






除了基本的对文件的管理指令以外,hdfs提供了一些高级的指令如磁盘管理等指令供我们更好地去管理hdfs系统,具体来说,有如下指令:
hdfs fsck <path> [-move] [-delete]
fsck 命令可以帮助检查数据完整性,用fsck可以检查文件的块丢失情况,同时也可以删除或移动那些损坏的文件,但是它不具备修复的功能,只起到检查的作用
hdfs balancer [-threshold] 1
新加入的节点可能还没有任何数据,此时可以通过balancer命令去把整个集群的负载均衡起来,-threshold参数表示我要设置每个节点的负载差异率不超过1%
hdfs dfsadmin -refreshNode
(需要在NameNode里操作),该指令用于在数据节点发生变化的时候刷新数据节点
hdfs diskbalancer -plan <datanode_host> [-thresholdPercentage] 1
hdfs diskbalancer -execute <xxx.plan.json>
hdfs diskbalancer -query <datanode_host>
磁盘平衡可以将一个数据节点的数据在其可写磁盘间平衡,涉及到的指令分为三个:
1. 平衡计划的生成,即-plan,后面指定的host是要处理的数据节点的标识名,-thresholdPercentage是说提供一个阈值,只有多个磁盘间的存储量差异超过这个百分比才执行生成平衡计划,默认是10
2. 平衡计划的执行,生成平衡计划指令执行后,会在hdfs上生成一个json文件的路径,把那个路径拷贝到这里来执行
3. 执行磁盘平衡需要涉及大量的IO操作,故必然需要时间,所以可以用query命令来查询某个目标节点的平衡状态。
hadoop distcp <hdfs://src:9820/file_path>* <hdfs://tgt:9820/tgt_path>
hadoop distcp -f <hdfs://src:9820/src_file_path> <hdfs://tgt:9820/tgt_path>
distcp支持在不同的hadoop集群支持的hdfs之间拷贝文件,使用起来很简单,也可以在一个文件里写好所有的源文件路径信息,然后通过-f参数把这个拷贝信息文件传递给distcp,实现多对一的拷贝:路径文件信息如下:
#在 HDFS 上创建一个文件,用来存储源路径
#例如在 hdfs://namenode81:9820/distcp/src 文件中书写
hdfs://namenode01:9820/src1
hdfs://namenode01:9820/src2
hdfs://namenode01:9820/src3
hdfs archive -archiveName <归档文件名.har> -p <待归档文件的父路径> [-r <多少个副本>] <src> <tgt_path>
小文件归档,为了避免大量的小文件存在在HDFS带来的元数据堆叠占用内存问题,hdfs提供了archive工具来将许多小文件打包为一个har文件,但归档之后不会自动地删除小文件,需要用户显式删除,除此之外,归档对用户透明,用户可以通过har://<har_file_path>的url来访问归档文件中存储的小文件。har文件在hdfs中的呈现形式是一个目录,点开里面会归档文件及小文件的元数据信息以及小文件的数据信息。
动态扩展数据节点
hadoop可以在不关闭集群的情况下将新的数据节点动态扩展上线,这里以hadoop103为例完成了一个动态新增数据节点的实验。
首先在实验前检查已经存在的hadoop集群的配置:
| HostName | ip地址 | hadoopNode |
| hadoop100 | 192.168.10.100 | NameNode,DataNode |
| hadoop101 | 192.168.10.101 | SecondaryNameNode,DataNode |
| hadoop102 | 192.168.10.102 | DataNode |
现在计划新增一台虚拟机节点hadoop103:
| HostName | ip地址 | hadoopNode |
| hadoop103 | 192.168.10.103 | DataNode |
准备工作
在开始扩展之前,请确保hadoop103已经完成了以下的准备工作:
1.设置好了静态ip地址为192.168.10.103且可以访问网络
2.设置好了hostname和hosts主机映射,包括了集群里的其他节点
3.关闭了防火墙并关闭了开机自启
4.提前装好了jdk1.8并且配置了环境变量
5.提前上传了hadoop3.4.1的安装包如果网络配置成功,则如下所示:
配置其他节点的主机映射:
我们首先将hadoop103的ssh公钥发送给其他数据节点以保证ssh对其他节点免密:
ssh-copy-id hadoop100
ssh-copy-id hadoop101
ssh-copy-id hadoop102然后把103上配置好的hosts映射发送给其他节点,这里我100主节点也已经配好了就没有发
cd /etc
scp hosts hadoop100:$PWD
scp hosts hadoop101:$PWD
scp hosts hadoop102:$PWD
配置新的数据结点上的hadoop
首先将hadoop的安装包解压到/usr/local下面
tar -zxvf hadoop-3.4.1.tar.gz -C /usr/local/然后配置环境变量如下所示:
vim /etc/profile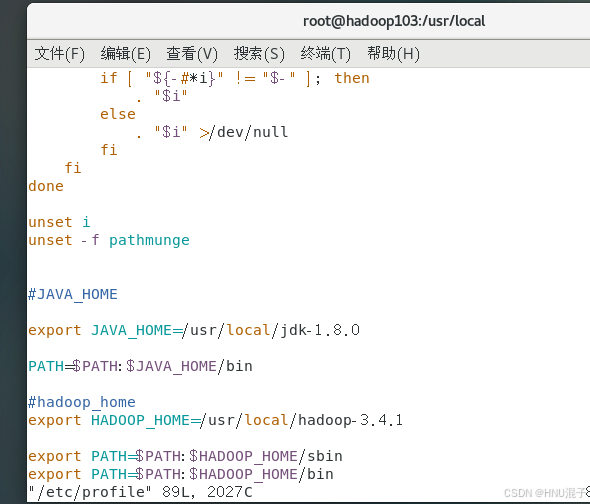
插入以下环境变量信息,已经有的可忽略
#JAVA_HOME
export JAVA_HOME=/usr/local/jdk-1.8.0
PATH=$PATH:$JAVA_HOME/bin
#hadoop_home
export HADOOP_HOME=/usr/local/hadoop-3.4.1
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
主节点配置信息更新和分发
因为新增了一个数据节点,所以需要修改主节点的配置文件workers,这里我们登录主节点的虚拟机,首先编辑workers
cd $HADOOP_HOME/etc/hadoop
vim workers在文件末尾插入hadoop103,如图所示:
然后把这个文件分发给其他原来集群中的节点,这里先不发给103,因为hadoop103的配置还没完全配,所以等一下一起发给103:
scp workers hadoop101:$PWD
scp workers hadoop102:$PWD为了能把配置信息发给103,所以也要对103做免密,然后再把配置文件夹整体发给hadoop103:
ssh-copy-id hadoop103
cd ..
scp -r hadoop hadoop103:$PWD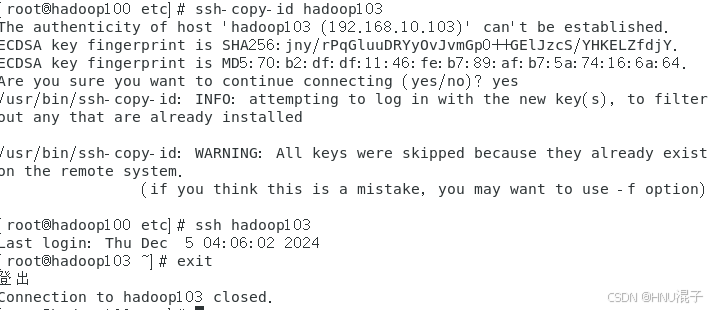
所有的配置信息已经完成了。
启动新节点
在hadoop103上使用以下命令启动新节点:
hdfs --daemon start datanode启动完之后用jps查看进程:

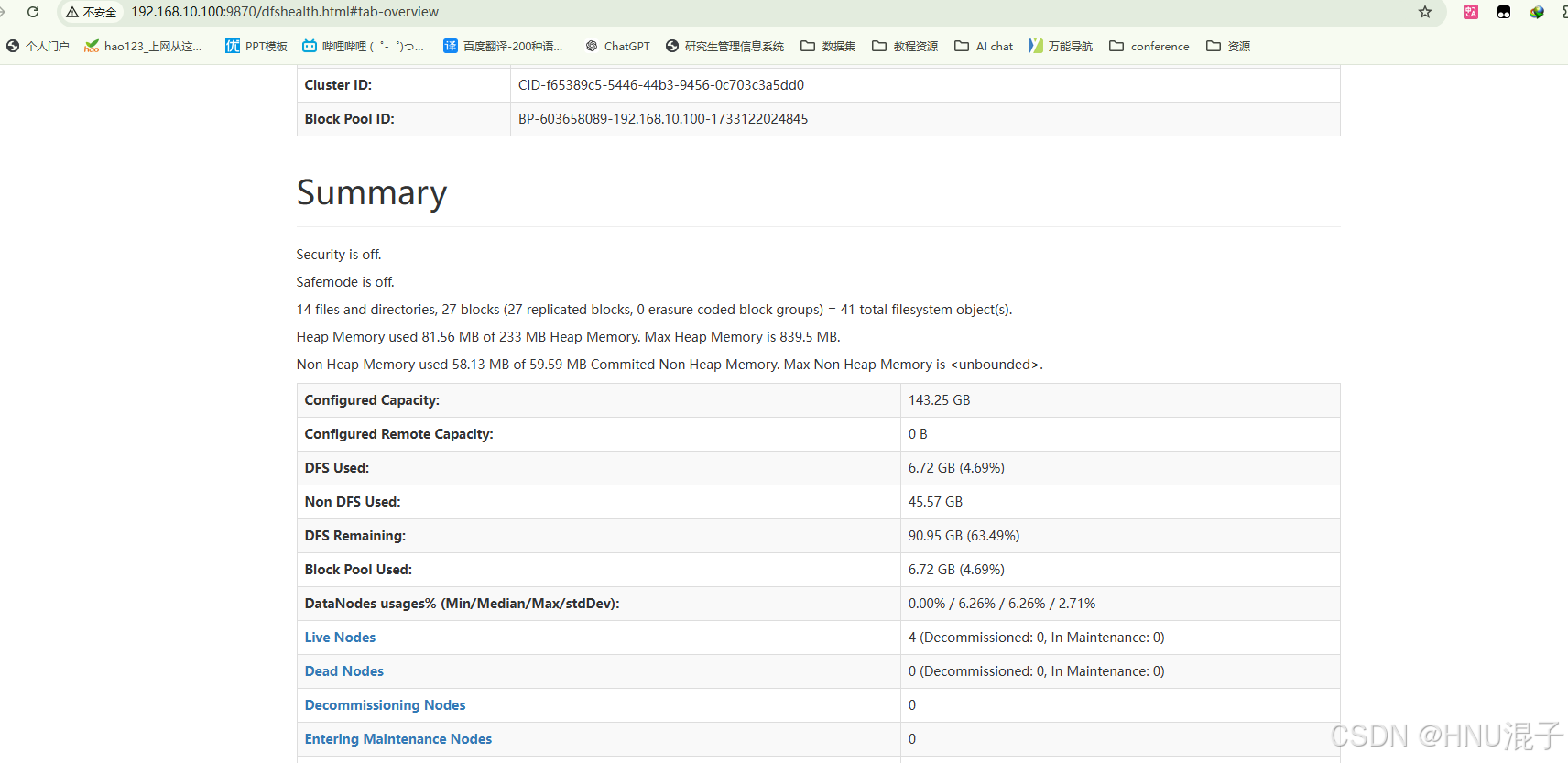
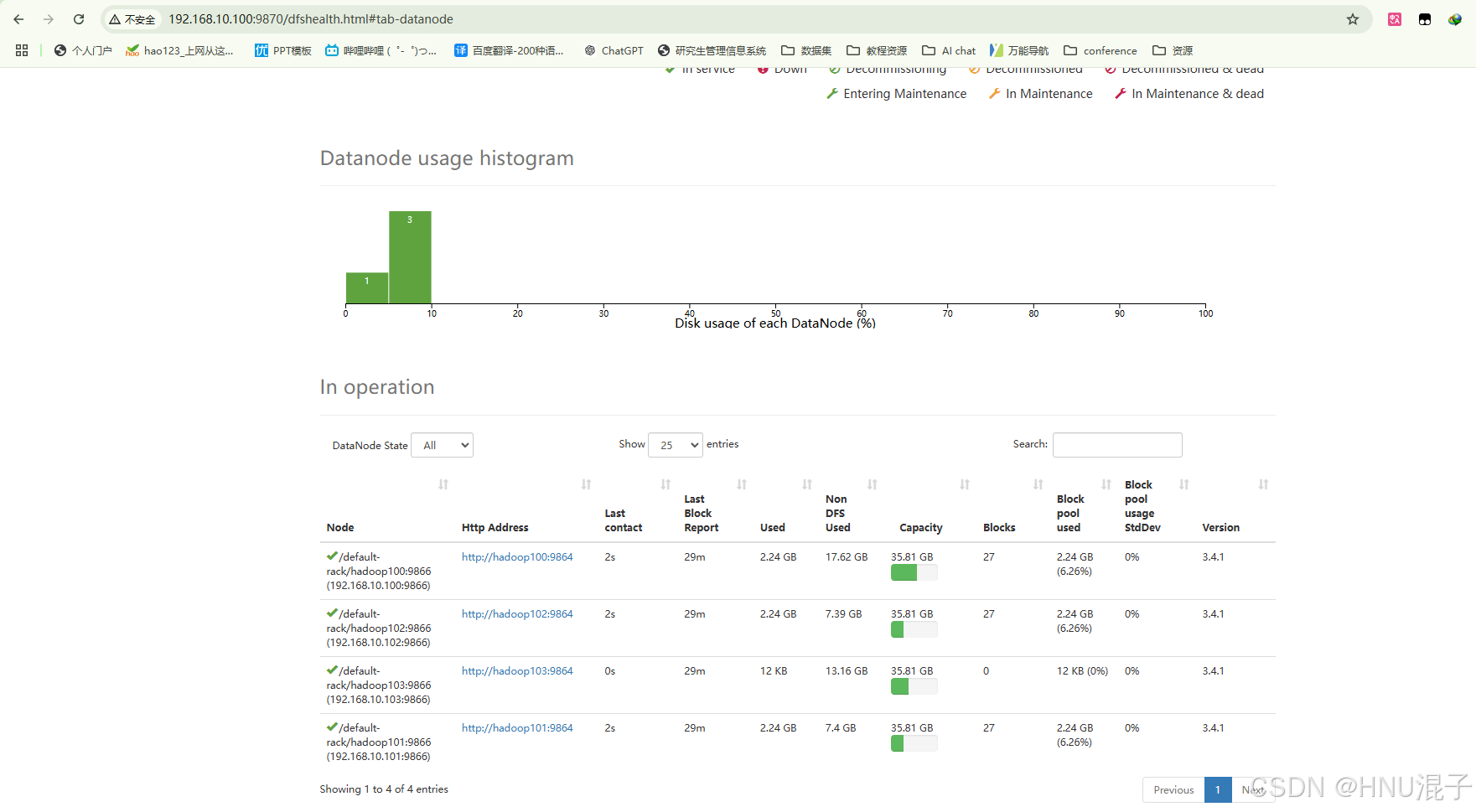
此时hadoop103已经加入集群了,你可以在网页上查看集群信息,可以看到此时live nodes已经变成4个了,同时在DataNode信息板块,可以看到此时有4个Node的信息了。后续可以通过节点负载平衡指令来调控新节点的负载。
动态下线数据节点
hadoop也可以在不关闭集群的情况下将新的数据节点动态扩展上线,这里还是以hadoop103为例完成了一个动态下线数据节点的实验。
首先在实验前检查已经存在的hadoop集群的配置:
| HostName | ip地址 | hadoopNode |
| hadoop100 | 192.168.10.100 | NameNode,DataNode |
| hadoop101 | 192.168.10.101 | SecondaryNameNode,DataNode |
| hadoop102 | 192.168.10.102 | DataNode |
| hadoop103 | 192.168.10.103 | DataNode |
这里我们需要下线的节点是hadoop103节点:
| HostName | ip地址 | hadoopNode |
| hadoop103 | 192.168.10.103 | DataNode |
配置exclude路径
在正常实际应用的过程中,节点的下线需要涉及到core-site.xml文件中的dfs.hosts.exclude属性,它的值是一个文件,一般来说,企业会在一开始配置整个集群的时候就把这个属性设置好,所以就不要在更换节点的时候修改core-site.xml导致集群重启了,这里我们是学习,所以我们可以临时关闭集群来配置这个属性。
首先来到主节点hadoop100,关闭集群:
stop-dfs.sh
然后配置主节点的core-site.xml文件:
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml插入以下信息:
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop-3.4.1/etc/hadoop/exclude</value>
<!-- exclude文件其实是一个黑名单文件,所有在这个文件里的host都被标记退役而无法参与集群工作 -->
</property>保存退出,然后在你设置的路径下touch一个新的exclude文件出来,我这里直接在当前目录配置的:
touch exclude此时这是一个空文件,然后重启集群使得配置生效:
stop-dfs.sh
start-dfs.sh动态下线
首先将要下线的主机Host输入到刚刚的exclude文件中
echo "hadoop103" >> exclude
vim exclude此时在web上看,hadoop103就已经是一个decommissioned的状态了,那么此时hadoop103就可以临时拿去维修,维修完之后再把它移出exclude文件就好了,如果后续不再参与集群,那么也可以在workers文件里面把hadoop103删除,同时也可以在exclude文件里把hadoop103删除了。

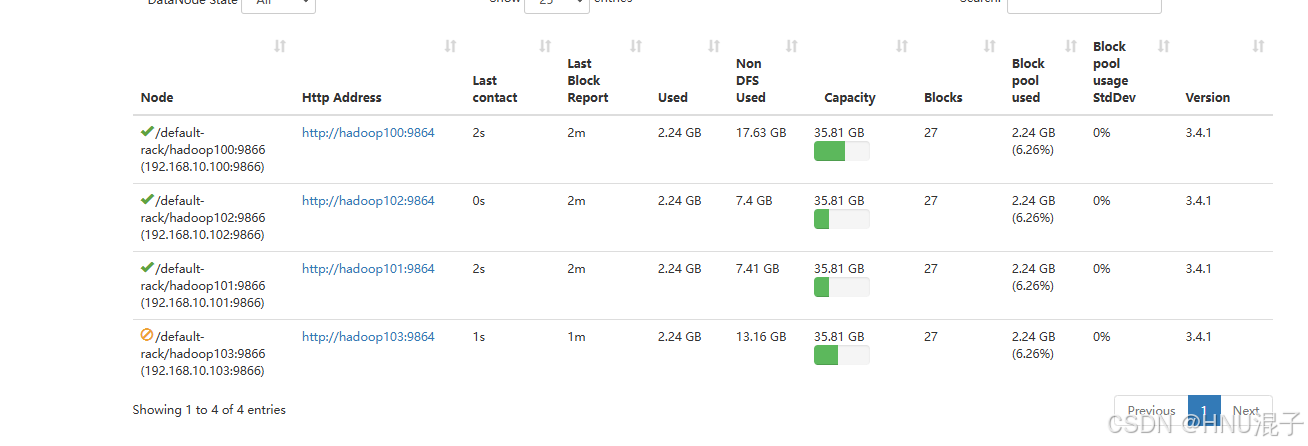
注意,在decommisioned之前,hdfs会自己把即将下线的节点上的数据自动拷贝到其他节点,确保数据安全性,同时,如果你想删除hadoop103或者恢复都可以不用再重启hdfs集群了。这也体现了hadoop的超高可扩展性。

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









