







1 一个简单的c++与cuda编程示例
1.1 目录结构
1.2 CMakeLists.txt
cmake_minimum_required(VERSION 3.8)
project(cuda_demo VERSION 0.1)
# Find CUDA
find_package(CUDA REQUIRED)
# Add executable with source files
CUDA_ADD_EXECUTABLE(cuda_demo
src/main.cpp
src/cuda_test.cu
)
target_include_directories(cuda_demo PRIVATE /usr/local/cuda/include)
# Link CUDA libraries
target_link_libraries(cuda_demo ${CUDA_LIBRARIES})
1.3 cuda文件
// cuda_test.cu
#include <iostream>
#include <cuda_runtime.h>
__global__ void add(int *a, int *b, int *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
extern "C" void call_cuda_add(int *a, int *b, int *c, int N) {
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(a, b, c, N);
cudaDeviceSynchronize();
}
1.4 main.cpp 文件
// main.cpp
#include <iostream>
#include <vector>
#include <cuda_runtime.h>
extern "C" void call_cuda_add(int *a, int *b, int *c, int N);
int main() {
const int N = 1000;
std::vector<int> a(N, 1), b(N, 2), c(N);
int *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
cudaMemcpy(d_a, a.data(), N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b.data(), N * sizeof(int), cudaMemcpyHostToDevice);
call_cuda_add(d_a, d_b, d_c, N);
cudaMemcpy(c.data(), d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; ++i) {
std::cout << "Result[" << i << "]: " << c[i] << std::endl;
}
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
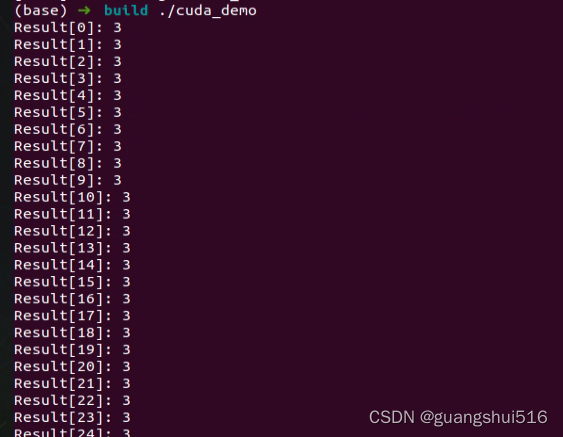
1.5 编译执行




















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











