# -------------------------------
class GuideCreatorFlow(Flow[GuideCreatorState]):
"""用于创建综合指南的流程"""
@start()
def get_user_input(self):
"""步骤1:获取用户输入的主题和目标受众"""
print("\n=== 创建你的综合指南 ===\n")
# 获取用户输入的主题
# self.state.topic = input("你想创建哪方面的指南?请输入主题:")
self.state.topic="公路车选购指南"
# 获取受众水平并校验合法性
while True:
# audience = input("目标读者是?(beginner/intermediate/advanced):").lower()
audience="advanced"
if audience in ["beginner", "intermediate", "advanced"]:
self.state.audience_level = audience
break
print("请输入 'beginner'、'intermediate' 或 'advanced' 作为受众水平")
print(f"\n即将为 {self.state.audience_level} 水平的读者创建关于「{self.state.topic}」的指南...\n")
return self.state
@listen(get_user_input)
def create_guide_outline(self, state):
"""步骤2:调用大模型生成指南大纲"""
print("正在生成指南大纲...")
# 初始化 LLM,设定返回格式为 GuideOutline 模型
llm = LLM(model="openai/gpt-4o",api_key=os.environ.get("OPENAI_API_KEY"), response_format=GuideOutline)
# 构造提示词,告诉 LLM 创建结构化 JSON 大纲
messages = [
{"role": "system", "content": "你是一个用于输出 JSON 的助手。"},
{"role": "user", "content": f"""
请为 "{state.topic}" 创建一个适合 {state.audience_level} 水平学习者的综合指南大纲。
大纲应包括:
1. 一个吸引人的指南标题
2. 对主题的简要介绍
3. 4-6 个主要章节,每章需有标题和简要说明
4. 一个结语或总结
"""}
]
# 调用大模型
response = llm.call(messages=messages)
# 解析返回的 JSON 数据为字典,再转换为 GuideOutline 对象
outline_dict = json.loads(response)
self.state.guide_outline = GuideOutline(**outline_dict)
# 确保输出目录存在
os.makedirs("output", exist_ok=True)
# 将大纲保存为 JSON 文件
with open("output/guide_outline.json", "w") as f:
json.dump(outline_dict, f, indent=2)
print(f"指南大纲创建完成,共包含 {len(self.state.guide_outline.sections)} 个章节")
return self.state.guide_outline
@listen(create_guide_outline)
def write_and_compile_guide(self, outline):
"""步骤3:撰写所有章节并整合为完整指南"""
print("开始撰写章节并整合为完整指南...")
completed_sections = [] # 记录已完成的章节标题
# 按章节顺序逐一处理,确保上下文连贯
for section in outline.sections:
print(f"正在处理章节:{section.title}")
# 构建上下文:前面章节的内容(便于保持一致性)
previous_sections_text = ""
if completed_sections:
previous_sections_text = "# 已完成章节内容\n\n"
for title in completed_sections:
previous_sections_text += f"## {title}\n\n"
previous_sections_text += self.state.sections_content.get(title, "") + "\n\n"
else:
previous_sections_text = "当前为第一章节,尚无前文。"
# 使用内容团队完成该章节的撰写与审阅
result = ContentCrew().crew().kickoff(inputs={
"section_title": section.title,
"section_description": section.description,
"audience_level": self.state.audience_level,
"previous_sections": previous_sections_text,
"draft_content": "" # 初始为空,由 content_writer 生成,reviewer 审阅
})
# 存储该章节内容
self.state.sections_content[section.title] = result.raw
completed_sections.append(section.title)
print(f"章节已完成:{section.title}")
# 组装最终完整指南内容(Markdown格式)
guide_content = f"# {outline.title}\n\n"
guide_content += f"## Introduction\n\n{outline.introduction}\n\n"
# 添加每一个章节内容
for section in outline.sections:
section_content = self.state.sections_content.get(section.title, "")
guide_content += f"\n\n{section_content}\n\n"
# 添加结语
guide_content += f"## Conclusion\n\n{outline.conclusion}\n\n"
# 保存最终指南到文件
with open("output/complete_guide.md", "w") as f:
f.write(guide_content)
print("\n完整指南已生成,保存在 output/complete_guide.md")
return "指南创建成功"
# -------------------------------
# 启动函数
# -------------------------------
def kickoff():
"""执行整个指南创建流程"""
GuideCreatorFlow().kickoff()
print("\n=== 流程完成 ===")
print("你的综合指南已保存在 output 目录中。")
print("可打开 output/complete_guide.md 查看结果。")
def plot():
"""可视化流程结构图"""
flow = GuideCreatorFlow()
flow.plot("guide_creator_flow")
print("流程结构图已保存为 guide_creator_flow.html")
# 如果作为主程序运行,则执行
if __name__ == "__main__":
kickoff()
# from crewai import LLM
#
# llm = LLM(model="gpt-4o")
# response = llm.call("你好?")
# print(response)
让我们分析一下这个流程中发生的事情:
- 我们为结构化数据定义了 Pydantic 模型,以确保类型安全和清晰的数据表示。
- 我们创建一个状态类来维护流程中不同步骤的数据。
- 我们实现了三个主要的流程步骤:
- 使用 @start() 装饰器获取用户输入
- 通过直接 LLM 调用创建指南大纲
- 与内容团队一起处理各个部分
- 我们使用 @listen() 装饰器在步骤之间建立事件驱动的关系。
这就是流程的强大之处——将不同类型的处理(用户交互、直接 LLM 调用、基于团队的任务)组合成一个连贯的事件驱动系统。
9、设置环境变量
使用您的 API 密钥在项目根目录下创建一个 .env 文件。有关配置提供程序的详细信息,请参阅 前面博文。
OPENAI_API_KEY=your_openai_api_key
# or
GEMINI_API_KEY=your_gemini_api_key
# or
ANTHROPIC_API_KEY=your_anthropic_api_key
10、安装依赖项
初始化安装所需的依赖项:
crewai install
11、运行流程
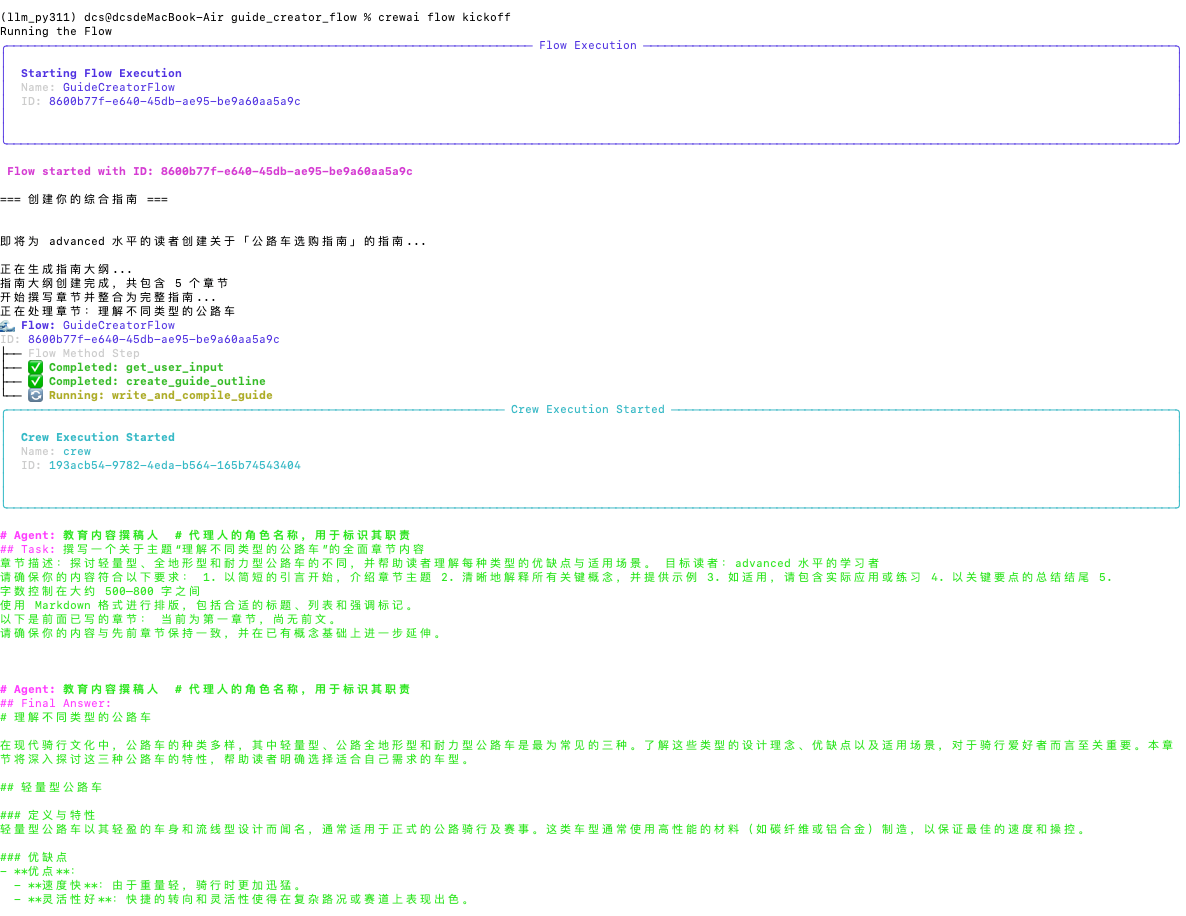
现在是时候看看您的流程的实际效果了!使用 CrewAI CLI 运行它:
crewai flow kickoff
运行此命令后,您将看到流程开始运行:
- 它会提示您输入主题和受众级别
- 它会为您的指南创建一个结构化的大纲
- 它会处理每个部分,内容撰写者和审核者会在每个部分进行协作
- 最后,它会将所有内容汇编成一份综合指南
这展示了流程在协调涉及多个 AI 和非 AI 组件的复杂流程方面的强大功能。

输出完成

12、可视化您的流程
流程的强大功能之一是能够可视化其结构:
crewai flow plot
这将创建一个 HTML 文件,显示流程的结构,包括不同步骤之间的关系以及它们之间流动的数据。这种可视化对于理解和调试复杂流程非常有帮助。
打开输出的html页面,查看流程
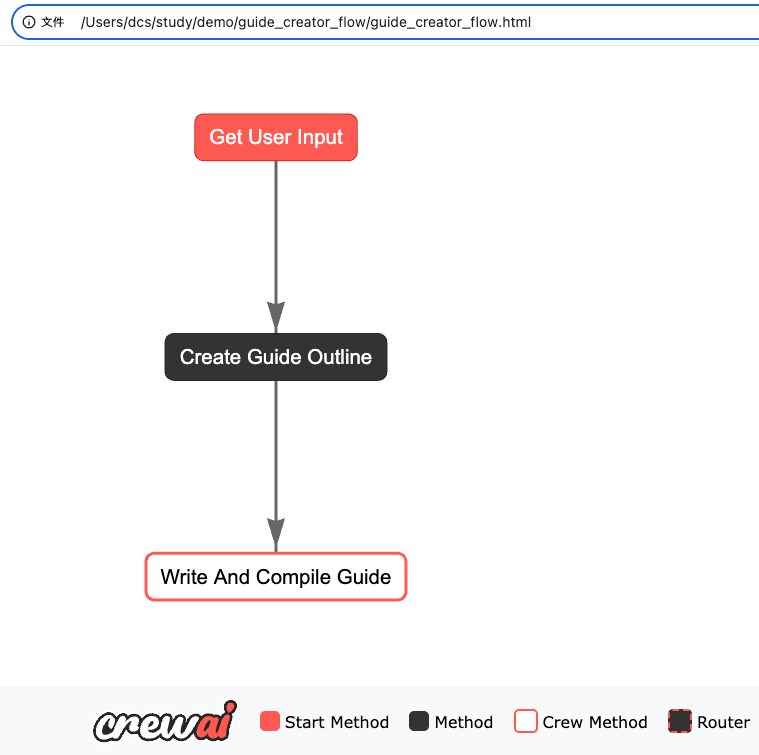
13、查看输出
流程完成后,您会在输出目录中找到两个文件:
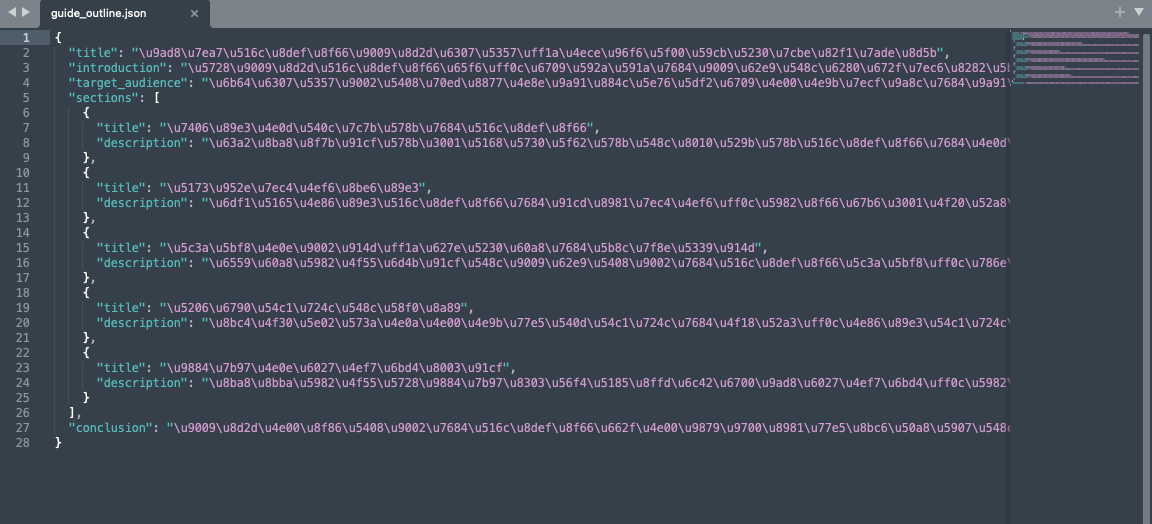
- guide_outline.json:包含指南的结构化大纲
- complete_guide.md:包含所有章节的综合指南
花点时间查看这些文件,并欣赏您所构建的成果,一个结合用户输入、直接 AI 交互和协作代理工作,从而生成复杂且高质量输出的系统。
guide_outline.json预览
complete_guide.md 最终文档预览

14、本教程特点
本指南创建流程展示了 CrewAI 的几个强大功能:
- 用户交互:流程直接从用户收集输入
- 直接 LLM 调用:使用 LLM 类进行高效、单一用途的 AI 交互
- 使用 Pydantic 的结构化数据:使用 Pydantic 模型来确保类型安全
- 带上下文的顺序处理:按顺序写入部分,并提供前面的部分作为上下文
- 多代理团队:利用专门的代理(作者和审阅者)进行内容创作
- 状态管理:维护流程不同步骤的状态
- 事件驱动架构:使用@listen装饰器来响应事件


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









