







目录
一、Solr 是什么?
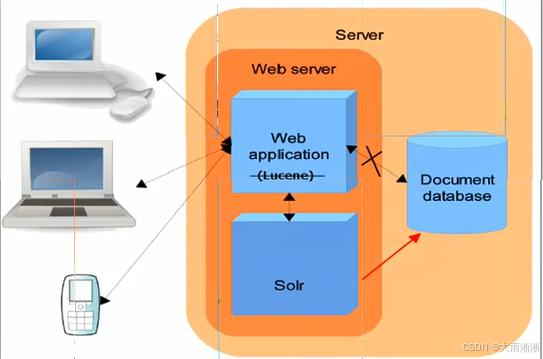
在如今这个信息爆炸的时代,数据如同潮水般涌来,如何从海量的数据中快速、准确地找到我们需要的信息,成为了一个至关重要的问题。Solr,作为一款强大的搜索工具,应运而生。它就像是一位知识渊博的图书管理员,能够快速帮你从浩如烟海的书籍中找到你想要的那一本。
Solr 是基于 Apache Lucene 构建的用于搜索和分析的开源解决方案,是一个独立的企业级搜索应用服务器,采用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。用户可以通过 http 请求,向搜索引擎服务器提交一定格式的 XML 文件,生成索引,也可以通过 Http Get 操作提出查找请求,并得到 XML 格式的返回结果 。它提供了强大的搜索功能,可以处理大量数据,并提供了实时搜索、自动完成、多语言支持等功能。从本质上讲,Solr 就像是一个超级智能的信息管家,它可以高效地管理和检索大量的数据。无论是企业内部的文档搜索,还是电商平台的商品查找,Solr 都能大显身手。
二、Solr 的独特优势
(一)强大的搜索能力
Solr 之所以在搜索领域备受青睐,首要原因在于其强大的搜索能力。它能在海量数据中实现快速精准的搜索,这对于如今数据爆炸的时代至关重要。无论是电商平台上数以百万计的商品,还是新闻媒体网站上的海量文章,Solr 都能在短时间内给出准确的搜索结果。
Solr 支持多种查询语法,这使得用户可以根据不同的需求进行灵活查询。比如,在电商搜索中,用户可以使用通配符查询,如输入 “appl*”,就能找到所有包含 “appl” 的商品,像 “apple”“application” 等相关商品都会出现在结果中 ,这对于用户不确定完整关键词时非常方便。再比如,使用布尔查询,输入 “title:Solr AND content:search”,就能精准定位到标题包含 “Solr” 且内容包含 “search” 的文档,满足了复杂搜索条件下的需求。这种丰富的查询语法,就像是给用户提供了一把万能钥匙,可以打开各种复杂搜索场景的大门,精准地获取所需信息。
(二)丰富的功能特性
除了强大的搜索能力,Solr 还具备丰富的功能特性,这些特性进一步提升了搜索体验。
命中高亮是 Solr 的一个实用功能。当用户搜索关键词后,Solr 会在搜索结果中突出显示与关键词匹配的部分,通常会使用特殊的颜色或标记来标识,让用户一眼就能看到哪些内容与自己的搜索相关。例如,在一篇长篇新闻报道中搜索某个特定事件,命中高亮功能可以迅速帮助用户定位到报道中关于该事件的具体描述部分,大大节省了用户筛选信息的时间,提升了搜索的效率和体验。
分面搜索也是 Solr 的一大亮点。它允许用户根据不同的维度对搜索结果进行筛选和分类。以电商平台为例,用户在搜索商品时,可以按照价格范围、品牌、颜色、尺寸等多个属性进行分面筛选。比如,用户搜索 “运动鞋”,不仅可以得到所有运动鞋的结果,还能通过分面搜索,进一步筛选出 “价格在 500 - 1000 元之间”“品牌为耐克”“颜色为黑色” 的运动鞋,让搜索结果更加精准地满足用户需求,帮助用户快速找到心仪的商品。
实时索引功能则确保了新添加或修改的文档能够快速被索引并可被搜索到。在一些对信息时效性要求极高的场景,如新闻资讯、社交媒体等,新发布的新闻或用户的动态能够在极短的时间内被其他用户搜索到,保证了信息的及时性和准确性,让用户能够获取到最新的信息。
(三)良好的扩展性
在数据量和访问量不断增长的情况下,系统的扩展性至关重要。Solr 采用分布式架构,支持集群部署方式,这使得它能够轻松应对大规模数据和高并发访问的挑战。
在分布式架构中,Solr 将索引数据分布存储在多个节点上,每个节点负责处理一部分数据。当有搜索请求到来时,这些节点可以并行处理,大大提高了搜索的效率和速度。同时,通过集群部署,Solr 可以方便地添加新的节点来扩展系统的处理能力。当数据量增加时,只需增加节点数量,Solr 就能自动将数据均衡分配到各个节点上,保证系统的性能不会因为数据量的增长而下降。这种良好的扩展性,就像一个可以无限扩容的仓库,无论有多少数据,都能轻松容纳并高效管理,为企业的发展提供了有力的技术支持,让企业在面对不断增长的数据和用户需求时,无需担心搜索性能的问题。
三、Solr 的工作原理大揭秘
(一)索引构建
Solr 的强大搜索能力离不开其高效的索引构建过程,这个过程就像是为一本厚厚的书籍制作详细的目录,以便后续能够快速找到所需内容。假设我们有一批电商商品数据,包含商品名称、描述、价格等信息,需要将这些数据构建成 Solr 索引。
首先是数据预处理,当原始文档数据进入 Solr 后,会进行一系列的预处理操作。对于文本数据,会进行字符编码转换,确保数据的一致性 ,比如将不同编码格式的商品描述统一转换为 UTF - 8 编码。同时,会去除一些特殊字符,像商品名称中的标点符号等,使数据更加规范,便于后续处理。
接着是分词,这是索引构建的关键步骤。分词器会将文本拆分成一个个独立的词(Term)。以商品描述 “这是一款高性能的智能手机,拥有高清屏幕和强大的处理器” 为例,使用中文分词器(如 IK Analyzer)进行分词,可能会得到 “这是”“一款”“高性能”“智能手机”“拥有”“高清屏幕”“强大”“处理器” 等词。不同语言的分词方式有所不同,英文分词相对简单,主要根据空格和标点符号进行拆分,而中文分词则需要借助专门的算法和词典来准确识别词语边界。
然后是提取关键词,在分词的基础上,Solr 会根据一定的算法提取出重要的关键词。对于商品数据,像 “智能手机”“高清屏幕”“处理器” 这些能够准确描述商品核心特征的词,会被视为关键词。这些关键词将成为后续索引和搜索的重要依据。
最后是建立索引结构,Solr 采用倒排索引结构来存储数据。在倒排索引中,关键词作为索引的入口,每个关键词都对应一个包含该关键词的文档列表(倒排列表),同时还记录了关键词在文档中的位置、出现频率等信息。比如关键词 “智能手机”,其倒排列表中会记录包含该词的所有商品文档的 ID,以及在每个文档中的出现位置和次数等。这样,当进行搜索时,通过关键词就能快速定位到相关的文档,大大提高了搜索效率 。整个索引构建过程是一个复杂而有序的过程,每一个步骤都紧密相连,为 Solr 的高效搜索奠定了坚实的基础。
(二)查询处理
当用户在使用 Solr 进行搜索时,其查询请求的处理流程也十分精细,就像一场精密的仪器运作,确保用户能够快速得到准确的结果。比如用户在电商平台上搜索 “红色运动鞋”,这个查询请求会经历以下步骤。
首先是解析查询,Solr 接收到用户的查询请求后,会使用查询解析器对查询字符串进行解析。解析器会识别查询语法,将 “红色运动鞋” 解析成一个个可以理解的查询单元。如果用户使用了更复杂的查询语法,如 “(红色 AND 运动鞋) OR 运动跑鞋”,解析器也能准确分析出各个条件之间的逻辑关系 。
接着是检索索引,根据解析后的查询条件,Solr 会在之前构建好的索引中进行检索。对于 “红色运动鞋” 的查询,它会分别查找 “红色” 和 “运动鞋” 这两个关键词在倒排索引中的位置,获取包含这两个关键词的文档列表。
然后是计算相关性,得到初步的文档列表后,Solr 会根据一定的算法计算每个文档与查询的相关性得分。相关性得分的计算会考虑多个因素,比如关键词在文档中的出现频率,出现频率越高,得分可能越高;关键词在文档中的位置,出现在标题或开头部分的关键词可能比出现在文档末尾的更重要,得分也会相应提高;还会考虑文档的权重等因素,比如一些热门商品或优质商家的商品文档可能会被赋予更高的权重。通过这些因素的综合计算,为每个文档生成一个相关性得分。
最后是返回结果,Solr 会根据相关性得分对文档进行排序,将得分高的文档排在前面,然后按照用户设置的分页参数(如起始位置 start 和返回数量 rows),将排序后的结果返回给用户。如果用户还设置了其他参数,如按照价格、销量等进行排序,Solr 也会在这一步进行相应的处理,确保返回的结果符合用户的需求。整个查询处理过程高效而准确,能够快速响应用户的搜索请求,为用户提供精准的搜索结果 。
四、Solr 应用场景大放送
(一)电商平台商品搜索
在电商领域,Solr 可谓是大放异彩。以京东、淘宝等大型电商平台为例,它们拥有海量的商品数据,涵盖了各种品类、品牌和规格。Solr 能够对这些商品信息进行高效索引,当用户在搜索框中输入关键词,如 “运动鞋” 时,Solr 可以迅速从数以千万计的商品中筛选出相关的产品 。不仅如此,Solr 还支持多维度筛选和排序功能。用户可以根据价格区间,如 “500 - 1000 元”,筛选出符合预算的运动鞋;也可以按照品牌,如 “耐克”“阿迪达斯” 等进行筛选;还能根据销量、评价等指标对搜索结果进行排序,让用户能够更方便地找到心仪的商品。在一些促销活动期间,如 “双 11”“618”,电商平台的访问量和搜索请求会呈爆发式增长,Solr 凭借其分布式架构和良好的扩展性,能够轻松应对高并发的搜索请求,确保用户在购物高峰期也能享受到快速、稳定的搜索体验 。
(二)企业内部文档检索
对于企业来说,随着业务的发展,内部会积累大量的文档,包括合同、报告、方案、技术文档等。这些文档是企业的知识财富,但如果没有高效的检索工具,查找起来就会非常困难。Solr 在企业文档管理系统中发挥着关键作用,它可以对各种格式的文档,如 Word、PDF、Excel 等进行索引和搜索。例如,一家大型企业的研发部门,员工需要查找某一技术方案的历史版本,只需在文档管理系统的搜索框中输入相关关键词,Solr 就能快速定位到包含这些关键词的文档,并按照相关性、创建时间等因素进行排序后返回给员工。这大大提高了员工获取信息的效率,促进了企业内部的知识共享和协作 。通过 Solr,企业可以打破信息孤岛,让员工能够更便捷地获取所需知识,提升整体工作效率和创新能力。
(三)新闻资讯搜索
在新闻行业,信息的时效性和准确性至关重要。像新浪、腾讯等新闻平台,每天都会发布大量的新闻资讯。Solr 能够满足新闻平台对海量资讯的搜索需求,当用户想要了解某一事件的相关新闻时,如 “世界杯足球赛”,Solr 可以快速从海量的新闻文章中找到与之相关的报道 。而且,Solr 支持实时索引,新发布的新闻能够在短时间内被索引并可搜索,保证了用户能够获取到最新的资讯。在突发新闻事件中,Solr 的快速搜索能力显得尤为重要,用户可以第一时间通过搜索获取事件的最新进展和各方报道,满足了用户对新闻及时性的需求。
五、上手 Solr:安装与配置指南
现在我们已经了解了 Solr 的基本概念、优势、工作原理和应用场景,接下来就进入实战环节,看看如何将 Solr 安装到我们的系统中并进行配置,让它能够为我们的搜索需求服务。这里以在 Windows 系统上安装 Solr 8.11.2 为例进行介绍。
(一)下载 Solr
首先,我们需要从 Apache Solr 的官方网站(https://lucene.apache.org/solr/)下载 Solr 的安装包。在下载页面,找到适合你系统的版本,这里我们选择下载solr-8.11.2.zip压缩包。下载完成后,将压缩包解压到你希望安装 Solr 的目录,比如D:\solr-8.11.2 。解压后的目录结构如下:
solr-8.11.2
├── bin
├── contrib
├── dist
├── docs
├── example
├── licenses
├── server
└── ...
其中,bin目录包含启动和停止 Solr 服务器的脚本;server目录包含 Solr 服务器的核心文件和配置文件;example目录包含一些示例文件,用于帮助我们快速了解 Solr 的使用方法。
(二)安装 JDK
Solr 是基于 Java 开发的,所以在安装 Solr 之前,需要确保系统中已经安装了 Java Development Kit(JDK)。如果你的系统中还没有安装 JDK,可以从 Oracle 官方网站(https://www.oracle.com/java/technologies/downloads/)下载并安装。安装完成后,需要配置JAVA_HOME环境变量。在 Windows 系统中,打开 “系统属性” -> “高级” -> “环境变量”,在 “系统变量” 中找到JAVA_HOME变量(如果没有则新建一个),将其值设置为 JDK 的安装目录,比如C:\Program Files\Java\jdk1.8.0_341 。然后,在 “系统变量” 中找到Path变量,点击 “编辑”,在变量值的末尾添加%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin; 。保存设置后,打开命令提示符,输入java -version,如果能够正确输出版本信息,说明 JDK 安装和配置成功。
(三)启动 Solr
进入 Solr 解压目录的bin文件夹,例如D:\solr-8.11.2\bin,在命令提示符中执行以下命令启动 Solr:
solr start
如果一切顺利,你会看到 Solr 启动的相关日志信息,并且 Solr 会默认运行在http://localhost:8983端口上。打开浏览器,访问http://localhost:8983/solr/,如果看到 Solr 的管理界面,说明 Solr 已经成功启动。
(四)创建核心(Core)
在 Solr 中,一个核心(Core)相当于一个独立的索引和搜索单元,每个 Core 可以有自己独立的配置和数据。我们可以通过命令行或者 Solr 管理界面来创建 Core。这里我们使用命令行创建一个名为my_core的 Core,在命令提示符中执行以下命令:
solr create -c my_core
执行上述命令后,Solr 会在server/solr目录下创建一个名为my_core的文件夹,用于存放该 Core 的配置文件和索引数据。
(五)配置核心(Core)
创建完 Core 后,我们需要对其进行一些配置,以满足我们的搜索需求。进入server/solr/my_core/conf目录,这里存放着my_core的配置文件。其中,managed-schema文件用于定义索引的字段和数据类型等信息;solrconfig.xml文件用于配置 Solr 的各种参数,如索引更新策略、查询处理器等。
以配置managed-schema文件为例,如果我们希望在搜索中支持中文分词,需要添加中文分词器的配置。这里我们使用 IK Analyzer 分词器,首先将 IK Analyzer 的相关 jar 包(ik-analyzer-solr8-8.x.x.jar等)复制到server/solr-webapp/webapp/WEB-INF/lib目录下,然后在managed-schema文件中添加以下配置:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
上述配置定义了一个名为text_ik的字段类型,使用 IK Analyzer 分词器进行分词,在索引时使用细粒度分词(useSmart="false"),在查询时使用智能分词(useSmart="true")。然后,我们可以根据实际需求,在managed-schema文件中添加或修改其他字段的定义,例如:
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="content" type="text_ik" indexed="true" stored="true"/>
上述配置添加了title和content两个字段,类型为text_ik,表示这两个字段会进行中文分词并建立索引,同时存储字段值,以便在搜索结果中返回。
对于solrconfig.xml文件,也可以根据实际需求进行一些配置,比如设置索引的自动提交时间、缓存大小等。例如,将索引的自动提交时间设置为 60 秒,可以在solrconfig.xml文件中找到<autoCommit>标签,修改为:
<autoCommit>
<maxTime>60000</maxTime>
</autoCommit>
上述配置表示每隔 60 秒自动提交一次索引,确保新添加或修改的数据能够及时被索引。
通过以上步骤,我们就完成了 Solr 的安装和基本配置。当然,Solr 的配置非常灵活,可以根据不同的应用场景和需求进行更深入的调整和优化 。在实际使用中,还可以通过 Solr 提供的 API 来进行索引的添加、更新、删除以及查询等操作,将 Solr 集成到我们的应用系统中,实现强大的搜索功能。
六、Solr 使用技巧与优化策略
在使用 Solr 的过程中,掌握一些实用的技巧和优化策略能够显著提升其性能和搜索效果,让 Solr 更好地服务于我们的应用场景。下面将从查询优化和索引优化两个方面来介绍一些常见的技巧和策略。
(一)查询优化
- 合理使用查询语法:熟练掌握 Solr 的查询语法是提高查询效率的基础。例如,在电商搜索中,使用通配符查询时要谨慎,因为通配符查询可能会导致全量扫描,影响查询性能。如果要查询商品名称中包含 “苹果” 的商品,使用product_name:苹果*这种通配符查询时,应确保数据量不大或者有其他条件限制,否则可以考虑使用更精确的查询方式,如分词查询product_name:苹果 。对于布尔查询,要准确理解AND(与)、OR(或)、NOT(非)的逻辑关系,避免写错查询条件。例如,要查询标题包含 “Solr” 且内容不包含 “elasticsearch” 的文档,查询语句可以写成title:Solr AND content:(* NOT elasticsearch) 。
- 优化查询参数:合理设置查询参数也能对查询性能产生重要影响。start和rows参数用于分页,在进行分页查询时,要避免在大数据集上进行深分页。比如,当数据量很大时,查询第 10000 页,每页 10 条数据,这样的查询可能会非常慢,因为 Solr 需要先获取前面 99990 条数据,然后再返回当前页的数据。此时可以考虑使用滚动查询(Scroll API)来处理大数据集的分页问题 。sort参数用于排序,如果需要对多个字段进行排序,要注意排序字段的顺序和排序方式(升序asc或降序desc),合理的排序顺序可以减少排序的时间复杂度。例如,在电商搜索中,先按照销量降序排序,再按照价格升序排序,可以写成sort=销量 desc,价格 asc 。fq(过滤查询)参数可以在不影响评分的情况下对结果集进行过滤,对于一些常用的筛选条件,使用fq参数可以利用更高效的缓存机制,提高查询性能。比如在电商搜索中,要筛选出价格在 500 - 1000 元之间的商品,可以使用fq=价格:[500 TO 1000] 。
- 利用缓存:Solr 提供了多种缓存机制,合理利用缓存可以大大提高查询性能。过滤器缓存(filterCache)用于缓存过滤器查询的结果,当再次执行相同的过滤器查询时,可以直接从缓存中获取结果,避免重复计算。例如,在电商搜索中,经常会按照品牌、价格区间等条件进行筛选,这些筛选条件可以作为过滤器查询,将其结果缓存起来,下次查询相同条件时就能快速返回结果 。文档缓存(documentCache)用于缓存文档内容,当查询结果需要返回文档的详细信息时,如果文档已经在缓存中,就可以直接从缓存中获取,减少磁盘 I/O 操作。结果集缓存(queryResultCache)用于缓存查询结果,如果相同的查询再次执行,且缓存未过期,就可以直接返回缓存中的结果,提高查询响应速度。可以通过调整缓存的大小、过期时间等参数来优化缓存性能,例如在solrconfig.xml文件中配置:
<filterCache
class="solr.FastLRUCache"
size="512"
initialSize="128"
autowarmCount="128"/>
<documentCache
class="solr.FastLRUCache"
size="512"
initialSize="128"
autowarmCount="128"/>
<queryResultCache
class="solr.FastLRUCache"
size="512"
initialSize="128"
autowarmCount="128"/>
上述配置设置了过滤器缓存、文档缓存和结果集缓存的初始大小为 128,最大大小为 512,并设置了自动预热数量为 128,可根据实际情况进行调整。
(二)索引优化
- 选择合适的分词器:分词器的选择直接影响到索引的质量和搜索的准确性。对于英文文本,标准分词器(StandardTokenizerFactory)通常能满足基本需求,它会按照空格和标点符号进行分词,并将单词转换为小写。但对于中文文本,标准分词器的效果往往不理想,需要使用专门的中文分词器,如 IK Analyzer、结巴分词等。以 IK Analyzer 为例,它支持细粒度分词和智能分词两种模式。在索引时,可以使用细粒度分词模式,将文本切分得更细,提高索引的精确性;在查询时,使用智能分词模式,能够更好地理解用户的查询意图,提高搜索的召回率。例如,在managed-schema文件中配置 IK Analyzer 分词器:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
- 设置索引参数:合理设置索引参数可以优化索引性能。在solrconfig.xml文件中,可以设置索引的自动提交策略(autoCommit)。自动提交策略可以基于时间或文档数量触发,例如:
<autoCommit>
<maxTime>60000</maxTime>
<maxDocs>1000</maxDocs>
</autoCommit>
上述配置表示每隔 60 秒或者当新增文档达到 1000 条时,自动提交一次索引。自动提交虽然能保证数据的实时性,但过于频繁的提交会影响索引性能,因为每次提交都涉及到磁盘 I/O 操作和索引的合并等操作。所以需要根据实际应用场景来平衡实时性和性能的需求。对于一些不需要实时搜索的场景,可以适当增大maxTime和maxDocs的值,减少提交次数 。还可以设置索引的合并策略(mergePolicy),不同的合并策略会影响索引的大小、查询性能和索引创建速度。例如,TieredMergePolicy是 Solr 默认的合并策略,它通过分层合并的方式来管理索引段,可以通过调整其参数来优化索引性能,如maxMergeAtOnce参数控制一次合并的最大段数,minMergeMB参数控制最小合并的索引大小等 。
3. 定期优化索引:随着数据的不断更新和删除,索引可能会出现碎片化的情况,导致查询性能下降。定期优化索引可以合并小的索引段,减少索引文件的数量,提高查询性能。可以通过在 Solr 管理界面或者使用命令行工具来执行索引优化操作。在 Solr 管理界面中,进入对应的 Core,在 “Core Admin” 选项卡中选择 “Optimize” 操作,即可对索引进行优化 。也可以通过命令行执行优化命令,例如:
curl "http://localhost:8983/solr/my_core/update?optimize=true"
在执行索引优化时,要注意选择合适的时间,避免在业务高峰期进行,以免影响系统的正常运行。同时,优化索引可能会占用较多的系统资源,如 CPU、内存和磁盘 I/O 等,所以在优化前要确保系统有足够的资源可用 。
七、总结与展望
Solr 作为一款强大的开源搜索工具,凭借其强大的搜索能力、丰富的功能特性和良好的扩展性,在电商、企业文档管理、新闻资讯等众多领域都有着广泛而出色的应用,为海量数据的高效检索提供了可靠的解决方案 。
随着技术的不断发展,搜索领域也在持续演进。未来,Solr 有望在人工智能与机器学习的融合方面取得更多突破,通过引入智能算法,进一步提升搜索的精准度和智能化水平,为用户提供更加个性化、智能化的搜索体验 。同时,在应对不断增长的数据量和日益复杂的搜索需求时,Solr 也将不断优化自身的架构和性能,以适应大数据时代的挑战。
如果你正在寻找一款高效、灵活的搜索解决方案,不妨尝试一下 Solr。相信它会在你的数据处理和信息检索工作中发挥巨大的作用,为你带来意想不到的便利和价值。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











