



 博客围绕MNIST数据集的分类简单版本展开,介绍了改进方法,包括改变批次大小为200、增加隐藏层、使用交叉熵函数(给出了具体代码)、改变学习率为0.2以及调整学习次数等内容。
博客围绕MNIST数据集的分类简单版本展开,介绍了改进方法,包括改变批次大小为200、增加隐藏层、使用交叉熵函数(给出了具体代码)、改变学习率为0.2以及调整学习次数等内容。
#MNIST数据集的分类简单版本
- 案例:
import tensorflow.examples.tutorials.mnist.input_data as input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data", one_hot = True)
#每个批次的大小
batch_size = 100
#计算一共又多少个批次
n_batch = mnist.train.num_examples // batch_size
#定义两个placeholer
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
#创建一个神经网络
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
predict = tf.nn.softmax(tf.matmul(x, W) + b)
#二次代价函数
loss = tf.reduce_mean(tf.square(y - predict))
#使用梯度下降法
train = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 【Tensorflow】 tf.equal(tf.argmax(y, 1),tf.argmax(y_, 1))用法
# 作用:输出正确的预测结果
# 利用tf.argmax()按行求出真实值y_、预测值y最大值的下标,
# 用tf.equal()求出真实值和预测值相等的数量,也就是预测结果正确的数量
# tf.argmax()和tf.equal()一般是结合着用。
#结果放在一个布尔型列表中,argmax返回一维张量中最大值所在位置
correct_prediction = tf.equal(tf.argmax(predict,1), tf.argmax(y,1)) #输出正确的预测结果
# tf.cast()函数的作用是执行 tensorflow 中张量数据类型转换,
# 比如读入的图片如果是int8类型的,一般在要在训练前把图像的数据格式转换为float32。
accuracy = tf.reduce_mean(tf.cast(correct_prediction,'float'))#执行 tensorflow 中张量数据类型转换
init = tf.global_variables_initializer()
#batch_size:中文翻译为批大小(批尺寸)。即每次训练在训练集中取batchsize个样本训练;
#epoch:迭代次数,1个epoch等于使用训练集中的全部样本训练一次;
# 一个epoch = 所有训练样本的一个正向传递和一个反向传递
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):#迭代次数,这里迭代21次,使用训练集中全部样本训练21次
for batch in range(n_batch):#本次循环表示把所有的图片都训练了一次
#batch_size:每次取出100,batch_xs:获得100张图片保存,batch_y:获得图片标签
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train, feed_dict={x:batch_xs, y:batch_ys})#把所有训练集的数据输入进去,用feed_dict方法
#把测试集中的数据输入进去,测试集中的图片和测试集中的标签
acc = sess.run(accuracy, feed_dict={x:mnist.test.images,y:mnist.test.labels})
print("Iter" + str(epoch) + ",Testing Accuracy" + str(acc))
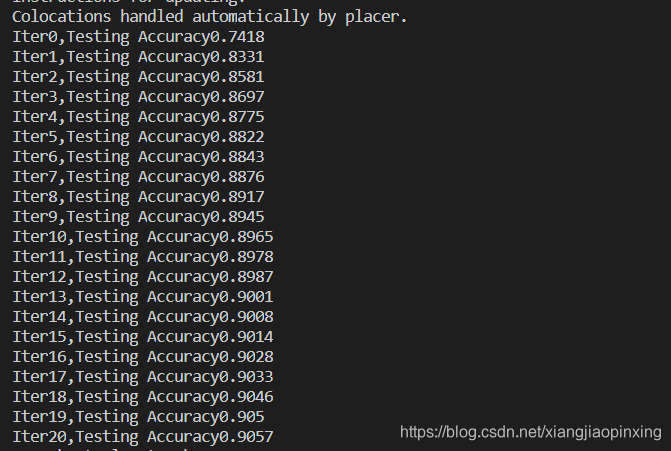
2、改进:
可以在以下方法中改进:
1.改变批次大小(200)
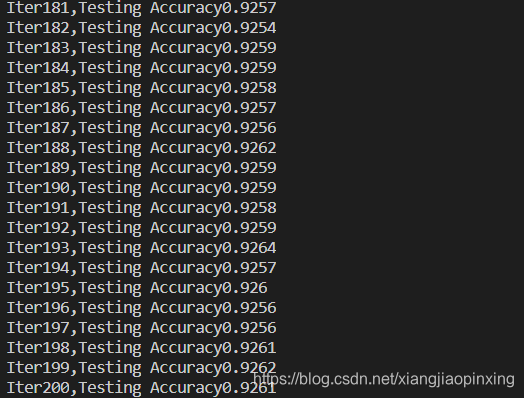
2.增加隐藏层
3.使用交叉熵
#交叉熵函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits = predict))
4.改变学习率(0.2)
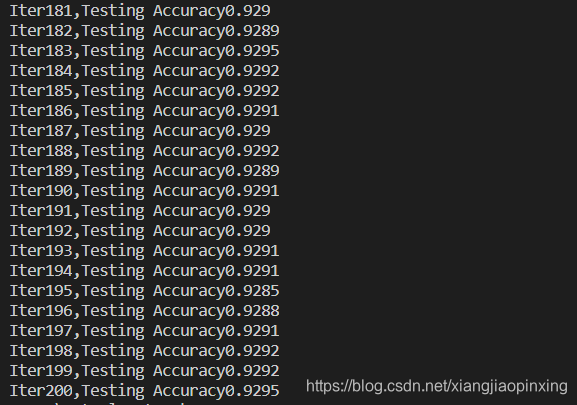
5.学习次数


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









