




 本文详细介绍了Kafka的高级特性,包括生产者ACK机制(0,1,all级别)在数据可靠性上的作用,以及如何通过分布式复制、ISR机制、同步复制和ISR扩展来解决数据一致性问题。
本文详细介绍了Kafka的高级特性,包括生产者ACK机制(0,1,all级别)在数据可靠性上的作用,以及如何通过分布式复制、ISR机制、同步复制和ISR扩展来解决数据一致性问题。
Kafka高级_生产者ACk机制&数据一致性问题
Survive by day and develop by night.
talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive.
happy for hardess to solve denpendies.
目录
需求:
设计思路
假设我们有一个Kafka集群,其中包含一个主题(Topic1)和两个分区(Partition1和Partition2)。每个分区都有两个副本,其中一个是领导者副本(Leader Replica),另一个是追随者副本(Follower Replica)。
-
ACK = 0:
如果生产者设置了ACK参数为0,则生产者发送消息后不会等待任何确认。消息会立即被视为成功发送,但可能会导致消息丢失的风险。 -
ACK = 1:
如果生产者设置了ACK参数为1,则生产者会等待领导者副本确认消息。一旦消息被领导者副本确认,生产者会认为消息已经成功发送。但是如果领导者副本在确认之前出现故障,可能会导致消息丢失。 -
ACK = all/-1:
如果生产者设置了ACK参数为all或-1,则生产者会等待所有分区副本(包括领导者副本和追随者副本)都确认消息。只有在所有副本确认之后,生产者才认为消息成功发送。这种设置提供了最高的数据可靠性,因为即使领导者副本发生故障,仍然可以从追随者副本中读取数据。
数据一致性保证:
对于数据一致性问题,Kafka使用分布式复制机制来保证。领导者副本处理所有的读写请求,并将写入的数据复制给追随者副本。这样,即使领导者副本出现故障,追随者副本可以接替成为新的领导者。通过这种复制机制,保证了数据的一致性和可用性。
实现思路分析
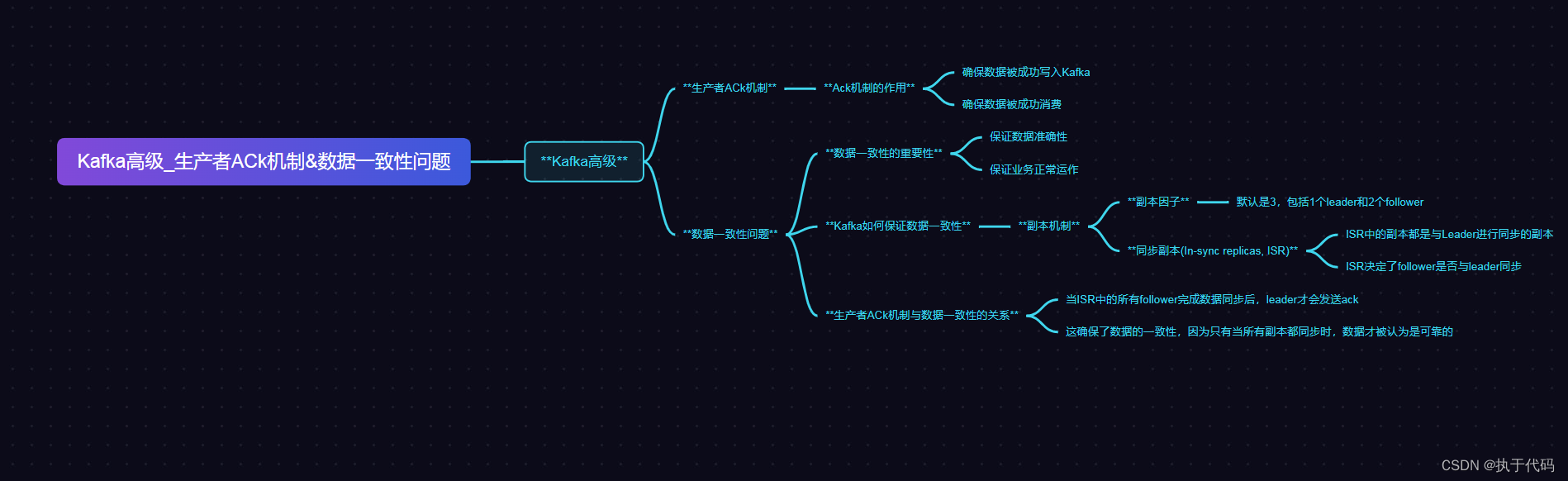
1.Kafka高级_生产者ACk机制
Kafka高级生产者ACK机制是保证消息发送的可靠性的一种机制。在Kafka中,ACK(Acknowledgment)代表了消息的确认机制,用于确认消息是否发送成功。
Kafka生产者发送消息时,会指定ACK的级别。ACK有三个级别:
-
acks=0:生产者不等待服务器的响应,将消息发送到Kafka集群后立即返回,不保证消息是否发送成功。这种方式可能会导致消息丢失,不推荐使用。
-
acks=1:生产者在消息发送到Kafka集群后,会等待Leader副本确认消息发送成功后再返回。这种方式可以保证消息发送的可靠性,但可能会存在一定的数据丢失的风险。
-
acks=all:生产者在消息发送到Kafka集群后,会等待所有副本确认消息发送成功后才返回。这种方式可以最大程度地保证消息发送的可靠性,但会增加延迟和降低吞吐量。
根据实际业务需求和系统性能要求,可以选择适合的ACK级别。通常情况下,对于重要的数据,推荐使用acks=all机制,以确保数据不丢失。而对于一些实时性要求较高、可以容忍少量数据丢失的场景,可以选择acks=1机制。
2.Kafka高级数据一致性问题
Kafka是一个分布式的消息队列系统,具有高吞吐量、低延迟和强大的持久性特性。然而,由于其分布式特性,Kafka在保证数据一致性方面存在一些挑战。
首先,Kafka使用了副本机制来实现数据的容错和持久性。每个分区都有多个副本,其中一个被选为领导者,负责处理所有的读写请求,其余副本作为追随者,只负责与领导者进行数据同步。在写入数据时,领导者会将数据写入本地磁盘,并异步地复制给追随者。因此,在领导者写入数据之后,追随者可能还没有完全同步,这导致了部分数据一致性的问题。
其次,Kafka采用了异步复制的方式进行数据复制。这意味着,当领导者将数据写入本地磁盘后,并不会等待追随者的复制完成,而是立即返回成功响应。这样可以减少延迟,提高吞吐量,但也会导致数据在多个副本之间存在一定的延迟,从而可能出现数据不一致的情况。
为了解决这些 数据一致性问题,Kafka提供了一些机制:
-
ISR(In-Sync Replicas)机制:Kafka定义了一个概念叫做ISR,即与领导者保持同步的副本集合。只有处于ISR中的副本才能被选为新的领导者。当追随者与领导者之间的复制延迟过高时,追随者将被自动踢出ISR,这样可以避免延迟过高的副本对数据一致性造成影响。
-
同步复制机制:Kafka支持同步复制模式,即在写入数据时等待追随者完成数据复制。这样可以保证数据在多个副本之间的一致性,但也会增加延迟和降低吞吐量。
-
ISR扩展机制:Kafka还提供了ISR扩展机制,即允许用户自定义ISR中的副本数量。通过增加ISR中的副本数量,可以提高数据的容错性和可用性,但也会增加复制延迟。
总的来说,Kafka在追求高吞吐量和低延迟的同时,还兼顾了数据一致性的问题。通过ISR机制、同步复制机制和ISR扩展机制,可以在不同的场景下权衡吞吐量和一致性的需求。
参考资料和推荐阅读
参考资料
官方文档
开源社区
博客文章
书籍推荐
欢迎阅读,各位老铁,如果对你有帮助,点个赞加个关注呗!同时,期望各位大佬的批评指正~,如果有兴趣,可以加文末的交流群,大家一起进步哈


















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











