




 本文详细介绍了计算机视觉领域的关键技术和应用,包括图像增广、微调、目标检测、边界框、多尺度目标检测、SSD模型、R-CNN系列以及语义分割。图像增广通过随机变换扩大训练数据集,增强模型泛化能力;微调则是将预训练模型的知识迁移到特定任务上。目标检测中,锚框和多尺度检测技术用于定位不同大小的目标,SSD模型实现高效检测。此外,R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN和Mask R-CNN)逐步优化了目标检测的速度和精度。语义分割任务则关注像素级别的分类,全卷积网络(FCN)是其核心技术。最后,样式迁移展示了卷积神经网络在艺术风格转换方面的潜力。
本文详细介绍了计算机视觉领域的关键技术和应用,包括图像增广、微调、目标检测、边界框、多尺度目标检测、SSD模型、R-CNN系列以及语义分割。图像增广通过随机变换扩大训练数据集,增强模型泛化能力;微调则是将预训练模型的知识迁移到特定任务上。目标检测中,锚框和多尺度检测技术用于定位不同大小的目标,SSD模型实现高效检测。此外,R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN和Mask R-CNN)逐步优化了目标检测的速度和精度。语义分割任务则关注像素级别的分类,全卷积网络(FCN)是其核心技术。最后,样式迁移展示了卷积神经网络在艺术风格转换方面的潜力。

第九章 计算机视觉
先介绍两种有助于提升模型泛化能力的方法:图像增广和微调。
鉴于深度神经网络能够对图像逐级有效地进行表征:所以广泛应用到目标检测、语义分割和样式迁移这些主流计算机视觉任务中。
全卷积网络对图像做语义分割。
样式迁移技术生成封面图像。
一、图像增广
图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。
图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
裁剪感兴趣区域出现在不同位置,减轻模型对物体出现位置的依赖性;
调整亮度、色彩、对比度、饱和度、色调来降低模型对色彩的敏感度。
上下翻转不如左右翻转。
以上规则叠加使用。
为了在预测时得到确定的结果,我们通常只将图像增广应用在训练样本上,而不在预测时使用含随机操作的图像增广。
二、微调
适用于ImageNet数据集的复杂模型在我们应用场景的数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
为了解决这个问题:
一方面:收集更多的数据集。然而收集数据集花费大量的时间和资金。
另一方面:迁移学习(Transfer learning),将从源数据集学到的知识迁移到目标数据集上。虽然ImageNet数据集的图像大多跟我们的应用场景无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别我们的场景也可能同样有效。
迁移学习的一种常用技术:微调(fine tuning) :
-
在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
-
为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
-
在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
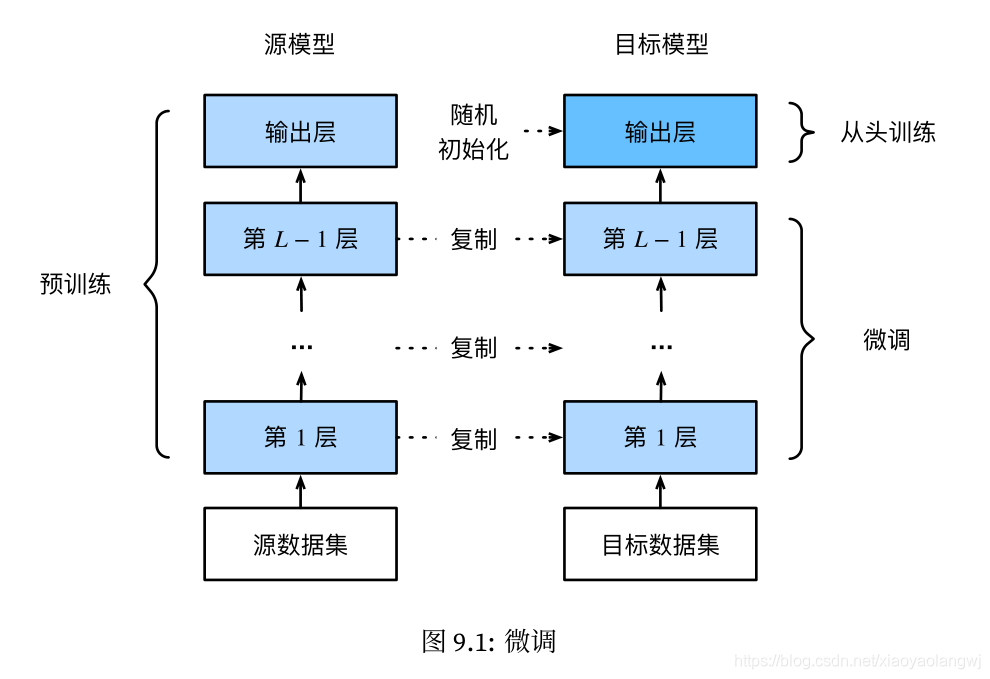
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
PyTorch可以方便的对模型的不同部分设置不同的学习参数。
小结:
-
迁移学习将从源数据集学到的知识迁移到目标数据集上。微调是迁移学习的一种常用技术。
-
目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数。而目标模型的输出层需要从头训练。
-
一般来说,微调参数会使用较小的学习率,而从头训练输出层可以使用较大的学习率。
三、目标检测和边界框
在图像分类任务中,我们假设图像里只有一个主题目标,并关注如何识别该目标的类别。然而,很多图像里有多个我们感兴趣的目标,不仅需要知道它们的类别,还想得到它们在图像中的位置。这类任务称为:目标检测(object detection)或物体检测。
边界框(bounding box)来描述目标位置。矩形框,由左上角和右下角两个角点坐标确定。
四、锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
anchor只有跟你要检测的物体的大小和长宽比更贴近,才能让模型的效果更好。
anchor都是根据数据的实际分布来设置的。YOLOV3开始使用Kmeans方法聚类得到合适的anchor。
1、生成多个锚框
假设输入图像高为h,宽为w。我们分别以图像的每个像素为中心生成不同形状的锚框。设大小为且宽高比为
,那么锚框的宽和高将分别为
和
。当中心位置给定时,已知宽和高的锚框是确定的。

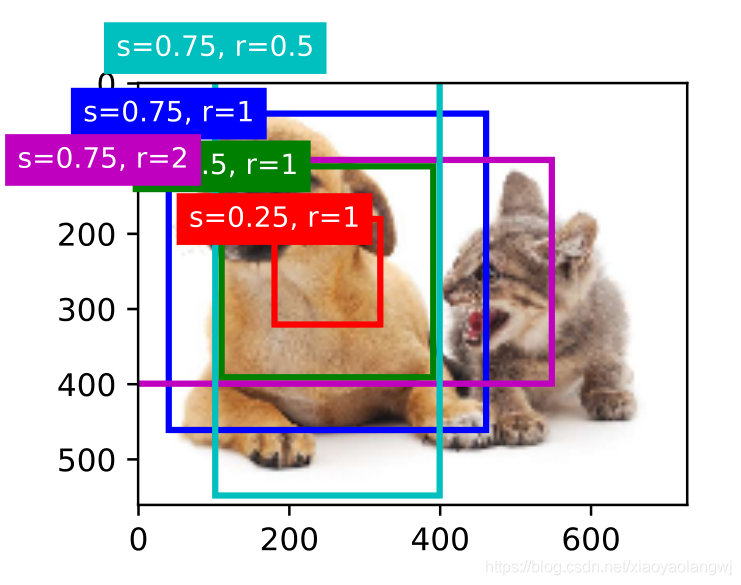
通过制定像素位置来获取所有以该像素为中心的锚框。上图以(250, 250)为中心的所有锚框。可以看到大小为0.75且宽高比为1的锚框较好地覆盖了图像中的狗。
2、交并比
为了衡
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4433
4433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









