










标记是指用以下类别标记文档:
- 情感
- 语言
- 风格(正式、非正式等)
- 涵盖的主题
- 政治倾向
概述
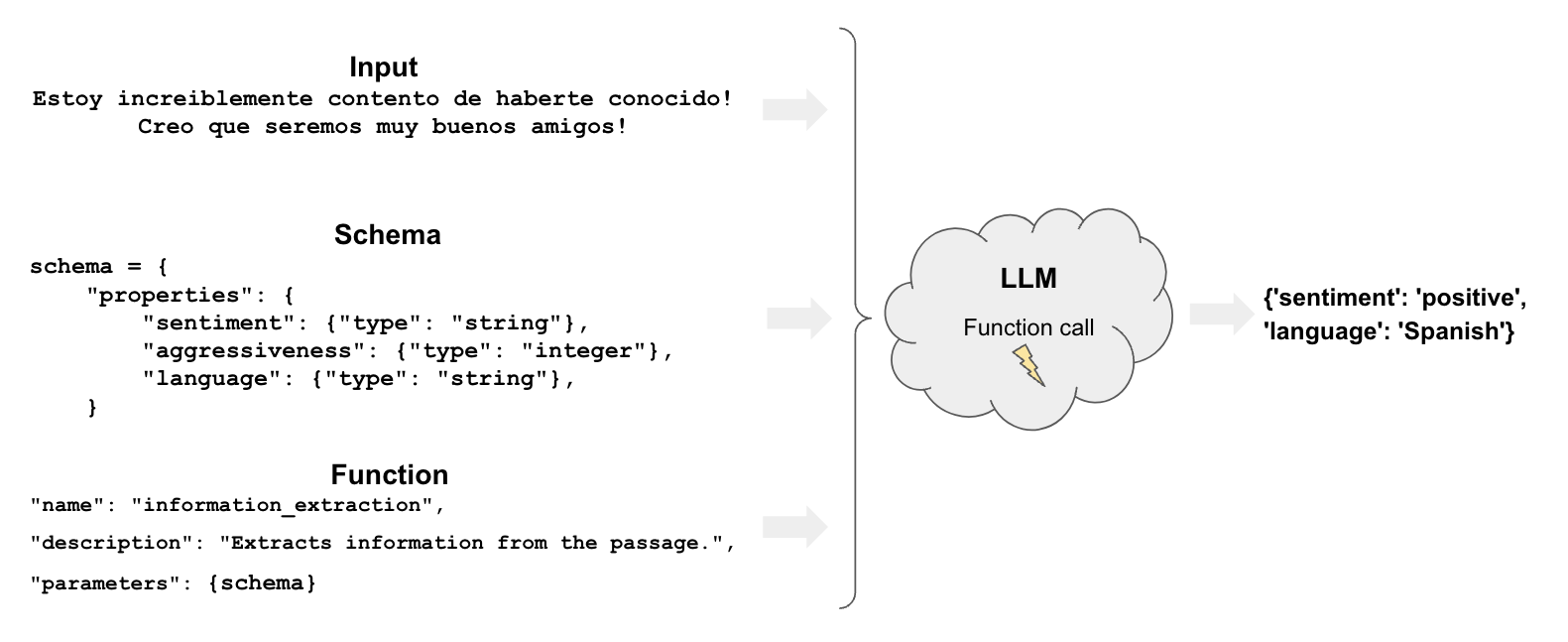
标记有几个组成部分:
- function:与提取一样,标记使用函数来指定模型应如何标记文档
- schema:定义我们想要如何标记文档
import os
from dotenv import load_dotenv
load_dotenv()
True
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
1、快速入门
让我们在 schema 中指定一个具有一些属性及其预期类型的 Pydantic 模型。
from langchain_core.prompts import ChatPromptTemplate # 用于创建提示模板
from langchain_openai import ChatOpenAI # 用于与 OpenAI 聊天模型交互
from pydantic import BaseModel, Field # 用于定义结构化数据模型
# 创建一个提示模板,指导语言模型从文本中提取结构化信息
tagging_prompt = ChatPromptTemplate.from_template(
"""
从以下段落中提取所需信息。
仅提取“分类”函数中提到的属性。
输出为中文。
段落:
{input}
"""
)
# 定义一个用于结构化输出的 Pydantic 模型
class Classification(BaseModel):
# 文本的情感,例如 “正面”、“中性”、“负面”
sentiment: str = Field(description="文本的情感")
# 文本的攻击性程度,从 1 到 10 的整数,1 表示不攻击,10 表示极端攻击
aggressiveness: int = Field(
description="文字的攻击性程度(1 到 10 分)"
)
# 文本所用语言,例如 "English", "Chinese"
language: str = Field(description="文本所用的语言")
# 使用结构化输出功能,将 LLM 的输出格式化为 Classification 模型
# 假设 llm 是你已初始化好的 ChatOpenAI 实例
structured_llm = llm.with_structured_output(Classification)
# 要处理的文本输入,中文语句子,表达积极的情绪
inp = "我非常高兴认识你!我觉得我们会成为非常好的朋友!"
# 使用提示模板将原始输入格式化为结构化提问 prompt
# 即将 'inp' 的内容填入 tagging_prompt 中的 {input} 占位符
prompt = tagging_prompt.invoke({"input": inp})
# 使用结构化语言模型处理 prompt,并将其输出映射为 Classification 数据模型
response = structured_llm.invoke(prompt)
# 输出结构化响应结果,包括情感、攻击性程度和语言
response
Classification(sentiment='积极', aggressiveness=1, language='中文')
# 英文内容:你真是一无是处,你做的每件事都只会让事情变得更糟!
inp = "You’re completely useless, and everything you do just makes things worse!"
prompt = tagging_prompt.invoke({"input": inp})
response = structured_llm.invoke(prompt)
# 输出结构化响应结果,包括情感、攻击性程度和语言
response
Classification(sentiment='负面', aggressiveness=9, language='英语')
# 如果我们想要字典输出,我们只需调用.model_dump()
response.model_dump()
{'sentiment': '负面', 'aggressiveness': 9, 'language': '英语'}
2、精细化输出
精细的模式定义使我们能够更好地控制模型的输出。
具体来说,我们可以定义:
- 每个属性的可能值
- 属性描述,以确保模型能够理解该属性
- 需要返回的属性
让我们重新声明我们的 Pydantic 模型,使用枚举来控制前面提到的每个方面:
# 定义一个用于结构化输出的 Pydantic 模型,用于文本分类任务
class Classification(BaseModel):
# 文本的情感(sentiment),必须是以下三种值之一:
# "happy":积极情绪
# "neutral":中性情绪
# "sad":消极情绪
sentiment: str = Field(
..., # 表示这是一个必填字段
enum=["happy", "neutral", "sad"] # 限定只能是这三种之一
)
# 攻击性等级(aggressiveness),必须是 1 到 5 之间的整数:
# 1 表示最不具有攻击性,5 表示非常具有攻击性
aggressiveness: int = Field(
..., # 必填字段
description="描述言论的攻击性,数字越高,攻击性越强", # 字段描述
enum=[1, 2, 3, 4, 5] # 限定只能是这五个值之一
)
# 文本的语言(language),必须是以下六种语言之一:
# "spanish"(西班牙语)、"english"(英语)、"french"(法语)、
# "german"(德语)、"italian"(意大利语)、"chinese"(中文)
language: str = Field(
..., # 必填字段
enum=["spanish", "english", "french", "german", "italian", "chinese"]
)
tagging_prompt = ChatPromptTemplate.from_template(
"""
从以下段落中提取所需信息。
仅提取“分类”函数中提到的属性。
段落:
{input}
"""
)
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini").with_structured_output(
Classification
)
# 现在,答案将以我们预期的方式受到限制!
inp = "You’re completely useless, and everything you do just makes things worse!"
prompt = tagging_prompt.invoke({"input": inp})
llm.invoke(prompt)
Classification(sentiment='sad', aggressiveness=5, language='english')
inp = "我非常高兴认识你!我觉得我们会成为非常好的朋友!"
prompt = tagging_prompt.invoke({"input": inp})
response =llm.invoke(prompt)
# 如果我们想要字典输出,我们只需调用.model_dump()
response.model_dump()
{'sentiment': 'happy', 'aggressiveness': 1, 'language': 'chinese'}
3、扩展:结构化输出
概述
对于许多应用程序,例如聊天机器人,模型需要直接以自然语言响应用户。 但是,在某些情况下,我们需要模型以结构化格式输出。 例如,我们可能希望将模型输出存储在数据库中,并确保输出符合数据库架构。 这种需求激发了结构化输出的概念,其中可以指示模型使用特定的输出结构进行响应。
关键概念
- 1、Schema 定义:输出结构表示为 Schema,可以通过多种方式定义。
- 2、返回结构化输出:为模型提供此架构,并指示返回符合该架构的输出。
推荐用法
此伪代码说明了使用结构化输出时建议的工作流程。 LangChain 提供了一个方法 with_structured_output(),用于自动执行将 Schema 绑定到模型并解析输出的过程。 此帮助程序函数可用于支持结构化输出的所有模型提供程序。
# 定义一个模式(schema),用于指定结构化输出的字段及其类型或占位符
schema = {"foo": "bar"} # 这里表示我们期望输出是一个包含键 "foo" 的字典,其值的格式示意为 "bar"
# 将定义好的结构模式绑定到模型上,使模型输出遵循该结构
model_with_structure = model.with_structured_output(schema)
# 使用绑定了结构输出的模型进行调用,输入是用户提供的内容
# 模型将根据 schema 生成一个结构化的输出(例如字典)
structured_output = model_with_structure.invoke(user_input)
Schema 定义
中心概念是模型响应的输出结构需要以某种方式表示。 虽然您可以使用的对象类型取决于您正在使用的模型,但在 Python 中,通常允许或推荐用于结构化输出的常见对象类型。
结构化输出的最简单和最常见的格式是类似 JSON 的结构,在 Python 中可以表示为字典 (dict) 或列表 (list)。 当工具需要原始、灵活且开销最小的结构化数据时,通常会直接使用 JSON 对象(或 Python 中的字典)。
{
"answer": "The answer to the user's question",
"followup_question": "A followup question the user could ask"
}
{'answer': "The answer to the user's question",
'followup_question': 'A followup question the user could ask'}
作为第二个示例,Pydantic 对于定义结构化输出模式特别有用,因为它提供了类型提示和验证。 下面是一个 Pydantic 架构的示例:
from pydantic import BaseModel, Field
# 定义一个结构化响应的数据模型,继承自 BaseModel
class ResponseFormatter(BaseModel):
"""始终使用此工具将响应结构化,以便统一和可验证的输出格式。"""
# 定义一个字段 'answer',用于存放对用户问题的回答
answer: str = Field(
description="对用户问题的回答" # 给出字段的描述,帮助理解字段含义,可用于自动文档生成等用途
)
# 定义一个字段 'followup_question',用于提供用户可能接着问的后续问题
followup_question: str = Field(
description="用户接下来可能会问的一个相关问题" # 这有助于引导用户继续探索相关主题
)
返回结构化输出
定义 schema 后,我们需要一种方法来指示模型使用它。 虽然一种方法是在提示中包含此架构并友好地请求模型使用它,但不建议这样做。 有几种更强大的方法可用于利用模型提供程序的 API 中的本机功能。
使用工具调用
许多模型提供商都支持工具调用,我们的工具调用指南中更详细地讨论了这一概念。
简而言之,工具调用涉及将工具绑定到模型,在适当的时候,模型可以决定调用此工具并确保其响应符合工具的架构。
考虑到这一点,中心概念很简单:只需将我们的 schema 绑定到一个模型作为工具!以下是使用上面定义的架构的示例:ResponseFormatter
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 将响应格式化程序模式作为工具绑定到模型
model_with_tools = model.bind_tools([ResponseFormatter])
ai_msg = model_with_tools.invoke("细胞的动力工厂是什么?")
# 获取工具调用参数
ai_msg.tool_calls[0]["args"]
{'answer': '细胞的动力工厂是指线粒体。线粒体是细胞内的细胞器,负责产生能量,主要通过氧化磷酸化过程将营养物质转化为ATP(腺苷三磷酸),为细胞提供能量。线粒体被称为细胞的动力工厂,因为它们是细胞能量代谢的中心。',
'followup_question': '线粒体的功能有哪些?'}
# 将字典解析为 pydantic 对象
pydantic_object = ResponseFormatter.model_validate(ai_msg.tool_calls[0]["args"])
pydantic_object
ResponseFormatter(answer='细胞的动力工厂是指线粒体。线粒体是细胞内的细胞器,负责产生能量,主要通过氧化磷酸化过程将营养物质转化为ATP(腺苷三磷酸),为细胞提供能量。线粒体被称为细胞的动力工厂,因为它们是细胞能量代谢的中心。', followup_question='线粒体的功能有哪些?')
JSON 模式
除了工具调用之外,一些模型提供商还支持名为的功能。该功能支持 JSON 模式定义作为输入,并强制模型生成符合规范的 JSON 输出。您可以在此处找到支持 JSON 模式的模型提供商表格。以下是如何在 OpenAI:JSON 模式下使用 JSON 模式的示例
model = ChatOpenAI(model="gpt-4o-mini").with_structured_output(method="json_mode")
ai_msg = model.invoke("返回一个 JSON 对象,其键为“random_ints”,值为 [0-99] 范围内的 10 个随机整数")
ai_msg
{'random_ints': [34, 87, 2, 56, 73, 19, 41, 90, 5, 61]}
结构化输出方法
使用上述方法生成结构化输出时面临一些挑战:
- (1) 使用工具调用时,需要将工具调用参数从字典解析回原始模式。
- (2) 此外,当我们想要强制执行结构化输出时,需要指示模型始终使用该工具,这是特定于提供程序的设置。
- (3) 使用 JSON 模式时,需要将输出解析为 JSON 对象。
考虑到这些挑战,LangChain 提供了一个辅助函数 () 来简化流程。with_structured_output()
这既将架构绑定到作为工具的模型,又将输出解析为指定的输出架构。
model = ChatOpenAI(model="gpt-4o-mini")
# 将之前定义的 ResponseFormatter 数据模型绑定到模型上,
# 这样模型输出将自动转换为符合该 Pydantic 模型格式的结构化对象
model_with_structure = model.with_structured_output(ResponseFormatter)
# 调用绑定了结构化输出的模型,传入一个用户问题作为输入
# 例如:细胞的动力工厂是什么?
structured_output = model_with_structure.invoke("细胞的动力工厂是什么?")
# 输出结构化结果,类型为 ResponseFormatter 的 Pydantic 对象
# 可以像访问属性一样访问结构化数据,例如 structured_output.answer
structured_output
ResponseFormatter(answer='细胞的动力工厂是指线粒体。线粒体是细胞中的一种细胞器,负责产生细胞所需的能量(ATP)。它们通过一种叫做细胞呼吸的过程,将食物中的化学能转化为ATP,从而为细胞提供动力,支持细胞的各种生命活动。', followup_question='线粒体的结构和功能有哪些特点?')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









