



 本文介绍了一种利用百度API进行摄像头文字识别的方法,通过高精度识别技术,实现了康复病人仪器数据的自动抓取与传输,减轻了夜班护士的工作压力。文章详细描述了从准备工作到代码实现的全过程。
本文介绍了一种利用百度API进行摄像头文字识别的方法,通过高精度识别技术,实现了康复病人仪器数据的自动抓取与传输,减轻了夜班护士的工作压力。文章详细描述了从准备工作到代码实现的全过程。
关于文字识别
朋友想通过搭建一个平台来观察康复病人的状况以此减少夜班护士的工作压力,想到能不能用摄像头抓取识别仪器上的数据,并将数据传输到平台供护士随时查看的功能,本着证实事情的可行性,我开始了测试。
之前我尝试能否自己使用pytesseract+tesseractOCR来识做文字处理(本意是自己做一个摄像头能够自动抓取来文字识别的小demo来玩玩),但是识别效果感人, 用jTessBoxEditor经过几天的琢磨和的训练,识别精度还是不理想,无论是模型还是训练我的水平远远达不到。
于是放弃了自己训练的想法,直接调用了百度的api,高精度识别,识别效果很好。
五分钟准备工作:
准备工作
调用百度API需要验证,它提供每天五百次免费的使用机会,对于我们这种一般人这已经足够了,下面介绍获得验证指令的方法。
登录(注册)百度智能云

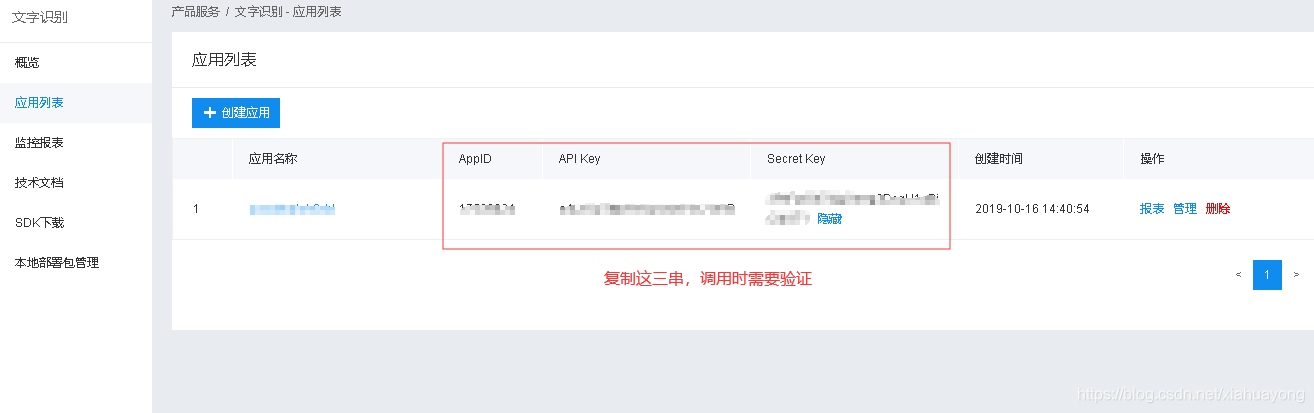
创建应用
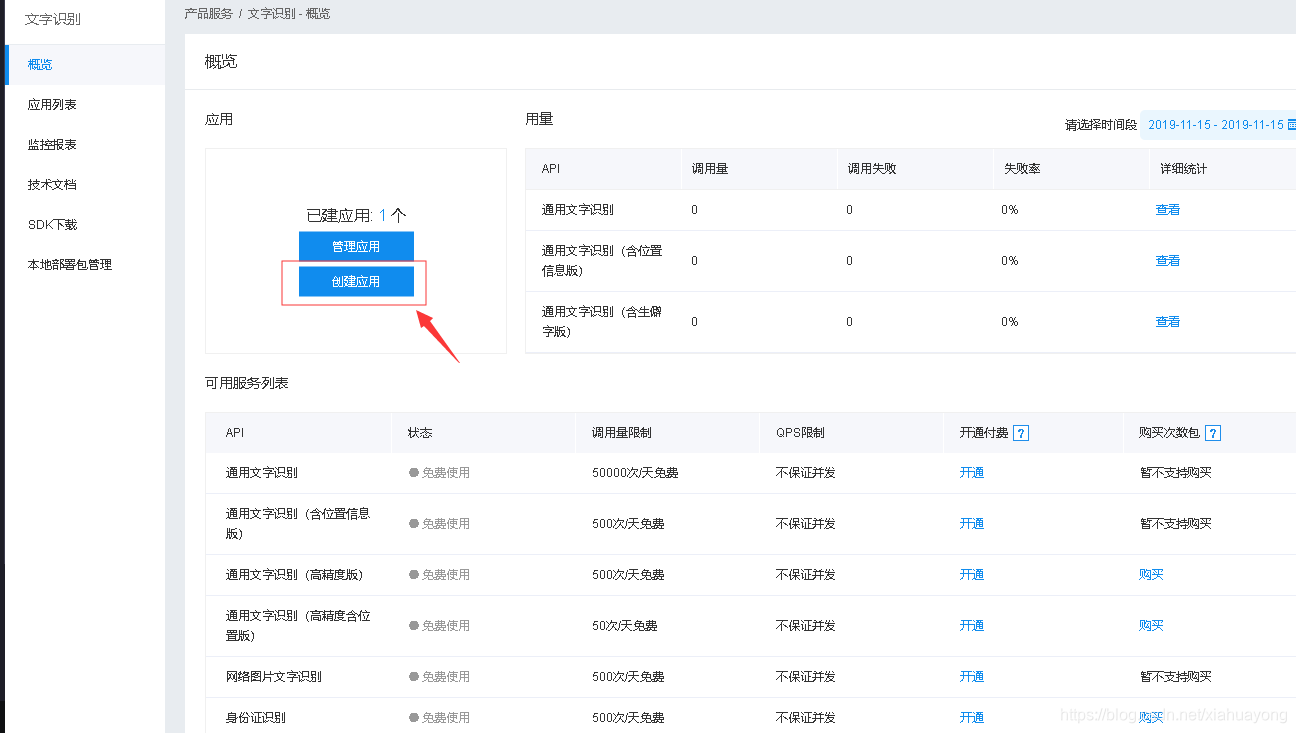
进去之后直接输入 应用名称 ,然后直接点 立即创建。
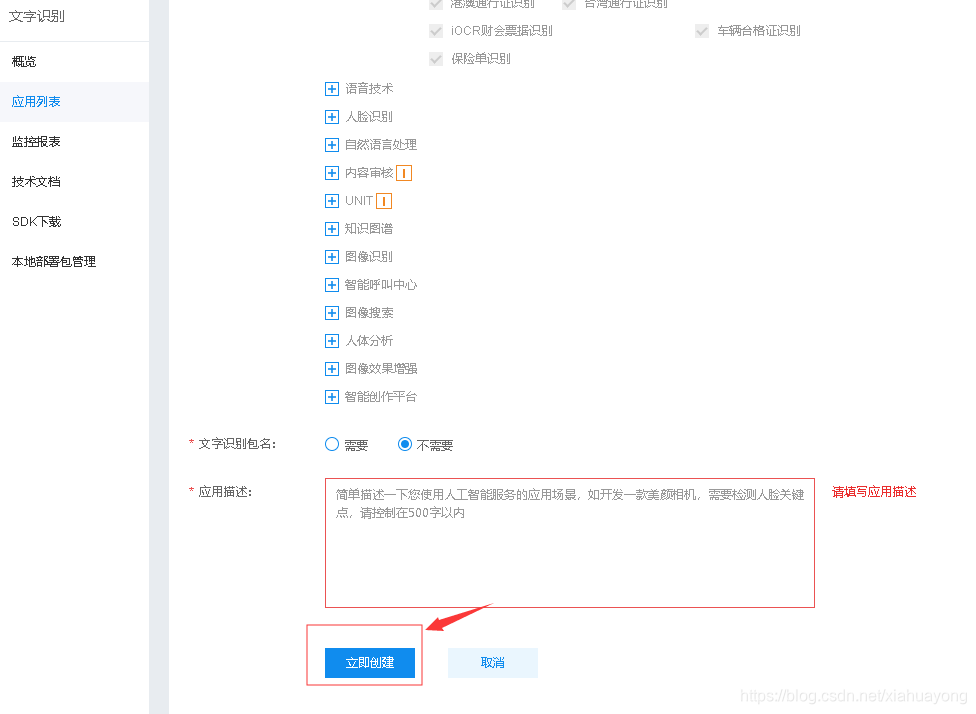
然后点击管理应用
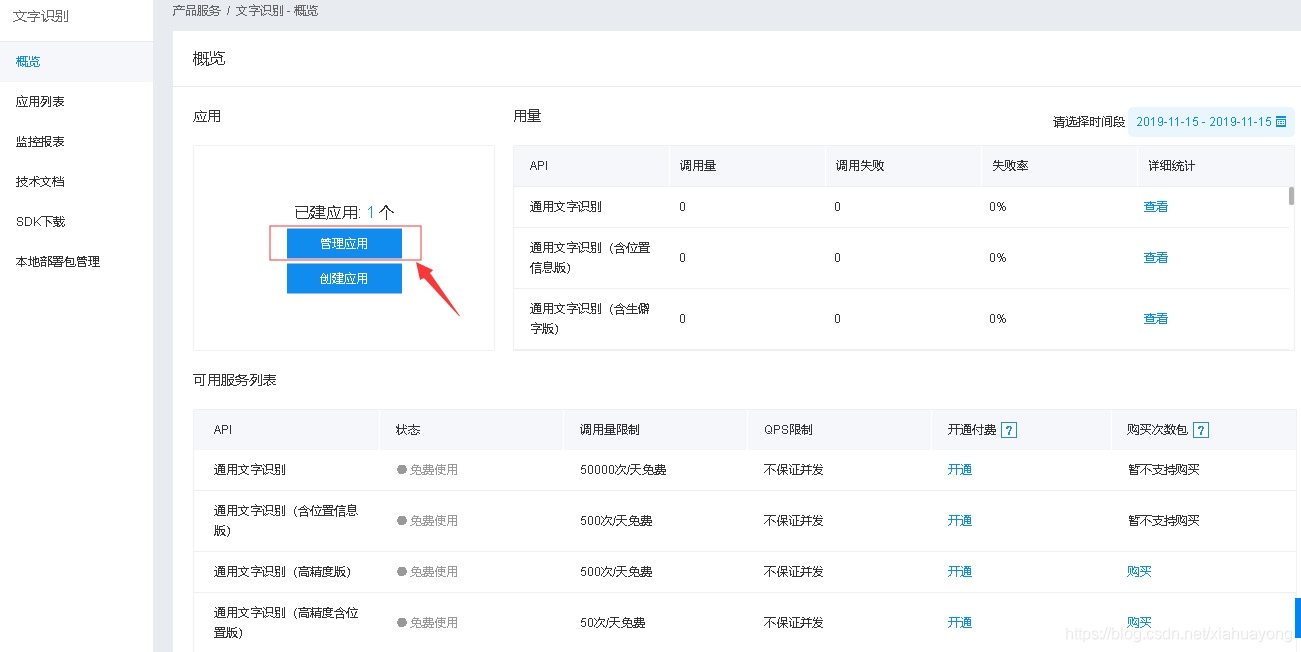
到这里就算完成了,把这三串字符copy下来后边代码需要用到
另外你需要在python中安装baidu-aip模块
安装方法如下:
pip install baidu-aip
代码实现
10分钟敲完代码
打开摄像头简单的实现文字识别,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 18 13:41:50 2019
@author: .xia
"""
import cv2
from aip import AipOcr
import re
APP_ID = '你的AppID'
API_KEY = '你的API Key'
SECRECT_KEY = '你的Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
#打开摄像头,外接无反应可以把'0'改成'1'
cap = cv2.VideoCapture(0)
i = 0
x = 1
while(1):
"""
ret:True或者False,代表有没有读取到图片
frame:表示截取到一帧的图片
"""
ret,frame = cap.read()
# 展示图片
cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)#转灰度图
cv2.imshow('capture',frame)
# 保存图片
cv2.imwrite(r'C:\test\image\i'+ str(i) + '.png',frame)
print(i)
i = i + 1
#调用图片
if i-1>x:
z =open(r'C:\test\image\i'+ str(x) +'.png','rb')
img=z.read()
#message=client.basicGeneral(img);#普通精度
message = client.basicAccurate(img) #高精度识别
#message = client.numbers(img)#高进度数字识别
for j in message.get('words_result'):
words = message['words_result']
num_list = []
for i in words:
num_list.append(i['words'])
final = []
final = final + num_list
print(final)
x = x + 1
print("`")
"""
cv2.waitKey(1):waitKey()函数功能是不断刷新图像,返回值为当前键盘的值
OxFF:是一个位掩码,一旦使用了掩码,就可以检查它是否是相应的值
ord('q'):返回q对应的unicode码对应的值(113)
按'q'关闭相机
"""
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#释放对象和销毁窗口
cap.release()
cv2.destroyAllWindows()
测试结果为与实际时间有1-3秒的延迟。
这样随意的代码当然做不出很好的功能,为了识别精度,摄像头是越高清越好!还有配合画面捕捉的优化和算法才能够达到理想的可使用的效果。
原文链接:https://blog.youkuaiyun.com/xiahuayong/article/details/103092450
相关连接:https://cloud.baidu.com/product/ocr/general

















 755
755





 到【灌水乐园】发言
到【灌水乐园】发言







