




 本文介绍如何使用Python爬虫技术抓取优快云上的技术博客文章,包括分析网页结构、使用正则表达式提取文章内容,并将数据保存至本地硬盘,便于离线学习。
本文介绍如何使用Python爬虫技术抓取优快云上的技术博客文章,包括分析网页结构、使用正则表达式提取文章内容,并将数据保存至本地硬盘,便于离线学习。
本篇文章的内容是如何用Python爬虫获取那些价值博文,现在分享给大家,有需要的朋友可以参考一下这篇文章地的内容
在优快云上有很多精彩的技术博客文章,我们可以把它爬取下来,保存在本地磁盘,可以很方便以后阅读和学习,现在我们就用python编写一段爬虫代码,来实现这个目的。
我们想要做的事情:自动读取博客文章,记录标题,把心仪的文章保存到个人电脑硬盘里供以后学习参考。
过程大体分为以下几步:
- 找到爬取的目标网址;
- 分析网页,找到自已想要保存的信息,这里我们主要保存是博客的文章内容;
- 清洗整理爬取下来的信息,保存在本地磁盘。
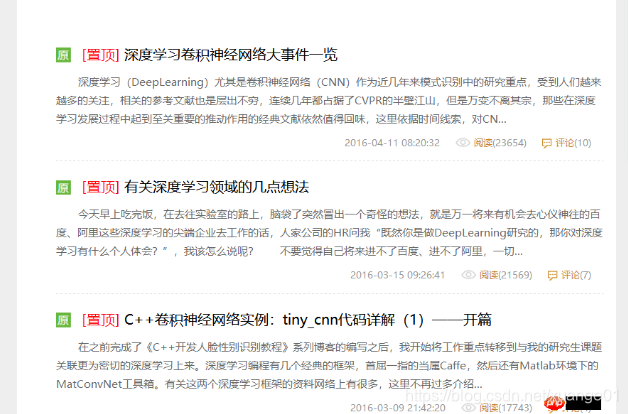
打开csdn的网页,作为一个示例,我们随机打开一个网页:
http://blog.youkuaiyun.com/u013088062/article/list/1。
可以看到,博主对《C++卷积神经网络》和其它有关机计算机方面的文章都写得不错。
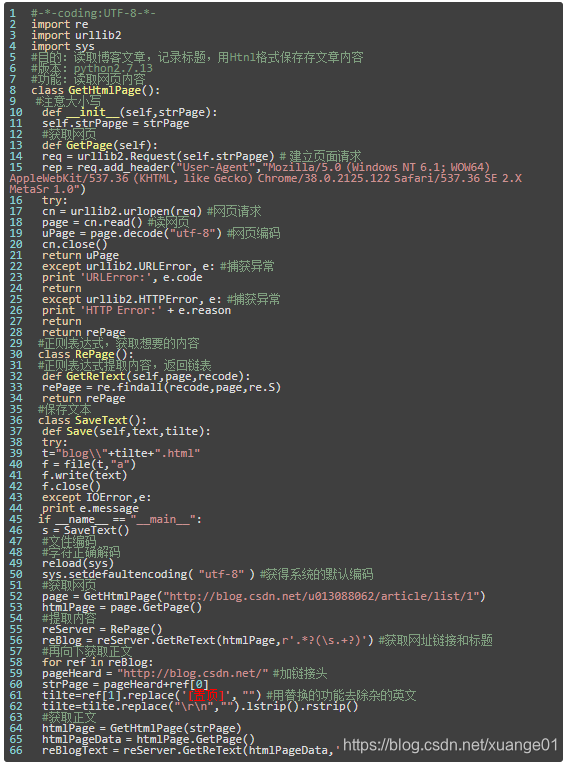
爬虫代码按思路分为三个类(class),下面3个带“#”的分别给出了每一个类的开头(具体代码附后,供大家实际运行实现):

采用“类(class)”的方式属于Python的面向对象编程,在某些时候比我们通常使用的面向过程的编程方便,在大型工程中经常使用面向对象编程。对于初学者来说,面向对象编程不易掌握,但是经过学习习惯之后,会逐步慢慢从面向过程到面向对象编程过渡。
特别注意的是,RePage类主要用正则表达式处理从网页中获取的信息,正则表达式设置字符串样式如下:

用正则表达式去匹配所要爬取的内容,用Python和其它软件工具都可以实现。正则表达式有许多规则,各个软件使用起来大同小异。用好正则表达式是爬虫和文本挖掘的一个重要内容。
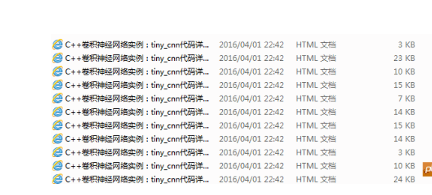
SaveText类则是把信息保存在本地,效果如下:
用python编写爬虫代码,简洁高效。这篇文章仅从爬虫最基本的用法做了讲解,有兴趣的朋友可以下载代码看看,希望大家从中有收获。
附相关Python代码:


















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









