







目录
一、揭开 Lucene 的神秘面纱
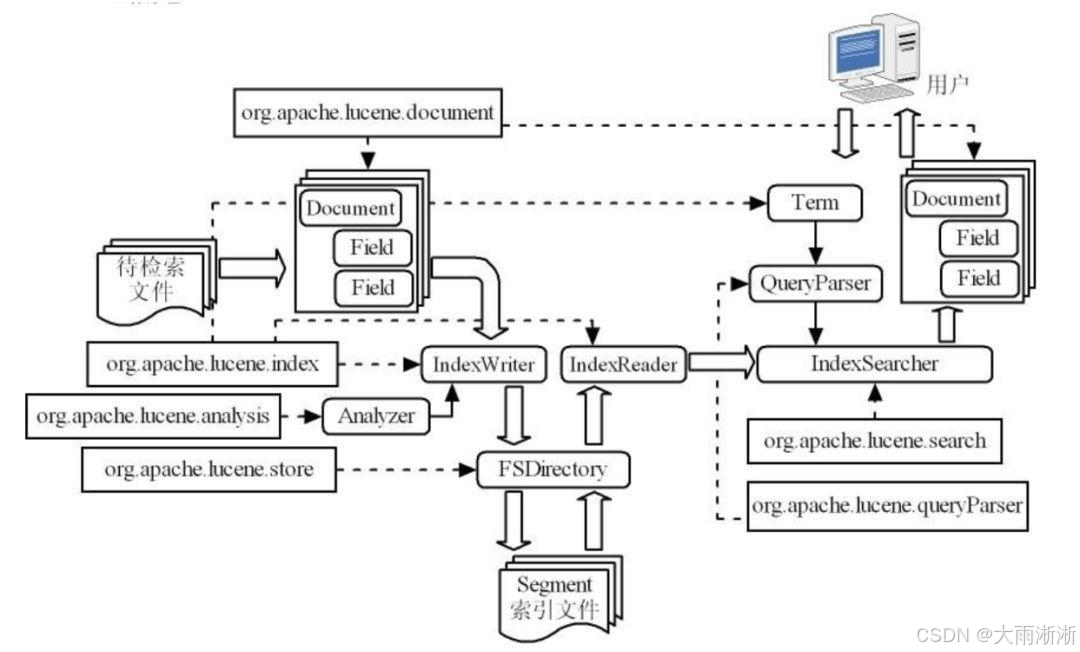
在 Java 开发的广袤天地里,Lucene 可是一位响当当的 “明星”。它就像是一把神奇的钥匙,为无数应用打开了高效全文检索的大门。你或许不知道 Lucene 这个名字,但你一定用过那些基于 Lucene 构建的软件。像大名鼎鼎的 Elasticsearch 和 Solr,它们之所以能在搜索领域大放异彩,Lucene 功不可没。还有 Apache 软件基金会的网站,IBM 的开源软件 Eclipse 以及商业软件 Web Sphere 等,都借助 Lucene 实现了强大的全文检索功能 。这些知名软件的背后,都有着 Lucene 默默支持的身影,足以见得它在行业中的重要地位。那么,Lucene 究竟是什么?它又有着怎样的魔力,能让众多软件对它青睐有加呢?接下来,就让我们一同深入探寻 Lucene 的世界。
二、Lucene 究竟是什么
Lucene 是 Apache 软件基金会 Jakarta 项目组的一个子项目 ,是一个开放源代码的全文检索引擎工具包。但需要注意的是,它并非一个完整的全文检索引擎,而是一个全文检索引擎的架构。它就像是一个精心搭建的舞台框架,虽然本身不是一场完整的演出,但却为各种精彩的表演(全文检索功能)提供了必不可少的基础和支撑。
Lucene 为软件开发人员提供了一个简单易用的工具包,有了这个工具包,开发者们就能够在自己的目标系统中轻松实现全文检索的功能。想象一下,你正在开发一个文档管理系统,里面存储了大量的文档资料。如果没有高效的搜索功能,用户想要找到特定的文档,就如同大海捞针。而 Lucene 就可以帮助你解决这个难题,它提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。借助这些强大的功能,你可以为文档建立索引,当用户输入关键词进行搜索时,系统能够快速准确地从众多文档中找到相关内容,并呈现给用户 。这大大提升了系统的可用性和用户体验。
在实际应用中,Lucene 的身影无处不在。除了前面提到的 Elasticsearch 和 Solr 等知名搜索框架基于 Lucene 构建外,许多企业内部的信息管理系统、知识图谱项目等也常常利用 Lucene 来实现搜索功能。它就像一个默默奉献的幕后英雄,虽然不常被用户直接看到,但却在各种软件应用的背后发挥着关键作用,为信息的快速检索和获取提供了强大的支持。
三、Lucene 的诞生与成长
Lucene 的诞生,离不开 Doug Cutting 这位资深全文索引 / 检索专家 。他曾是 V - Twin 搜索引擎的主要开发者,后来又在 Excite 担任高级系统架构设计师,在全文索引和检索领域有着深厚的技术积累和丰富的经验。2000 年 3 月,Doug Cutting 将 Lucene 发布在了 SourceForge 上,最初的 Lucene 就像是一颗刚刚萌芽的种子,承载着 Doug Cutting 对于全文检索技术的创新理念和无限期望 。
在当时的软件开发领域,虽然已经存在一些全文检索的解决方案,但大多存在着各种局限性,比如商业软件价格昂贵,开源项目功能不够强大、可扩展性差等。Doug Cutting 开发 Lucene 的初衷,就是为了给广大软件开发人员提供一个简单易用、高效且开源的全文检索工具包,让他们能够在自己的项目中轻松实现强大的全文检索功能,降低开发成本和技术门槛。
2001 年 9 月,对于 Lucene 来说是一个重要的转折点,它作为高质量的开源 Java 产品加入到了 Apache 软件基金会的 Jakarta 家族中 。这一转变为 Lucene 的发展带来了质的飞跃,就如同小树苗被移植到了肥沃的土壤中,得到了更多的养分和资源。借助 Apache 软件基金会强大的社区支持和网络平台,Lucene 吸引了越来越多开发者的关注和参与。这些开发者来自世界各地,他们带着不同的技术背景和想法,纷纷为 Lucene 贡献自己的代码和智慧。在大家的共同努力下,Lucene 不断进化和完善,功能日益强大。
回顾 Lucene 的版本发展历程,每一个重要版本都像是 Lucene 成长道路上的一座里程碑,记录着它的进步与突破 。2000 年 10 月发布的 1.0 版本,标志着 Lucene 初步成型,具备了基本的全文检索功能架构,为后续的发展奠定了坚实的基础。2002 年 6 月发布的 1.2 版本,作为第一个 Apache Jakarta 版本,在稳定性和性能上都有了显著的提升,也正式开启了 Lucene 在 Apache 社区的辉煌发展篇章。2003 年 12 月的 1.3 版本引入了复合索引格式,增加了查询分析器,支持远程搜索和 token 定位,同时还扩展了 API,这些新特性使得 Lucene 的功能更加丰富和强大,能够满足更多复杂场景下的全文检索需求。
2004 年 7 月发布的 1.4 版本更是带来了诸多令人瞩目的改进,比如增加了排序(Sorting)功能,支持跨度查询(span queries)和词向量(term vectors) 。排序功能的加入,让搜索结果能够按照用户设定的规则进行排序,大大提高了搜索结果的相关性和可用性;跨度查询则为用户提供了更灵活的查询方式,可以根据关键词之间的位置关系进行查询,进一步提升了查询的精准度;词向量的支持则为文本分析和语义理解等高级应用提供了有力的数据支持。
随着时间的推移,Lucene 持续迭代更新,不断引入新的特性和优化现有功能。2009 年 9 月发布的 2.9.0 版本在性能优化和功能扩展方面又取得了新的进展;2009 年 11 月发布的 3.0.0 版本更是具有里程碑意义,它在索引性能、查询效率和内存管理等方面都有了重大改进,进一步巩固了 Lucene 在全文检索领域的领先地位。
到了 2010 年代,Lucene 依然保持着快速的发展步伐。2011 年 7 月发布的 3.3.0 版本和 9 月发布的 3.4.0 版本,都在不同程度上对索引和查询进行了优化,提升了系统的整体性能和稳定性 。此后,Lucene 的每一个版本都在不断地适应新的技术发展趋势和用户需求,持续为开发者们提供更强大、更高效的全文检索解决方案。
在 Lucene 的发展过程中,社区的力量起到了至关重要的作用 。Apache Lucene 社区就像是一个充满活力的技术大家庭,众多开发者在这里交流、合作、共同进步。他们不仅积极参与代码的开发和维护,还会及时反馈使用过程中遇到的问题和提出宝贵的改进建议。正是这种开放、协作的社区氛围,使得 Lucene 能够不断地吸收新的思想和技术,保持旺盛的生命力,成为了全文检索领域的经典之作,被广泛应用于各种软件项目中,为无数用户带来了高效便捷的信息检索体验 。
四、独特优势大揭秘
(一)独立于平台的索引文件格式
在软件应用的多元化发展趋势下,不同系统和平台之间的兼容性成为了关键问题。Lucene 在这方面展现出了卓越的优势,它定义了一套以 8 位字节为基础的索引文件格式 。这种独特的设计,就像是为不同的应用程序搭建了一座通用的桥梁,使得兼容系统或者不同平台的应用能够轻松共享建立的索引文件。
想象一下,在一个大型企业中,可能同时存在着基于 Windows 系统的办公软件、基于 Linux 系统的服务器应用以及基于 Mac 系统的设计工具,它们都需要对大量的文档进行全文检索 。如果没有统一的索引文件格式,每个系统都需要单独建立和维护自己的索引,这不仅会耗费大量的时间和资源,还会导致数据的不一致性和管理的复杂性。而 Lucene 的独立于平台的索引文件格式,很好地解决了这个难题。无论应用程序运行在何种平台上,只要遵循 Lucene 定义的索引文件格式,就可以共享索引文件,实现高效的全文检索。这大大提高了系统的灵活性和可扩展性,降低了开发和维护成本。
(二)创新的分块索引技术
在传统的全文检索引擎中,倒排索引是一种常用的索引结构。而 Lucene 在倒排索引的基础上,进行了大胆的创新,实现了分块索引技术 。这种技术的原理就像是将一个大工程分解成多个小任务,各个击破,从而提高整体效率。
具体来说,当有新的文件需要建立索引时,Lucene 会针对这些新文件建立小文件索引 。这就好比在一个大型图书馆中,新到了一批书籍,工作人员先将这些书籍按照类别进行初步分类,建立小的索引卡片,这样可以快速地对新到的书籍进行索引处理,大大提升了索引速度。然后,通过与原有索引的合并,达到优化的目的。就像把新的索引卡片与图书馆原有的索引系统进行整合,使得整个索引体系更加完善和高效。
这种分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











