






ChaIR
模型框图
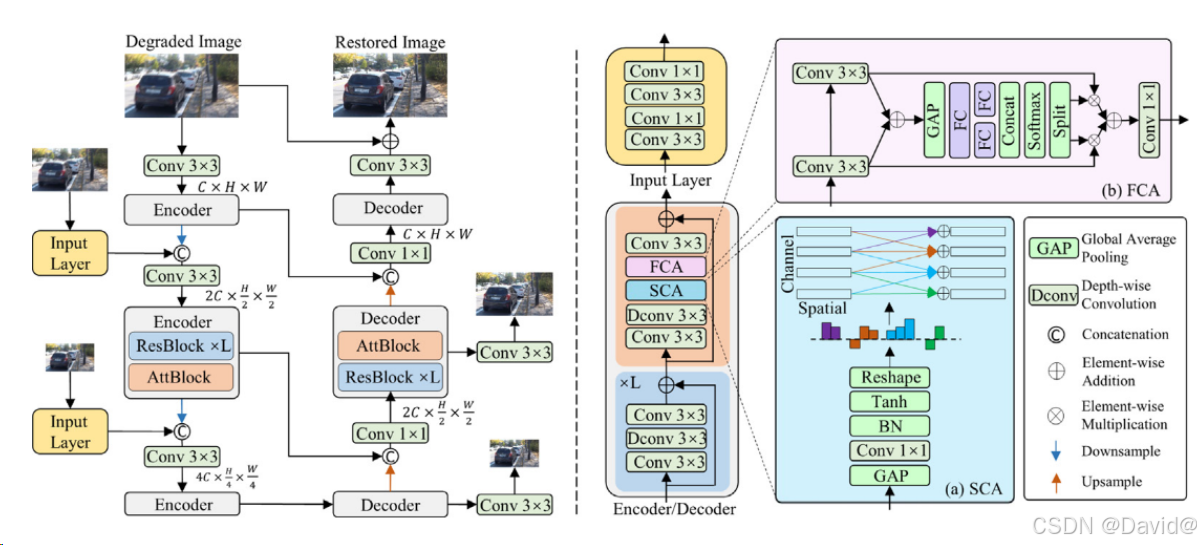
这个框图展示了一个用于图像处理的深度学习模型,特别是用于图像去雾或去噪等退化图像的恢复。模型采用了编码器-解码器的结构,并集成了注意力机制和残差模块。下面是图中几个重要部分的解释:
左侧(模型结构的总体流程):
- 输入层:输入的是退化的图像,图像经过一个
3x3的卷积层进行特征提取。 - 编码器(Encoder):
- 包含卷积层(
Conv 3x3)用于提取特征。 - 其中有多个
ResBlock(残差模块)和AttBlock(注意力模块),帮助捕捉图像的高级特征,并且缓解梯度消失问题。 - 通过
Downsample操作,逐渐减小特征图的空间分辨率,同时增大通道数,以获得多尺度的特征。
- 包含卷积层(
- 解码器(Decoder):
- 类似于编码器,但反向操作。首先通过卷积层逐渐恢复空间分辨率,并且通过
Upsample恢复原图大小。 - 解码过程中也有
ResBlock和AttBlock模块,帮助进一步恢复图像细节。
- 类似于编码器,但反向操作。首先通过卷积层逐渐恢复空间分辨率,并且通过
右侧(核心模块的细节):
- FCA(Feature Channel Attention):
- 该模块通过
Global Average Pooling (GAP)操作提取特征的全局平均信息,然后通过全连接层(FC)和Sigmoid操作生成注意力权重,对通道进行加权调整,帮助模型关注更加重要的特征通道。
- 该模块通过
- SCA(Spatial Channel Attention):
- SCA模块同时关注空间和通道特征,首先通过
Reshape和Tanh操作对通道进行处理,然后结合空间信息(通过多尺度特征融合)来生成注意力图,最后结合Element-wise Addition和Element-wise Multiplication等操作来调整特征图。
- SCA模块同时关注空间和通道特征,首先通过
其他细节:
- 残差连接:在网络的多个位置使用了残差连接,通过
Element-wise Addition操作将输入特征与输出特征相加,帮助信息传递,避免信息损失。 - 深度卷积(Depth-wise Convolution, Dconv):在编码器和解码器中均使用了
Depth-wise Convolution,通过分离通道的卷积操作来减少参数量并提高计算效率。
通过分离通道的卷积操作来减少参数量并提高计算效率。
这个模型结合了多种经典的深度学习模块(如卷积层、残差模块、注意力机制)来实现退化图像的恢复。

















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









