



你最近提审iOS APP是否最近遇到了4.3 a ? 还在分析判断是否是机审打回还是人工打回?
答案: 这一切都源于机审
这篇文章对你来说可能非常重要, 记得收藏回家慢慢看,有问题直接联系我
我们来根据审核时长分析几种情况:
1: 你的APP审核不到十分钟被打回 4.3 a
审核时长极短, 基本可以认为是机审直接打回, 但也不完全确定, (因为遇到有十分钟打回并附有截图, 这种带截图的可以断定是人工.不过这种情况较少,比较特殊), 十分钟被打回这种情况, 说明了一个问题, 你的代码重复率惊人, 不需要人工断定, 凭靠机审完全可以判定.
2: 你的App审核 时长在1-2 小时被打回4.3 a ,
不长不短, 到了人工确认环节, 不需要话费太长时间确认, 就可以断定相似度, 说明你的代码相似度并不低, 通过机审能找到相似的App, 人工进行UI 对比, 那么通过简单的视觉观察, 就能断定你是一个混淆处理再上架app, 或者可以说是一个马甲包
3: 你的app审核时长在3-5个小时,
审核时间略长, 你的代码重复率较低, 但是仍有较多可疑之处, 依旧需要人工断定, 人工通过肉眼观察UI, 不能直观的对比出来是否相似, 需要更深入的从功能等各个角度分析, 需要更长的时间来确认是否达到4.3 标准
4: 你的app审核长达7-10个小时, 甚至更长都没有给出结果
审核时间完全超时, 你的APP 进入了深入调查环节, 你的APP有重大违反开发者条例的嫌疑. 但是仍有审核十几个小时依然能通过审核的情况, 这个时候需要你自查app,是否有严重违反开发者条例的行为.如果没有请耐心等待, 如果有,请迅速撤回审核, 改正, 重新提审. 作者遇到审核时长偶尔超过十个小时, 取消 重提, 三分钟封号的情况 , 被苹果查出重大违规.
以上是根据审核时长做一个简单的判断, 通过审核时长往往能判断出你的代码问题大小, 往往被拒的越快, 说明你的代码问题越大 , 没有十足把握尽量不要轻易尝试提审, 目前账号出现4.3的次数越多, 审核越严格, 如果超过4-5次, 你可能会有封号的风险. 屡教不改, 不给你机会了.
下面我们来分析机审
为什么要执着的分析机审呢, 了解了机审的审核机制, 你才知道你的代码修改的方向
很多开发者遇到4.3 就是到处寻找混淆工具, 经过了七七四十九到工序和乱七八糟的操作之后, 信心满满提取提审 , 依然4.3打回 .
我们进入正题 : 苹果拿到你的ipa 第一步做什么?
会不会把你的ipa 直接反编译成源码 ?
1: 完全不会, 因为可执行文件是不可逆的 , 那么你可能会有疑惑 , 你认为不能不代表苹果不能
受编译优化和元数据丢失影响,在源代码编译成可执行文件的时候丢弃很多数据, 无法完全还原 不过他们可以把你的可执行文件反编译成伪代码, 这对他们来说是易如反掌的
会不会把你的可执行文件反编译成为伪代码?
1: 也不会, 因为这会花费太多的时间, 性价比不高, 而且反编译直接涉及侵犯开发者知识产权问题
会不会把你的ipa直接存入数据库?
全完不会, ipa体积大小不一, 小的几兆,大的几百兆, 如果全部存入数据库, 这将是一个非常庞大的存贮量, 无论在存储还是对比 都造成了巨大的难度和压力值
重点来了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
苹果必然在你提交了ipa之后, 提取ipa 特征信息, 于一个轻量级的文件中,比如可能是一个txt文件 ,然后存入数据库, 因为这种方案在存储和对比两个方面来讲将会游刃有余, 无论你的app迭代了多个版本, 产生了多少个版本的特征, 全部存储毫无压力.
那么他也许是这种方式存储的
// 示例:feature_manifest.json(实际会更复杂)
{
"binary_fingerprint": {
"entropy": 7.82, // 二进制熵值
"section_hashes": {
"__text": "a1b2c3...", // 代码段哈希
"__data": "d4e5f6..." // 数据段哈希
}
},
"code_flow_signatures": [
{
"method": "0x1A2B3C", // 混淆后的方法地址
"cfg_hash": "x8y9z0", // 控制流图哈希
"opcode_sequence": ["mov", "call", "ret"] // 指令序列
}
],
"resource_fingerprints": [
{
"file": "Assets/texture.png",
"crc32": "0x12345678",
"metadata": {"width": 1024, "height": 768}
}
],
"api_call_graph": {
"nodes": ["UIKit", "ARKit", "StoreKit"],
"edges": ["UIKit→ARKit", "ARKit→StoreKit"]
}
}
对比文本的速度是惊人的, 可能一秒钟对比几万个app甚至几十万, 那么机审在十分钟左右出结果也就顺理成章了. 当然不一定是txt文件, 有可能是 .pb 或者.parquet 文件. 因为他们比txt文件 具有更小的体积, 更快的读写速度, 和检索效率
了解了以上内容有什么用呢? 会对你的上架有帮助吗
非常有用, 知道了苹果提取和对比的大致流程后, 我们继续分析
苹果可能会一次性提取ipa里面的所有特征, 存入数据库, 那么问题来了
ipa里面除了又可执行文件, 资源文件, 还有动态库, 我们知道可行文件内部大多都是开发者编写的源代码, 是必然要提取的, 资源文件也是开发者设计的一些图片,音乐,等, 这些也是必须提取,作为日后对比的重要数据, 那么动态库部分,苹果会不会提取然后作对比?
这里有两个非常重要的猜测:
1: 会提取,也会对比,但是相对于可执行文件侧重比可能较低
2: 会提取,但不会对比, 苹果可能有白名单策略, 很简单,过滤一些常用的三方库.
我们并非瞎猜, 请看苹果申请的专利

我们来看专利的细节部分

那么问题来了, 我们是否可以将源代码伪装成通用动态库? 蒙混过关?
苹果比你聪明的多,判断这个难不倒苹果
近年来由于开发者不断对混淆的深入和试探, 测试, 逐渐找到混淆过审的方式, 苹果也针对这种情况不断的做出调整, 对抗开发者混淆.
你应该也会发现, 你过去的混淆方式失效了, 你的混淆工具混淆了之后还是会4.3
那么其实大部分混淆工具, 都脱离不了那几样, 改变类名,方法名,属性名, 添加垃圾文件
苹果的相似度检测技术应该做了一些创新, 完全脱离这些名称依然能够断定相似度,那么我会在下一篇文章介绍
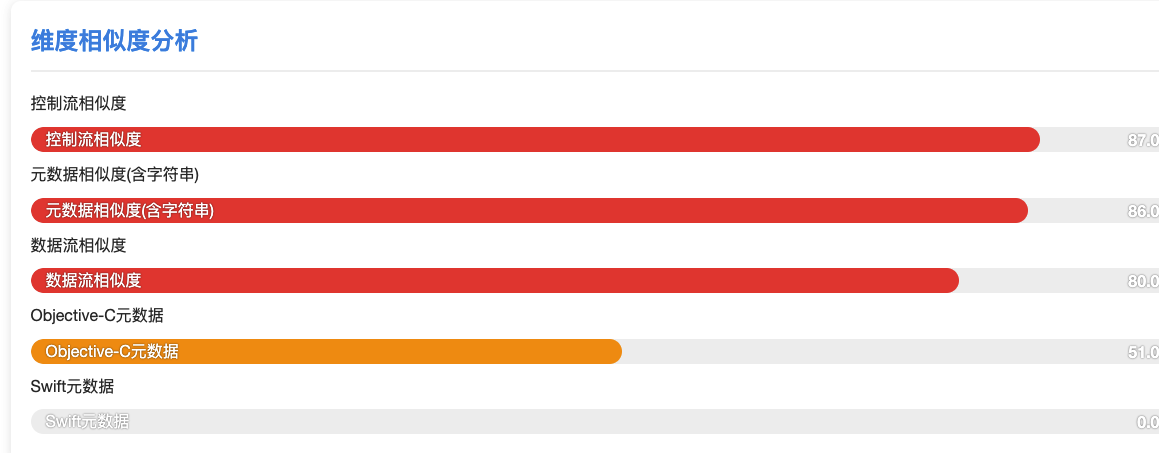
下面给大家预览一下我们的相似度对比技术, 这是一个混淆了类名,方法名,属性名的 二进制和原来的二进制文件对比报告,
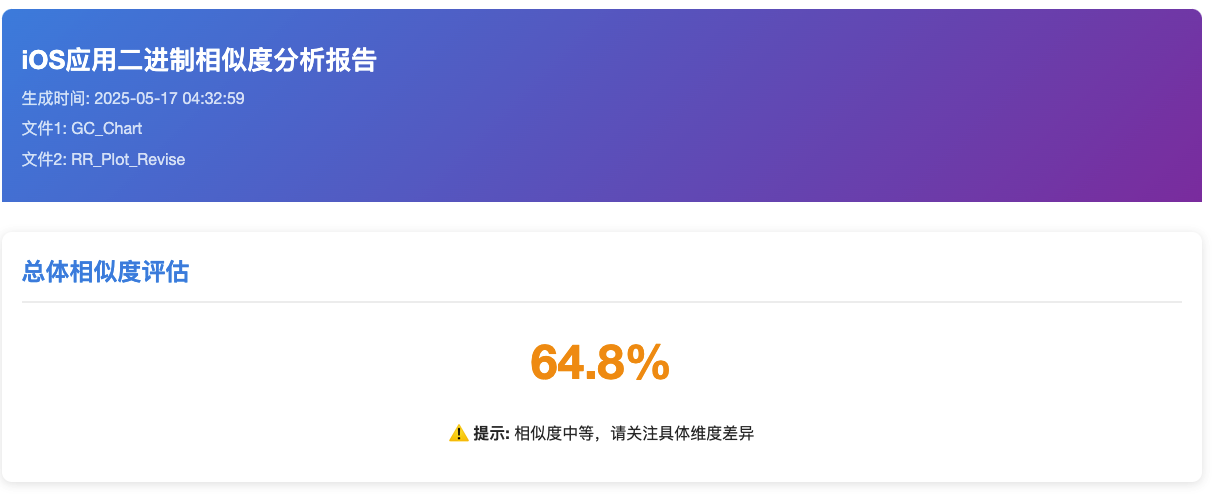
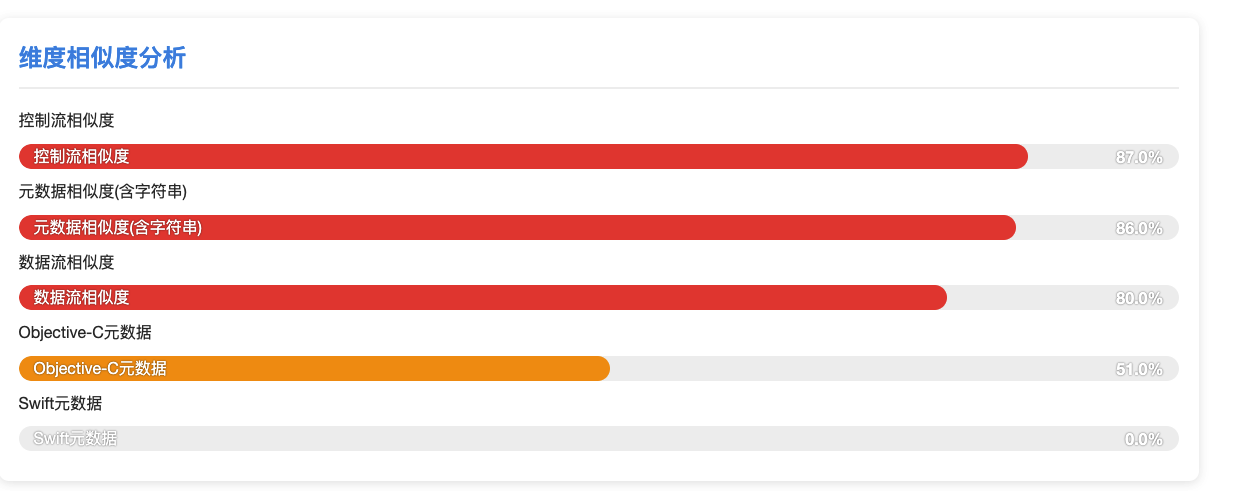
解决4.3就找我
如果你想找到我, 你就会很容易的找到我
如果你相信我, 我就能给你惊喜

















 6214
6214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









