









 本文介绍ICLR2019最佳论文《通过L0正则化学习稀疏神经网络》。阐述了神经网络剪枝的三种方法,指出修剪可降低计算成本、提高泛化能力。采用L_0正则化解决修剪问题,将不可微的L_0范数转化为可微形式。结果显示该方法在MNIST和CIFAR数据集上有优势。
本文介绍ICLR2019最佳论文《通过L0正则化学习稀疏神经网络》。阐述了神经网络剪枝的三种方法,指出修剪可降低计算成本、提高泛化能力。采用L_0正则化解决修剪问题,将不可微的L_0范数转化为可微形式。结果显示该方法在MNIST和CIFAR数据集上有优势。
本篇是ICLR2019的两篇Best Paper之一。另一篇:ORDERED NEURONS: INTEGRATING TREE STRUCTURES INTO RECURRENT NEURAL NETWORKS
LEARNING SPARSE NEURAL NETWORKS THROUGH L0 REGULARIZATION
《通过L0正则化学习稀疏神经网络》
作者与机构:
-
Christos Louizos*
University of Amsterdam TNO. Intelligent Imaging -
Max Welling
University of Amsterdam CIFAR -
Diederik P. Kingma
OpenAl
论文地址:https://openreview.net/forum?id=rJl-b3RcF7
引言
剪枝(pruning),是指减少或控制非零参数的数量,或者在神经网络中使用很多特征映射。在高维中,至少有三种方法可以做到这一点,而剪枝就是其中之一:
正则化(regularization):修改目标函数/学习问题,所以优化后可能会得到一个参数较少的神经网络。参见 Louizos et al, (2018)
修剪(pruning):面向大规模神经网络,并删除某些意义上冗余的特征或参数。参见 (Theis et al, 2018)
增长(growing):虽然这一方法传播得不够广泛,但是也可以采取这第三种方法,从小型网络开始,按某种增长标准逐步增加新的单元。参见「学界 | 为数据集自动生成神经网络:普林斯顿大学提出 NeST」
问题
-
修剪能在保持相同性能的前提下降低计算成本。
删除那些在深度网络结构中不真正使用的特征可以加速推断和训练的过程。也可以认为,修剪是一种架构搜索的形式:找出每层需要多少特征才能获取最佳性能。 -
通过减少参数数量可以减少参数空间的冗余,从而提高泛化能力。
-
对优化问题作出一些推进
解决方式
L_0 正则化
在训练期间通过鼓励权重变为零来修剪网络
解决L_0 正则化引入使损失函数中无法求导的因题,将不可微的L_0范数转化为可微的方式,从而解决该问题
-
从可能难以优化的理想损失函数入手:通常训练损失加上参数的 L_0 范数,进行线性组合。L_0 范数简单地计算向量中的非零项,是一个不可微的分段常值函数。这是一个困难的组合优化问题。
-
应用变分优化将不可微函数变成可微函数。这通常需要引入关于参数 θ 的概率分布 p_ψ(θ)。即使目标函数对任何 θ 都不可微,平均损失函数 p_ψ 也可能关于 ψ 可微。为了找到最优的 ψ,通常可以使用强化梯度估计,这也就导致了进化策略的应用。但是,进化策略一般方差很高,因此我们需要进行下一步。
-
对 p_ψ 应用参数重设技巧构建一个低方差梯度估计器。但是,这只适用于连续变量。为了处理离散变量,我们需要执行第 4 步。
-
应用 concrete relaxation,通过连续近似的方法逼近离散随机变量。现在,我们就有了一个低方差梯度估计器(相比于强化梯度估计而言),可以通过反向传播和简单的蒙特卡罗采样进行计算。你可以将这些梯度用于 SGD(Adam),这也就是论文中所做的工作。
结果
这的确能起作用,并且与其他用于减少参数数量的方法相比更具优势。
MNIST 数据集
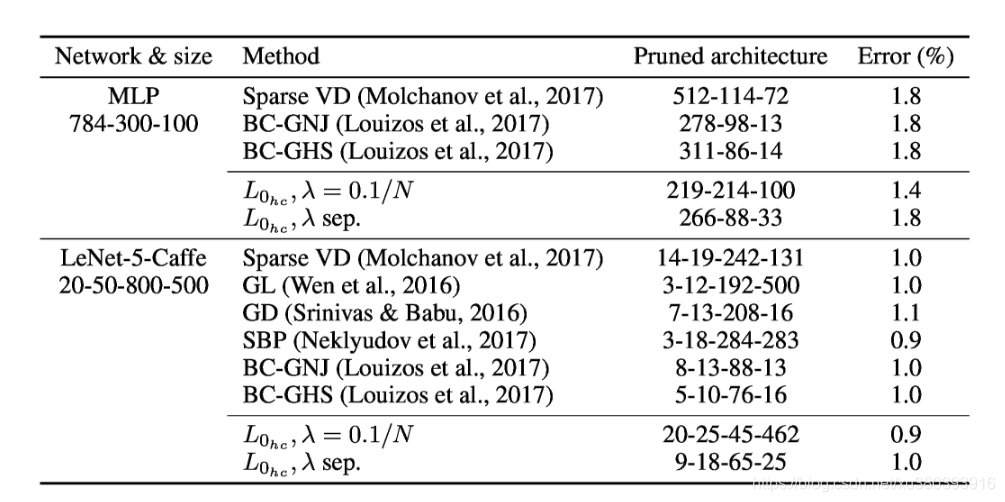
- 分析
我们可以进一步看到,我们的方法在门影响较大部分成本的层上更多地减少了参数的数量;对于MLP,这对应于输入层,而对于LeNet5,这对应于第一个完全连接的层。相比之下,稀疏诱导先验的方法(Louizos等,2017; Neklyudov等,2017)使参数稀疏化,而不考虑额外的成本(因为它们仅受到先前的参数移动到零的鼓励),因此它们在所有层上实现了类似的稀疏性。尽管如此,应该提到的是,我们原则上可以简单地通过为每个层指定单独的λ来增加特定层上的稀疏性,例如,通过增加影响较少参数的门的λ。我们在“λsep。”行提供这样的结果。
CIFAR数据集

参考资料
Ferenc Huszár:剪枝神经网络两篇最新论文的解读 - 知乎
https://zhuanlan.zhihu.com/p/34238197
最新论文解读 | 神经网络“剪枝”的两个方法
https://blog.youkuaiyun.com/dqcfkyqdxym3f8rb0/article/details/79338899
深度 | 论文解读:神经网络修剪最新研究进展
http://itech.ifeng.com/yidian/44883041/news.shtml?ch=ref_zbs_ydzx_news&yidian_docid=0IO2jqeX
Pruning Neural Networks: Two Recent Papers
https://www.inference.vc/pruning-neural-networks-two-recent-papers/?from=hackcv
透彻理解神经网络剪枝算法
https://blog.youkuaiyun.com/baidu_15238925/article/details/81291209

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









