 YOLO模型COCO评估脚本详解
YOLO模型COCO评估脚本详解





文章目录
1. 脚本功能概述
本脚本基于 COCO 官方提供的pycocotools库,实现对目标检测模型预测结果的标准化评估。
核心功能是接收真实标注(GT) 与模型预测结果两类 COCO JSON 格式文件,通过调用pycocotools API 执行评估流程,最终输出 COCO 标准的 12 项评估指标(含 AP、AP50、AP75 等关键指标),为模型性能提供量化参考。
2. 依赖环境配置
运行脚本前需确保本地 Python 环境及以下依赖库已正确安装,推荐使用 Python 3.10 及以上版本(兼容pycocotools最新特性)。
2.1 必需依赖库
- pycocotools:COCO 官方提供的评估 API,用于实现指标计算逻辑
pip install pycocotools
3. 脚本使用方法
脚本通过命令行参数接收输入文件路径,无需修改代码即可直接运行。
python D:\CodeProject\datasets\VisDrone\ultralytics-main\COCO_Evalution.py --annotations D:\CodeProject\datasets\VisDrone\ultralytics-main\instances_val_2017.json --predictions D:\CodeProject\datasets\VisDrone\ultralytics-main\runs\detect\val\predictions.json
–annotations 和 --predictions 字段改成自己的文件路径,前者是GT(coco标注格式),后者是模型预测格式。
import argparse
import json
import os
from pathlib import Path
import numpy as np
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
def evaluate_coco(pred_json, anno_json):
print(f"\n正在评估 COCO 指标,使用 {pred_json} 和 {anno_json}...")
for x in [pred_json, anno_json]:
assert os.path.isfile(x), f"文件 {x} 不存在"
anno = COCO(str(anno_json))
pred = anno.loadRes(str(pred_json))
eval_bbox = COCOeval(anno, pred, 'bbox')
eval_bbox.evaluate()
eval_bbox.accumulate()
eval_bbox.summarize()
def main():
parser = argparse.ArgumentParser(description='评估COCO格式的目标检测结果')
parser.add_argument('--annotations', type=str, required=True, help='COCO格式的标注文件路径')
parser.add_argument('--predictions', type=str, required=True, help='预测结果的JSON文件路径')
args = parser.parse_args()
pred_json = Path(args.predictions)
anno_json = Path(args.annotations)
stats = evaluate_coco(pred_json, anno_json)
if __name__ == '__main__':
main()
4. 输入文件格式规范
脚本对输入文件格式有严格要求,需确保两类文件均符合 COCO 标准格式,否则会导致评估失败。
4.1 真实标注文件(–annotations)
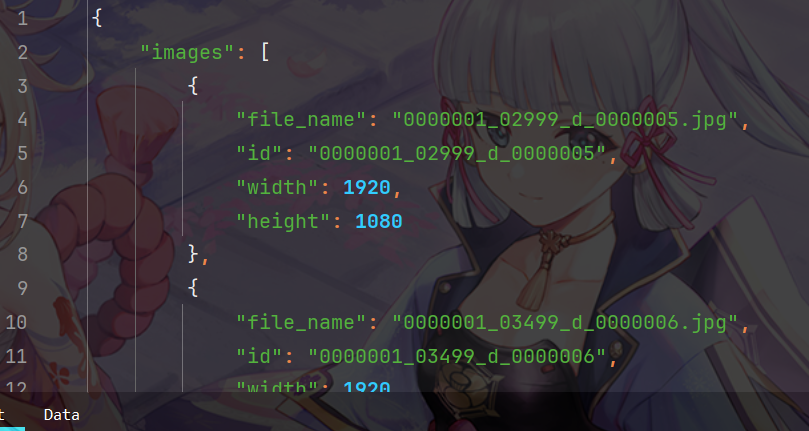
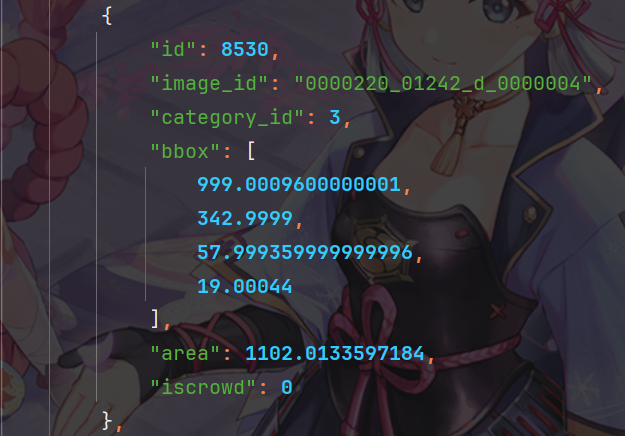
需为标准 COCO JSON 格式,核心包含以下字段:
- info:数据集基本信息(如版本、创建时间);
- licenses:数据授权信息;
- images:图像元数据(含id、图像宽高、文件名等,id需与标注关联);
- annotations:目标标注信息(每个标注含image_id、category_id、bbox、iscrowd等);
- categories:类别定义(含id、name,id需与标注中的category_id对应)。
示例如下所示:
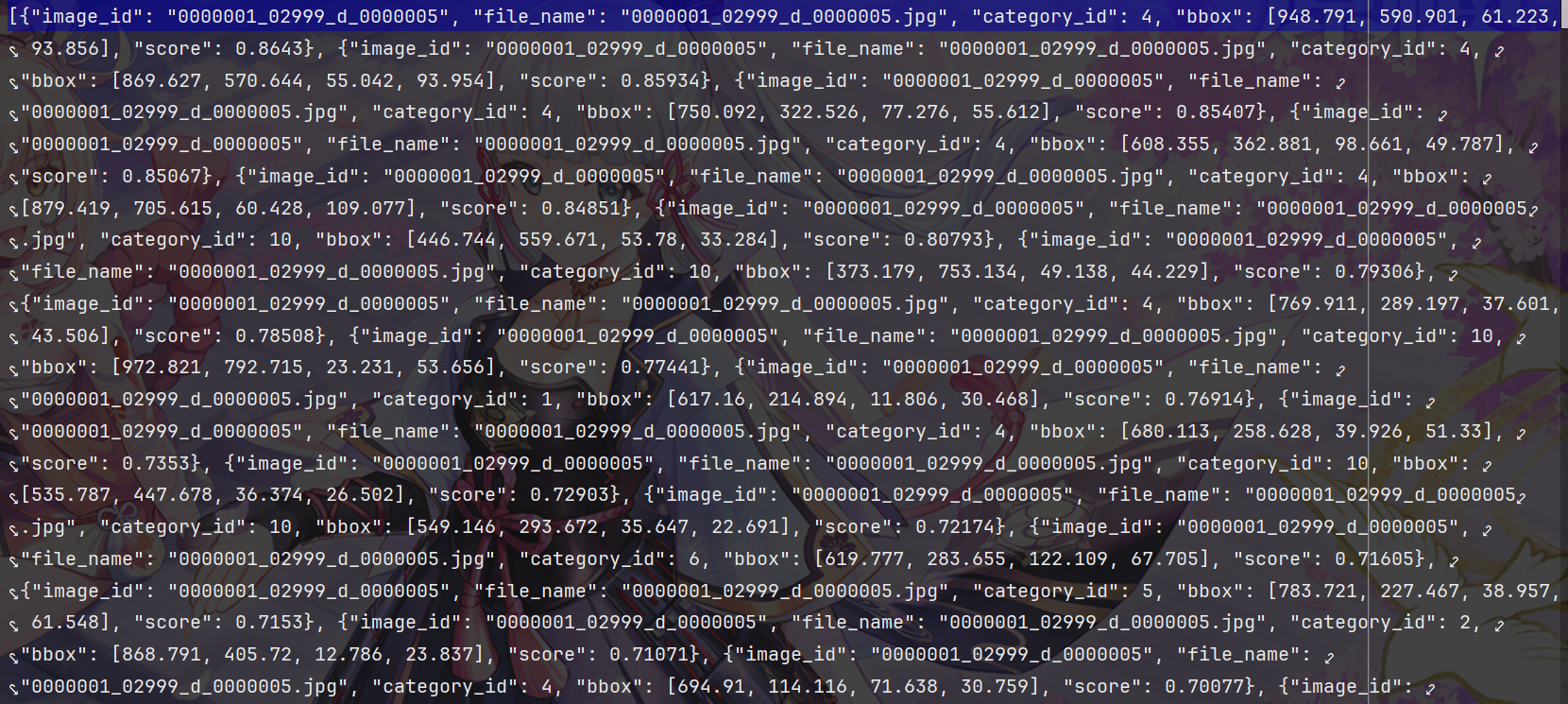
4.2 模型预测结果文件(–predictions)
需为 JSON 列表格式,列表中每个元素为单个目标的检测结果字典,必须包含以下 4 个键:
- image_id:整数型,对应真实标注文件中图像的唯一id(确保与 GT 图像匹配);
- category_id:整数型,检测目标的类别id(需与真实标注文件中categories的id完全一致);
- bbox:列表型,边界框坐标,格式为[x, y, width, height](x/y为边界框左上角像素坐标,width/height为框的宽高,单位为像素);
- score:浮点型,模型对该检测结果的置信度(范围 0~1,用于后续 AP 计算时的结果排序)。
5. 新版评估存在的问题
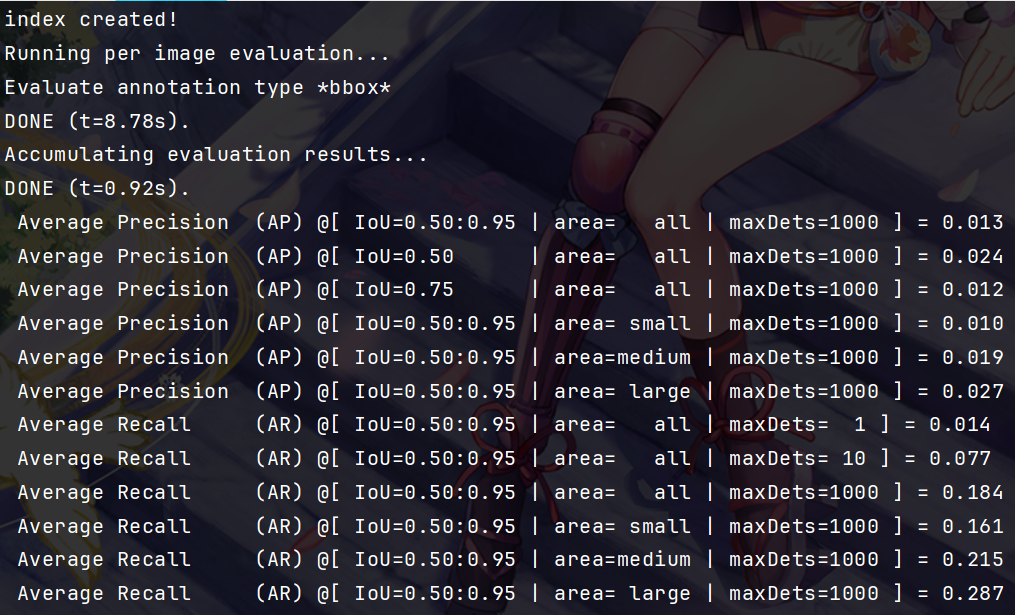
发现存在问题,分数很低。分析原因:
- GT的类别编号从0开始
- 但是新版YOLO的预测类别编号从1开始,导致对不上。
所以需要调整GT的标号,对类别编码加1:
import json
def adjust_category_ids(input_file, output_file):
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
if 'annotations' in data:
for annotation in data['annotations']:
if 'category_id' in annotation:
annotation['category_id'] = annotation['category_id'] + 1
if 'categories' in data:
for category in data['categories']:
if 'id' in category:
category['id'] = category['id'] + 1
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print(f"已成功调整category_id并保存到 {output_file}")
if __name__ == "__main__":
input_json = "D:/CodeProject/datasets/VisDrone/VisDrone_YOLO/instances_test_2017.json"
output_json = "D:/CodeProject/datasets/VisDrone/ultralytics-main/instances_test_2017.json"
adjust_category_ids(input_json, output_json)
调整后再次运行评估模块:
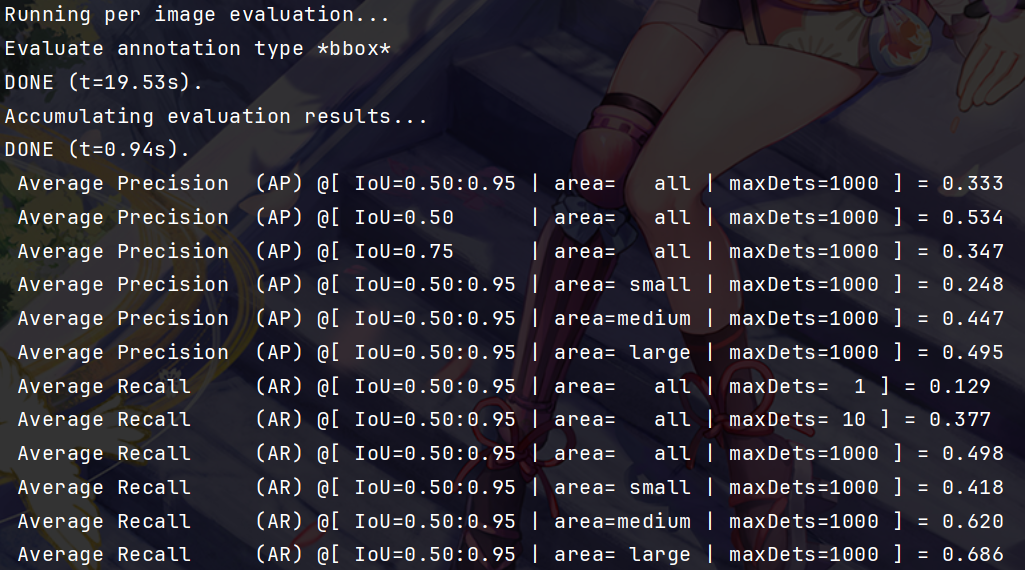
问题解决!成功!
6. 指标说明
- AP:所有类别在 IoU=0.5:0.05:0.95 下的平均精度(综合不同 IoU 阈值的性能)
- AP50:所有类别在 IoU=0.5 下的平均精度(宽松边界框匹配标准)
- AP75:所有类别在 IoU=0.75 下的平均精度(严格边界框匹配标准)
- APs:所有类别在 “小目标”(面积 < 32² 像素)上的平均精度
- APm:所有类别在 “中目标”(32²≤面积≤96² 像素)上的平均精度
- APl:所有类别在 “大目标”(面积 > 96² 像素)上的平均精度
- AR1:所有类别在 “单张图像最多检测 1 个目标” 时的平均召回率
- AR10:所有类别在 “单张图像最多检测 10 个目标” 时的平均召回率
- AR100:所有类别在 “单张图像最多检测 100 个目标” 时的平均召回率
- ARs:所有类别在 “小目标” 上的平均召回率(单图最多检测 100 个目标)
- ARm:所有类别在 “中目标” 上的平均召回率(单图最多检测 100 个目标)
- ARl:所有类别在 “大目标” 上的平均召回率(单图最多检测 100 个目标)


















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











