







文章目录
设置
import tensorflow as tf
from tensorflow import keras
Layer类:状态(权重)和一些计算的组合
Keras中的核心抽象之一是Layer类。 一层封装了状态(层的“权重”)和从输入到输出的转换(“call”,即层的前向传递)。
这是一个紧密连接的层。 它具有一个状态:变量w和b。
class Linear(keras.layers.Layer):
def __init__(self, units=32, input_dim=32):
super(Linear, self).__init__()
w_init = tf.random_normal_initializer()
self.w = tf.Variable(
initial_value=w_init(shape=(input_dim, units), dtype="float32"),
trainable=True,
)
b_init = tf.zeros_initializer()
self.b = tf.Variable(
initial_value=b_init(shape=(units,), dtype="float32"), trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
您可以通过在某些张量输入上调用图层来使用图层,就像Python函数一样。
x = tf.ones((2, 2))
linear_layer = Linear(4, 2)
y = linear_layer(x)
print(y)

请注意,权重w和b在设置为图层属性时会自动由图层跟踪:
assert linear_layer.weights == [linear_layer.w, linear_layer.b]
请注意,您还可以使用一种更快的快捷方式为图层添加权重:add_weight()方法:
class Linear(keras.layers.Layer):
def __init__(self, units=32, input_dim=32):
super(Linear, self).__init__()
self.w = self.add_weight(
shape=(input_dim, units), initializer="random_normal", trainable=True
)
self.b = self.add_weight(shape=(units,), initializer="zeros", trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
x = tf.ones((2, 2))
linear_layer = Linear(4, 2)
y = linear_layer(x)
print(y)

图层可以具有不可训练的权重
除了可训练的权重之外,您还可以向图层添加不可训练的权重。 训练层时,不得在反向传播期间考虑此类权重。
以下是添加和使用不可训练的重量的方法:
class ComputeSum(keras.layers.Layer):
def __init__(self, input_dim):
super(ComputeSum, self).__init__()
self.total = tf.Variable(initial_value=tf.zeros((input_dim,)), trainable=False)
def call(self, inputs):
self.total.assign_add(tf.reduce_sum(inputs, axis=0))
return self.total
x = tf.ones((2, 2))
my_sum = ComputeSum(2)
y = my_sum(x)
print(y.numpy())
y = my_sum(x)
print(y.numpy())

它是layer.weights的一部分,但被归类为不可训练的重量:
print("weights:", len(my_sum.weights))
print("non-trainable weights:", len(my_sum.non_trainable_weights))
# It's not included in the trainable weights:
print("trainable_weights:", my_sum.trainable_weights)

最佳实践:将权重创建推迟到知道输入的形状为止
我们上面的线性层采用了input_dim 参数,用于计算__init __()中权重w和b的形状:
class Linear(keras.layers.Layer):
def __init__(self, units=32, input_dim=32):
super(Linear, self).__init__()
self.w = self.add_weight(
shape=(input_dim, units), initializer="random_normal", trainable=True
)
self.b = self.add_weight(shape=(units,), initializer="zeros", trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
在许多情况下,您可能事先不知道输入的大小,并且您想在实例化图层后的某个时间知道该值时延迟创建权重。
在Keras API中,建议您在图层的build(self,inputs_shape)方法中创建图层权重。 像这样:
class Linear(keras.layers.Layer):
def __init__(self, units=32):
super(Linear, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
)
self.b = self.add_weight(
shape=(self.units,), initializer="random_normal", trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
图层的__call __()方法在首次调用时将自动运行build。 现在您有了一个懒惰的图层,因此更易于使用:
# At instantiation, we don't know on what inputs this is going to get called
linear_layer = Linear(32)
# The layer's weights are created dynamically the first time the layer is called
y = linear_layer(x)
层可递归组合
如果将图层实例分配为另一个图层的属性,则外层将开始跟踪内层的权重。
我们建议在__init __()方法中创建此类子层(由于子层通常具有构建方法,因此将在构建外层时构建它们)。
# Let's assume we are reusing the Linear class
# with a `build` method that we defined above.
class MLPBlock(keras.layers.Layer):
def __init__(self):
super(MLPBlock, self).__init__()
self.linear_1 = Linear(32)
self.linear_2 = Linear(32)
self.linear_3 = Linear(1)
def call(self, inputs):
x = self.linear_1(inputs)
x = tf.nn.relu(x)
x = self.linear_2(x)
x = tf.nn.relu(x)
return self.linear_3(x)
mlp = MLPBlock()
y = mlp(tf.ones(shape=(3, 64))) # The first call to the `mlp` will create the weights
print("weights:", len(mlp.weights))
print("trainable weights:", len(mlp.trainable_weights))

add_loss()方法
编写层的call()方法时,可以创建损耗张量,稍后将在编写训练循环时使用。 这可以通过调用self.add_loss(value)来实现:
# A layer that creates an activity regularization loss
class ActivityRegularizationLayer(keras.layers.Layer):
def __init__(self, rate=1e-2):
super(ActivityRegularizationLayer, self).__init__()
self.rate = rate
def call(self, inputs):
self.add_loss(self.rate * tf.reduce_sum(inputs))
return inputs
这些损失(包括由任何内部层产生的损失)可以通过layer.losses进行检索。 此属性在每个__call __()的开始处重置为顶层,因此layer.losses始终包含在上一次正向传递过程中创建的损耗值。
class OuterLayer(keras.layers.Layer):
def __init__(self):
super(OuterLayer, self).__init__()
self.activity_reg = ActivityRegularizationLayer(1e-2)
def call(self, inputs):
return self.activity_reg(inputs)
layer = OuterLayer()
assert len(layer.losses) == 0 # No losses yet since the layer has never been called
_ = layer(tf.zeros(1, 1))
assert len(layer.losses) == 1 # We created one loss value
# `layer.losses` gets reset at the start of each __call__
_ = layer(tf.zeros(1, 1))
assert len(layer.losses) == 1 # This is the loss created during the call above
此外,loss属性还包含为任何内层的权重创建的正则化损失:
class OuterLayerWithKernelRegularizer(keras.layers.Layer):
def __init__(self):
super(OuterLayerWithKernelRegularizer, self).__init__()
self.dense = keras.layers.Dense(
32, kernel_regularizer=tf.keras.regularizers.l2(1e-3)
)
def call(self, inputs):
return self.dense(inputs)
layer = OuterLayerWithKernelRegularizer()
_ = layer(tf.zeros((1, 1)))
# This is `1e-3 * sum(layer.dense.kernel ** 2)`,
# created by the `kernel_regularizer` above.
print(layer.losses)

在编写训练循环时应考虑这些损失,如下所示:
# Instantiate an optimizer.
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3)
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# Iterate over the batches of a dataset.
for x_batch_train, y_batch_train in train_dataset:
with tf.GradientTape() as tape:
logits = layer(x_batch_train) # Logits for this minibatch
# Loss value for this minibatch
loss_value = loss_fn(y_batch_train, logits)
# Add extra losses created during this forward pass:
loss_value += sum(model.losses)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
有关编写训练循环的详细指南,请参阅从头开始编写训练循环的指南。
这些损失还可以通过fit()无缝工作(它们会自动求和并添加到主要损失中,如果有的话):
import numpy as np
inputs = keras.Input(shape=(3,))
outputs = ActivityRegularizationLayer()(inputs)
model = keras.Model(inputs, outputs)
# If there is a loss passed in `compile`, thee regularization
# losses get added to it
model.compile(optimizer="adam", loss="mse")
model.fit(np.random.random((2, 3)), np.random.random((2, 3)))
# It's also possible not to pass any loss in `compile`,
# since the model already has a loss to minimize, via the `add_loss`
# call during the forward pass!
model.compile(optimizer="adam")
model.fit(np.random.random((2, 3)), np.random.random((2, 3)))

add_metric()方法
与add_loss()类似,图层还具有add_metric()方法,用于在训练过程中跟踪数量的移动平均值。
考虑以下层:“logistic endpoint”层。 它以预测和目标作为输入,计算通过add_loss()跟踪的损耗,并计算通过add_metric()跟踪的精度标量。
class LogisticEndpoint(keras.layers.Layer):
def __init__(self, name=None):
super(LogisticEndpoint, self).__init__(name=name)
self.loss_fn = keras.losses.BinaryCrossentropy(from_logits=True)
self.accuracy_fn = keras.metrics.BinaryAccuracy()
def call(self, targets, logits, sample_weights=None):
# Compute the training-time loss value and add it
# to the layer using `self.add_loss()`.
loss = self.loss_fn(targets, logits, sample_weights)
self.add_loss(loss)
# Log accuracy as a metric and add it
# to the layer using `self.add_metric()`.
acc = self.accuracy_fn(targets, logits, sample_weights)
self.add_metric(acc, name="accuracy")
# Return the inference-time prediction tensor (for `.predict()`).
return tf.nn.softmax(logits)
可通过layer.metrics访问以这种方式跟踪的指标:
layer = LogisticEndpoint()
targets = tf.ones((2, 2))
logits = tf.ones((2, 2))
y = layer(targets, logits)
print("layer.metrics:", layer.metrics)
print("current accuracy value:", float(layer.metrics[0].result()))

就像add_loss()一样,这些指标也可以通过fit()进行跟踪:
inputs = keras.Input(shape=(3,), name="inputs")
targets = keras.Input(shape=(10,), name="targets")
logits = keras.layers.Dense(10)(inputs)
predictions = LogisticEndpoint(name="predictions")(logits, targets)
model = keras.Model(inputs=[inputs, targets], outputs=predictions)
model.compile(optimizer="adam")
data = {
"inputs": np.random.random((3, 3)),
"targets": np.random.random((3, 10)),
}
model.fit(data)

您可以选择在图层上启用序列化
如果需要将自定义图层作为功能模型的一部分进行序列化,则可以选择实现get_config()方法:
class Linear(keras.layers.Layer):
def __init__(self, units=32):
super(Linear, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
)
self.b = self.add_weight(
shape=(self.units,), initializer="random_normal", trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
return {"units": self.units}
# Now you can recreate the layer from its config:
layer = Linear(64)
config = layer.get_config()
print(config)
new_layer = Linear.from_config(config)
{‘units’: 64}
请注意,基本Layer类的__init __()方法采用一些关键字参数,尤其是名称和dtype。 优良作法是将这些参数传递给__init __()中的父类,并将其包含在层配置中:
class Linear(keras.layers.Layer):
def __init__(self, units=32, **kwargs):
super(Linear, self).__init__(**kwargs)
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
)
self.b = self.add_weight(
shape=(self.units,), initializer="random_normal", trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
config = super(Linear, self).get_config()
config.update({"units": self.units})
return config
layer = Linear(64)
config = layer.get_config()
print(config)
new_layer = Linear.from_config(config)
{‘name’: ‘linear_8’, ‘trainable’: True, ‘dtype’: ‘float32’, ‘units’: 64}
如果在从其配置反序列化图层时需要更大的灵活性,则还可以重写from_config()类方法。 这是from_config()的基本实现:
def from_config(cls, config):
return cls(**config)
要了解有关序列化和保存的更多信息,请参阅有关模型保存和序列化的完整指南。
call()方法中的特权 training 参数
某些层,尤其是BatchNormalization层和Dropout层,在训练和推理期间具有不同的行为。 对于此类层,标准做法是在call()方法中公开training(布尔)参数。
通过在call()中公开此参数,可以启用内置的训练和评估循环(例如fit())以在训练和推理中正确使用该图层。
class CustomDropout(keras.layers.Layer):
def __init__(self, rate, **kwargs):
super(CustomDropout, self).__init__(**kwargs)
self.rate = rate
def call(self, inputs, training=None):
if training:
return tf.nn.dropout(inputs, rate=self.rate)
return inputs
call()方法中的特权mask参数
call()支持的另一个特权参数是mask参数。
您会在所有Keras RNN图层中找到它。 mask是布尔张量(输入中每个时间步长一个布尔值),用于在处理时间序列数据时跳过某些输入时间步长。
当先前的图层生成遮罩时,Keras会自动将正确的mask参数传递给支持该图层的__call __()。mask生成层是配置有mask_zero = True的“ Embedding”层和“ Masking”层。
要了解有关 masking以及如何编写启用了 masking的图层的更多信息,请查看指南“了解padding和 masking”。
模型类
通常,您将使用Layer类来定义内部计算块,并使用Model类来定义外部模型-您将训练的对象。
例如,在ResNet50模型中,您将有几个ResNet块子类化Layer,而一个 Model则包含了整个ResNet50网络。
Model类具有与Layer相同的API,但有以下区别:
- 它公开了内置的训练,评估和预测循环(model.fit(),model.evaluate(),model.predict())。
- 它通过model.layers属性公开其内层的列表。
- 它公开了保存和序列化API(save(),save_weights()…)
实际上,Layer类对应于我们在文献中所称的“层”(如“卷积层”或“递归层”)或“块”(如“ ResNet块”或“ Inception块”) )。
同时,Model类对应于文献中所谓的“模型”(如“深度学习模型”)或“网络”(如“深度神经网络”)。
因此,如果您想知道“我应该使用Layer类还是Model类?”,请问自己:我需要在其上调用fit()吗?我需要在上面调用save()吗?如果是这样,请选择模型。如果不是(因为您的课程只是更大系统中的一个块,或者因为您自己编写训练和保存代码),请使用Layer。
例如,我们可以以上面的mini-resnet示例为例,并使用它来构建一个模型,该模型可以通过fit()进行训练,并可以通过save_weights()保存:
class ResNet(tf.keras.Model):
def __init__(self):
super(ResNet, self).__init__()
self.block_1 = ResNetBlock()
self.block_2 = ResNetBlock()
self.global_pool = layers.GlobalAveragePooling2D()
self.classifier = Dense(num_classes)
def call(self, inputs):
x = self.block_1(inputs)
x = self.block_2(x)
x = self.global_pool(x)
return self.classifier(x)
resnet = ResNet()
dataset = ...
resnet.fit(dataset, epochs=10)
resnet.save(filepath)
放在一起:端到端的例子
到目前为止,您已经学到了以下内容:
- 层封装状态(在__init __()或build()中创建)和一些计算(在call()中定义)。
- 可以递归嵌套图层以创建更大的新计算块。
- 层可以通过add_loss()和add_metric()创建和跟踪损失(通常是正则化损失)以及指标
- 您要训练的外部容器是模型。 模型就像一个图层,但是增加了训练和序列化实用程序。
让我们将所有这些内容放到一个端到端的示例中:我们将实现一个变体自动编码器(VAE)。 我们将用MNIST数字对其进行训练。
我们的VAE将是Model的子类,它是作为Layer的子类的嵌套嵌套层构建的。 它将具有正则化损失(KL散度)。
class Sampling(layers.Layer):
"""Uses (z_mean, z_log_var) to sample z, the vector encoding a digit."""
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
class Encoder(layers.Layer):
"""Maps MNIST digits to a triplet (z_mean, z_log_var, z)."""
def __init__(self, latent_dim=32, intermediate_dim=64, name="encoder", **kwargs):
super(Encoder, self).__init__(name=name, **kwargs)
self.dense_proj = layers.Dense(intermediate_dim, activation="relu")
self.dense_mean = layers.Dense(latent_dim)
self.dense_log_var = layers.Dense(latent_dim)
self.sampling = Sampling()
def call(self, inputs):
x = self.dense_proj(inputs)
z_mean = self.dense_mean(x)
z_log_var = self.dense_log_var(x)
z = self.sampling((z_mean, z_log_var))
return z_mean, z_log_var, z
class Decoder(layers.Layer):
"""Converts z, the encoded digit vector, back into a readable digit."""
def __init__(self, original_dim, intermediate_dim=64, name="decoder", **kwargs):
super(Decoder, self).__init__(name=name, **kwargs)
self.dense_proj = layers.Dense(intermediate_dim, activation="relu")
self.dense_output = layers.Dense(original_dim, activation="sigmoid")
def call(self, inputs):
x = self.dense_proj(inputs)
return self.dense_output(x)
class VariationalAutoEncoder(keras.Model):
"""Combines the encoder and decoder into an end-to-end model for training."""
def __init__(
self,
original_dim,
intermediate_dim=64,
latent_dim=32,
name="autoencoder",
**kwargs
):
super(VariationalAutoEncoder, self).__init__(name=name, **kwargs)
self.original_dim = original_dim
self.encoder = Encoder(latent_dim=latent_dim, intermediate_dim=intermediate_dim)
self.decoder = Decoder(original_dim, intermediate_dim=intermediate_dim)
def call(self, inputs):
z_mean, z_log_var, z = self.encoder(inputs)
reconstructed = self.decoder(z)
# Add KL divergence regularization loss.
kl_loss = -0.5 * tf.reduce_mean(
z_log_var - tf.square(z_mean) - tf.exp(z_log_var) + 1
)
self.add_loss(kl_loss)
return reconstructed
让我们在MNIST上编写一个简单的训练循环:
original_dim = 784
vae = VariationalAutoEncoder(original_dim, 64, 32)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
mse_loss_fn = tf.keras.losses.MeanSquaredError()
loss_metric = tf.keras.metrics.Mean()
(x_train, _), _ = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype("float32") / 255
train_dataset = tf.data.Dataset.from_tensor_slices(x_train)
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
epochs = 2
# Iterate over epochs.
for epoch in range(epochs):
print("Start of epoch %d" % (epoch,))
# Iterate over the batches of the dataset.
for step, x_batch_train in enumerate(train_dataset):
with tf.GradientTape() as tape:
reconstructed = vae(x_batch_train)
# Compute reconstruction loss
loss = mse_loss_fn(x_batch_train, reconstructed)
loss += sum(vae.losses) # Add KLD regularization loss
grads = tape.gradient(loss, vae.trainable_weights)
optimizer.apply_gradients(zip(grads, vae.trainable_weights))
loss_metric(loss)
if step % 100 == 0:
print("step %d: mean loss = %.4f" % (step, loss_metric.result()))
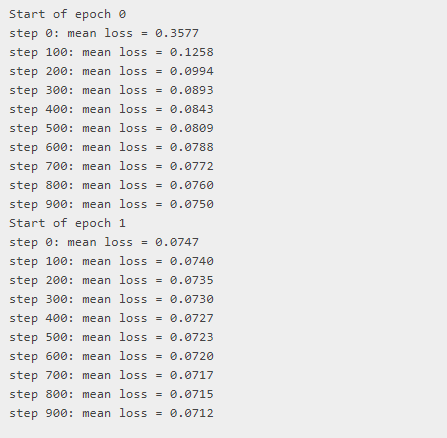
请注意,由于VAE是Model的子类,因此它具有内置的训练循环。 因此,您也可以像这样训练它:
vae = VariationalAutoEncoder(784, 64, 32)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
vae.compile(optimizer, loss=tf.keras.losses.MeanSquaredError())
vae.fit(x_train, x_train, epochs=2, batch_size=64)
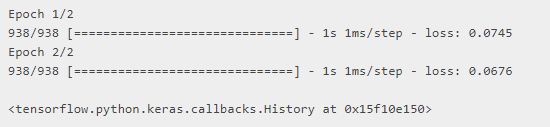
超越面向对象的开发:Functional API
这个示例对您来说是太多的面向对象开发吗? 您也可以使用Functional API构建模型。 重要的是,选择一种样式或另一种样式不会阻止您利用以另一种样式编写的组件:您始终可以混合搭配。
例如,下面的Functional API示例重用了我们在上面示例中定义的相同采样层:
original_dim = 784
intermediate_dim = 64
latent_dim = 32
# Define encoder model.
original_inputs = tf.keras.Input(shape=(original_dim,), name="encoder_input")
x = layers.Dense(intermediate_dim, activation="relu")(original_inputs)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
z = Sampling()((z_mean, z_log_var))
encoder = tf.keras.Model(inputs=original_inputs, outputs=z, name="encoder")
# Define decoder model.
latent_inputs = tf.keras.Input(shape=(latent_dim,), name="z_sampling")
x = layers.Dense(intermediate_dim, activation="relu")(latent_inputs)
outputs = layers.Dense(original_dim, activation="sigmoid")(x)
decoder = tf.keras.Model(inputs=latent_inputs, outputs=outputs, name="decoder")
# Define VAE model.
outputs = decoder(z)
vae = tf.keras.Model(inputs=original_inputs, outputs=outputs, name="vae")
# Add KL divergence regularization loss.
kl_loss = -0.5 * tf.reduce_mean(z_log_var - tf.square(z_mean) - tf.exp(z_log_var) + 1)
vae.add_loss(kl_loss)
# Train.
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
vae.compile(optimizer, loss=tf.keras.losses.MeanSquaredError())
vae.fit(x_train, x_train, epochs=3, batch_size=64)
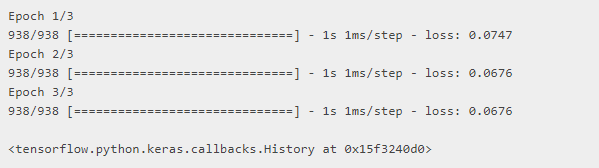
有关更多信息,请确保阅读Functional API指南。

















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









