




由百度开发的实时检测 Transformer (RT-DETR) 是一种先进的端到端对象检测器,可在保持高精度的同时提供实时性能。它基于 DETR(无 NMS 框架)的思想,同时引入了基于 conv 的骨干网络和一个高效的混合编码器以获得实时速度。
RT-DETR 通过解耦尺度内交互和跨尺度融合来高效地处理多尺度特征。该模型具有高度的适应性,支持使用不同的解码器层灵活调整推理速度,而无需重新训练。RT-DETR 在 CUDA 与 TensorRT 等加速后端上表现出色,优于许多其他实时对象检测器。
Ultralytics Python API 提供了具有不同规模的预训练 PaddlePaddle RT-DETR 模型,本文使用Ultralytics进行RT-DETR的复现。
训练没有任何问题。但是评估的时候,如果开启save_json=True的选项,会直接报错:
(Pytorch) PS D:\CodeProject\datasets\VisDrone> python .\ultralytics-main\check.py
Ultralytics 8.3.192 Python-3.10.18 torch-2.0.0 CUDA:0 (NVIDIA GeForce RTX 4090, 24564MiB)
rtdetr-l summary: 302 layers, 32,004,290 parameters, 0 gradients, 103.5 GFLOPs
val: Fast image access (ping: 0.00.0 ms, read: 2287.3481.3 MB/s, size: 175.5 KB)
val: Scanning D:\CodeProject\datasets\VisDrone\VisDrone_YOLO\VisDrone2019-DET-val\labels.cache... 548 images, 0 backgrounds, 0 corrupt: 100% ━━━━━━━━━━━━ 548/548 0.0s
Class Images Instances Box(P R mAP50 mAP50-95): 0% ──────────── 0/137 0.1s<
Traceback (most recent call last):
File "D:\CodeProject\datasets\VisDrone\ultralytics-main\check.py", line 11, in <module>
result = model.val(data=r'D:\CodeProject\datasets\VisDrone\ultralytics-main\ultralytics\cfg\datasets\VisDrone.yaml',
File "D:\CodeProject\datasets\VisDrone\ultralytics-main\ultralytics\engine\model.py", line 635, in val
validator(model=self.model)
File "D:\Anaconda3\envs\Pytorch\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "D:\CodeProject\datasets\VisDrone\ultralytics-main\ultralytics\engine\validator.py", line 221, in __call__
self.update_metrics(preds, batch)
File "D:\CodeProject\datasets\VisDrone\ultralytics-main\ultralytics\models\yolo\detect\val.py", line 210, in update_metrics
predn_scaled = self.scale_preds(predn, pbatch)
File "D:\CodeProject\datasets\VisDrone\ultralytics-main\ultralytics\models\yolo\detect\val.py", line 407, in scale_preds
"bboxes": ops.scale_boxes(
File "D:\CodeProject\datasets\VisDrone\ultralytics-main\ultralytics\utils\ops.py", line 128, in scale_boxes
gain = ratio_pad[0][0]
TypeError: 'float' object is not subscriptable
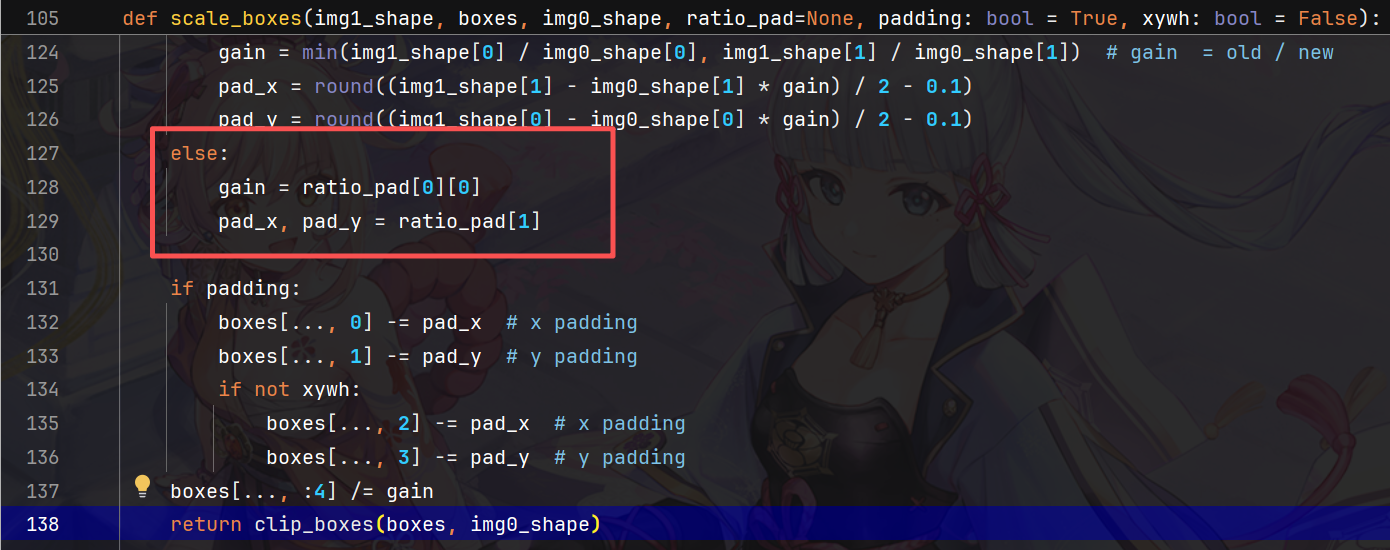
这个错误是因为在 ops.scale_boxes() 函数中,ratio_pad 参数被当作元组处理,但实际上传入的是一个浮点数。
需要进行修改:
def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None, padding: bool = True, xywh: bool = False):
"""
Rescale bounding boxes from one image shape to another.
Rescales bounding boxes from img1_shape to img0_shape, accounting for padding and aspect ratio changes.
Supports both xyxy and xywh box formats.
Args:
img1_shape (tuple): Shape of the source image (height, width).
boxes (torch.Tensor): Bounding boxes to rescale in format (N, 4).
img0_shape (tuple): Shape of the target image (height, width).
ratio_pad (tuple, optional): Tuple of (ratio, pad) for scaling. If None, calculated from image shapes.
padding (bool): Whether boxes are based on YOLO-style augmented images with padding.
xywh (bool): Whether box format is xywh (True) or xyxy (False).
Returns:
(torch.Tensor): Rescaled bounding boxes in the same format as input.
"""
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad_x = round((img1_shape[1] - img0_shape[1] * gain) / 2 - 0.1)
pad_y = round((img1_shape[0] - img0_shape[0] * gain) / 2 - 0.1)
else:
if isinstance(ratio_pad, (int, float)):
gain = ratio_pad
pad_x, pad_y = 0, 0
elif isinstance(ratio_pad, (list, tuple)):
if len(ratio_pad) == 2:
if isinstance(ratio_pad[0], (list, tuple)):
gain = ratio_pad[0][0]
else:
gain = ratio_pad[0]
if isinstance(ratio_pad[1], (list, tuple)) and len(ratio_pad[1]) >= 2:
pad_x, pad_y = ratio_pad[1][0], ratio_pad[1][1]
else:
pad_x, pad_y = 0, 0
else:
gain = ratio_pad[0] if len(ratio_pad) > 0 else 1.0
pad_x, pad_y = 0, 0
else:
gain = 1.0
pad_x, pad_y = 0, 0
if padding:
boxes[..., 0] -= pad_x # x padding
boxes[..., 1] -= pad_y # y padding
if not xywh:
boxes[..., 2] -= pad_x # x padding
boxes[..., 3] -= pad_y # y padding
boxes[..., :4] /= gain
return clip_boxes(boxes, img0_shape)
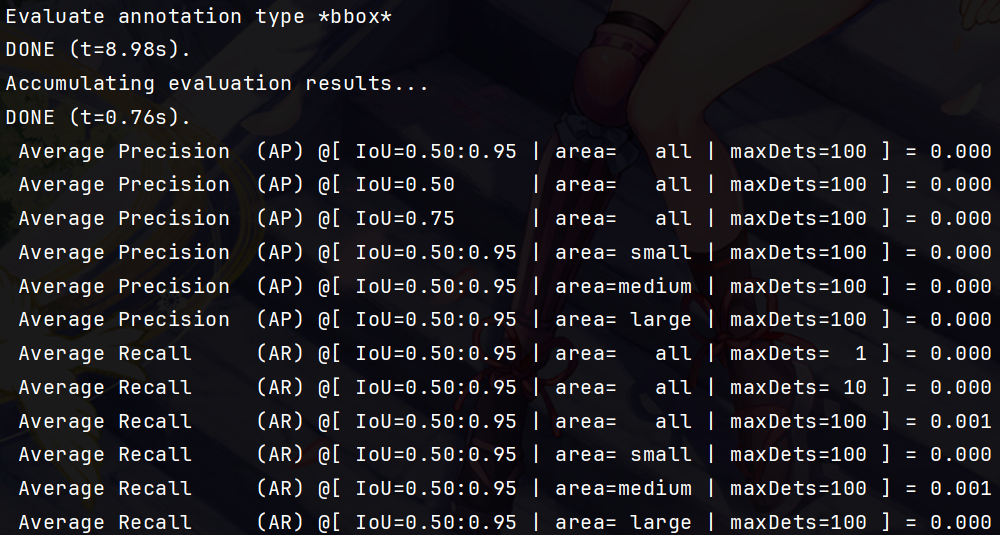
这样可以save_json成功,但是进行coco指标评估的时候,虽然没有报错,但是指标数值很低很低!
python D:\CodeProject\datasets\VisDrone\ultralytics-main\COCO_Evalution.py --annotations D:\CodeProject\datasets\VisDrone\VisDrone_YOLO\instances_val_2017.json --predictions D:\CodeProject\datasets\VisDrone\runs\detect\val9\predictions.json
评估的结果格式会出现问题,所以为了正常使用,我们需要进行逐个评估,并根据GT的格式来生成json文件。代码如下:
from ultralytics import RTDETR
import json
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
import os
def correct_coco_evaluation(model_path, image_dir, gt_json_path, output_dir='results'):
os.makedirs(output_dir, exist_ok=True)
coco_gt = COCO(gt_json_path)
gt_images = coco_gt.imgs
print(f"GT 中包含 {len(gt_images)} 张图像")
image_name_to_id = {}
for img_id, img_info in gt_images.items():
image_name_to_id[img_info['file_name']] = img_id
model = RTDETR(model_path)
results = model.predict(source=image_dir, save=False, conf=0.001, workers=0)
predictions = []
pred_id = 1
for result in results:
image_path = result.path
image_name = os.path.basename(image_path)
if image_name in image_name_to_id:
image_id = image_name_to_id[image_name]
else:
print(f"警告: 未找到图像 {image_name} 在 GT 中的对应ID,跳过")
continue
if result.boxes is not None:
for box in result.boxes:
xyxy = box.xyxy[0].tolist()
x1, y1, x2, y2 = xyxy
width = x2 - x1
height = y2 - y1
predictions.append({
'id': pred_id,
'image_id': image_id,
'category_id': int(box.cls.item()) + 1,
'bbox': [x1, y1, width, height],
'score': box.conf.item(),
'area': width * height
})
pred_id += 1
else:
print(f"图像 {image_name} 未检测到任何目标")
print(f"生成 {len(predictions)} 个预测")
pred_file = os.path.join(output_dir, 'predictions.json')
with open(pred_file, 'w') as f:
json.dump(predictions, f, indent=2)
coco_dt = coco_gt.loadRes(pred_file)
coco_eval = COCOeval(coco_gt, coco_dt, 'bbox')
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
return coco_eval.stats
if __name__ == '__main__':
stats = correct_coco_evaluation(
model_path=r'D:\CodeProject\datasets\VisDrone\ultralytics-main\runs\detect\train4\weights\best.pt',
image_dir=r'D:\CodeProject\datasets\VisDrone\VisDrone_YOLO\VisDrone2019-DET-test\images',
gt_json_path=r'D:\CodeProject\datasets\VisDrone\ultralytics-main\instances_test_2017.json'
)
print(f"\nCOCO 评估结果:")
print(f"AP@[0.5:0.95]: {stats[0]:.3f}")
print(f"AP@0.5: {stats[1]:.3f}")
print(f"AP@0.75: {stats[2]:.3f}")
print(f"AP_small: {stats[3]:.3f}")
print(f"AP_medium: {stats[4]:.3f}")
print(f"AP_large: {stats[5]:.3f}")
结果顺利:

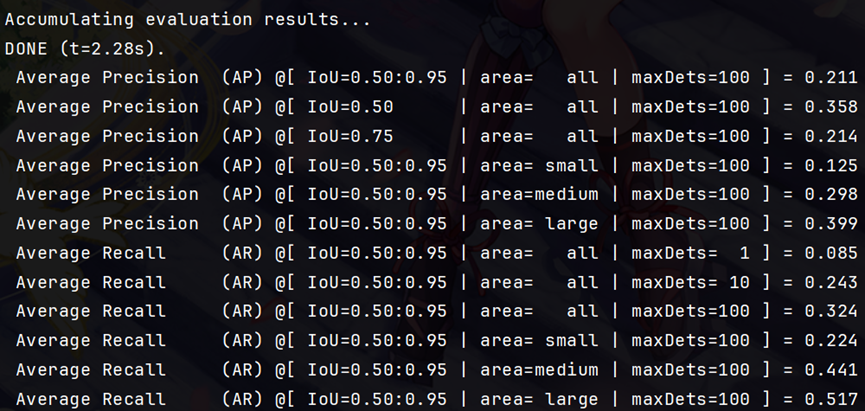


















 8439
8439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











