









 本文详细介绍了如何在大数据物流项目中进行实时增量ETL,将数据存储到Kudu的过程。涵盖了从CanalBean转换为POJO,通过SparkSQL进行数据转换,以及如何根据opType字段优化数据保存。文章还涉及到Kudu表的创建、数据保存以及UDF函数的使用。
本文详细介绍了如何在大数据物流项目中进行实时增量ETL,将数据存储到Kudu的过程。涵盖了从CanalBean转换为POJO,通过SparkSQL进行数据转换,以及如何根据opType字段优化数据保存。文章还涉及到Kudu表的创建、数据保存以及UDF函数的使用。
文章目录
- Logistics_Day09:实时增量ETL存储Kudu
-
- 01-[复习]-上次课程内容回顾
- 02-[了解]-第9天:课程内容提纲
- 03-[掌握]-实时ETL开发之CanalBean转换POJO
- 04-[掌握]-实时ETL开发之转换POJO【重构代码】
- 05-[掌握]-实时ETL开发之Bean转换POJO【编程测试】
- 06-[掌握]-实时ETL开发之保存Kudu表【save方法】
- 07-[理解]-实时ETL开发之保存Kudu表【KuduTools】
- 08-[掌握]-实时ETL开发之保存Kudu表【CRM数据测试】
- 09-[掌握]-实时ETL开发之保存Kudu表【opType优化】
- 10-[掌握]-实时ETL开发之保存Kudu表【实时数据测试】
- 11-[掌握]-实时ETL开发之UDF函数使用
Logistics_Day09:实时增量ETL存储Kudu
01-[复习]-上次课程内容回顾
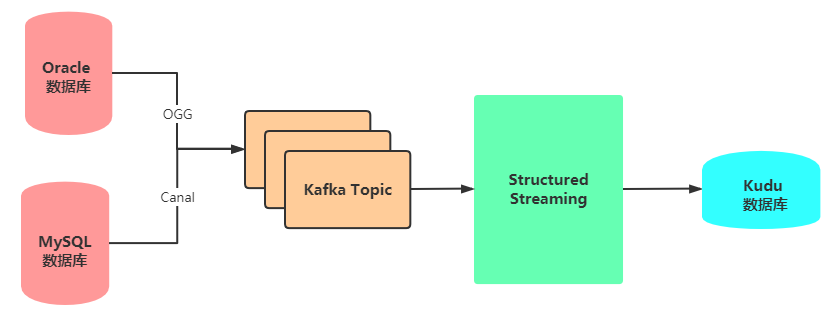
物流项目数据实时ETL转换开发(存储Kudu数据库)部分功能:消费Kafka数据及ETL转换(JSON->Bean对象),项目开发环境搭建(初始化)。
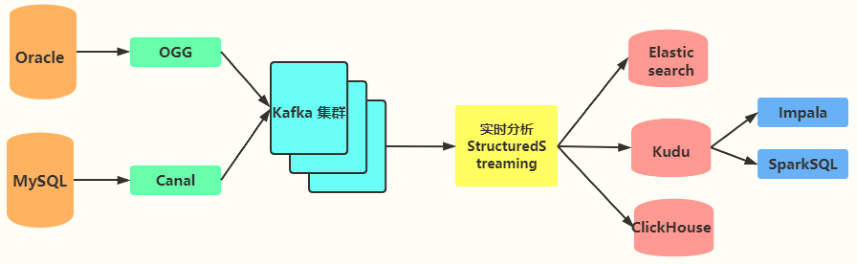
主要讲解如何对实时消费业务数据进行ETL转换:
- 第一步、JSON字符串转换为Bean对象
Canal采集:12个字段,封装到CanalMessageBean对象
OGG采集:7个字段(INSERT和DELETE:6个,UPDATe:7个),封装到OggMessageBean对象
技术实现:

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











