







文章目录
- 一、Inception-ResNet-v2-C
- 二、Inception-ResNet-v2-B
- 三、Inception-ResNet-v2-A
- 四、Inception-ResNet-v2 Reduction-B
- 五、Convolutional Block Attention Module
- 六、Efficient Channel Attention
- 七、ShuffleNet V2 Downsampling Block
- 八、FBNet Block
- 九、Neural Attention Fields
- 十、Inception-A
- 十一、Inception-B
- 十二、Inception-C
- 十三、Reduction-B
- 十四、Global Context Block
- 十五、One-Shot Aggregation
- 十六、Pyramidal Residual Unit
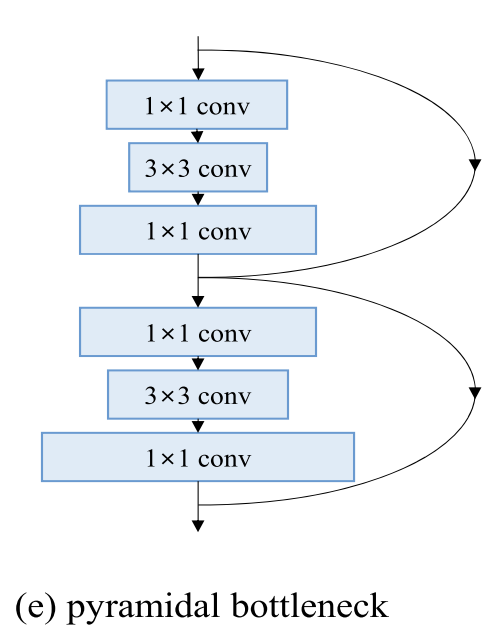
- 十七、Pyramidal Bottleneck Residual Unit
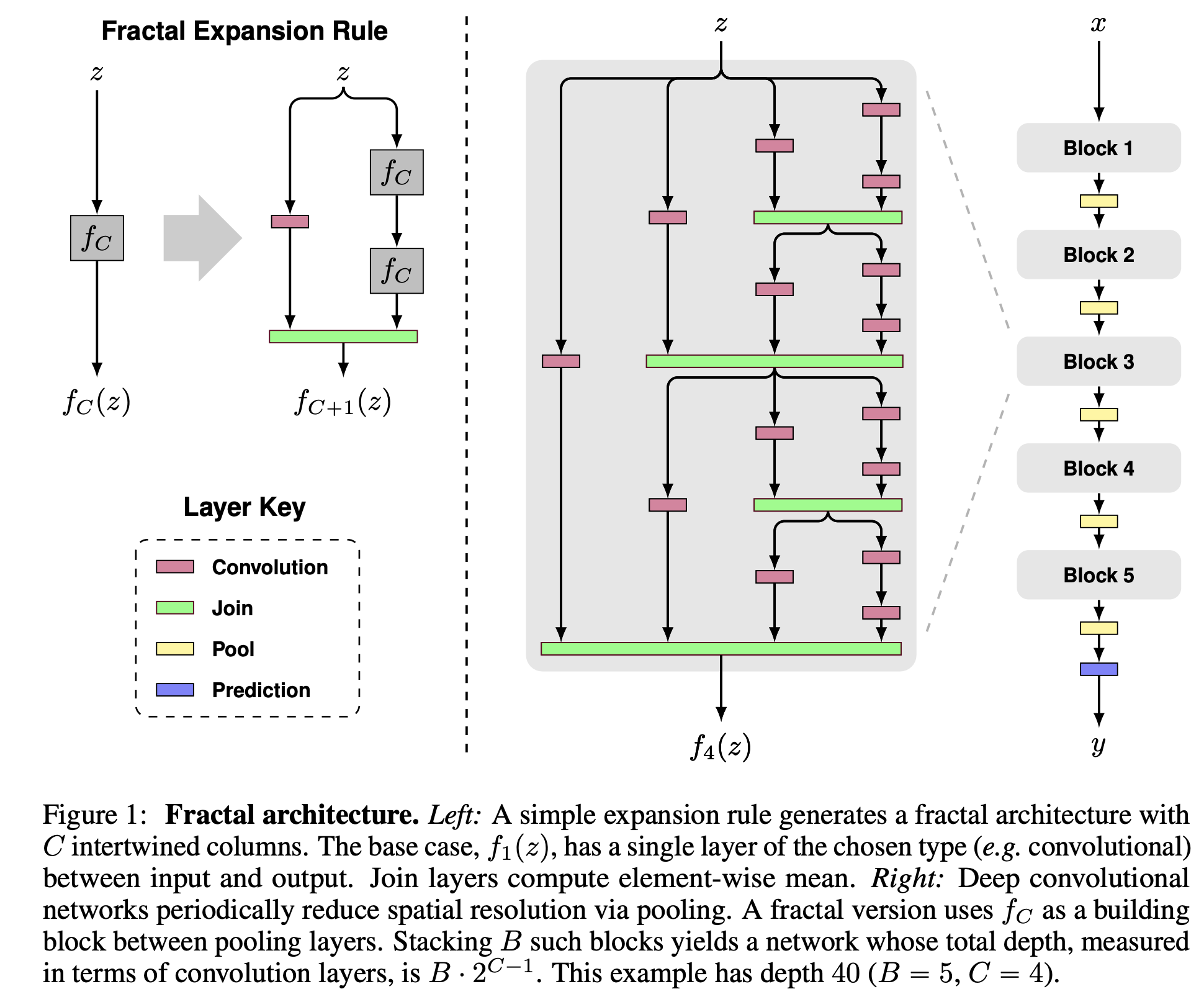
- 十八、Fractal Block
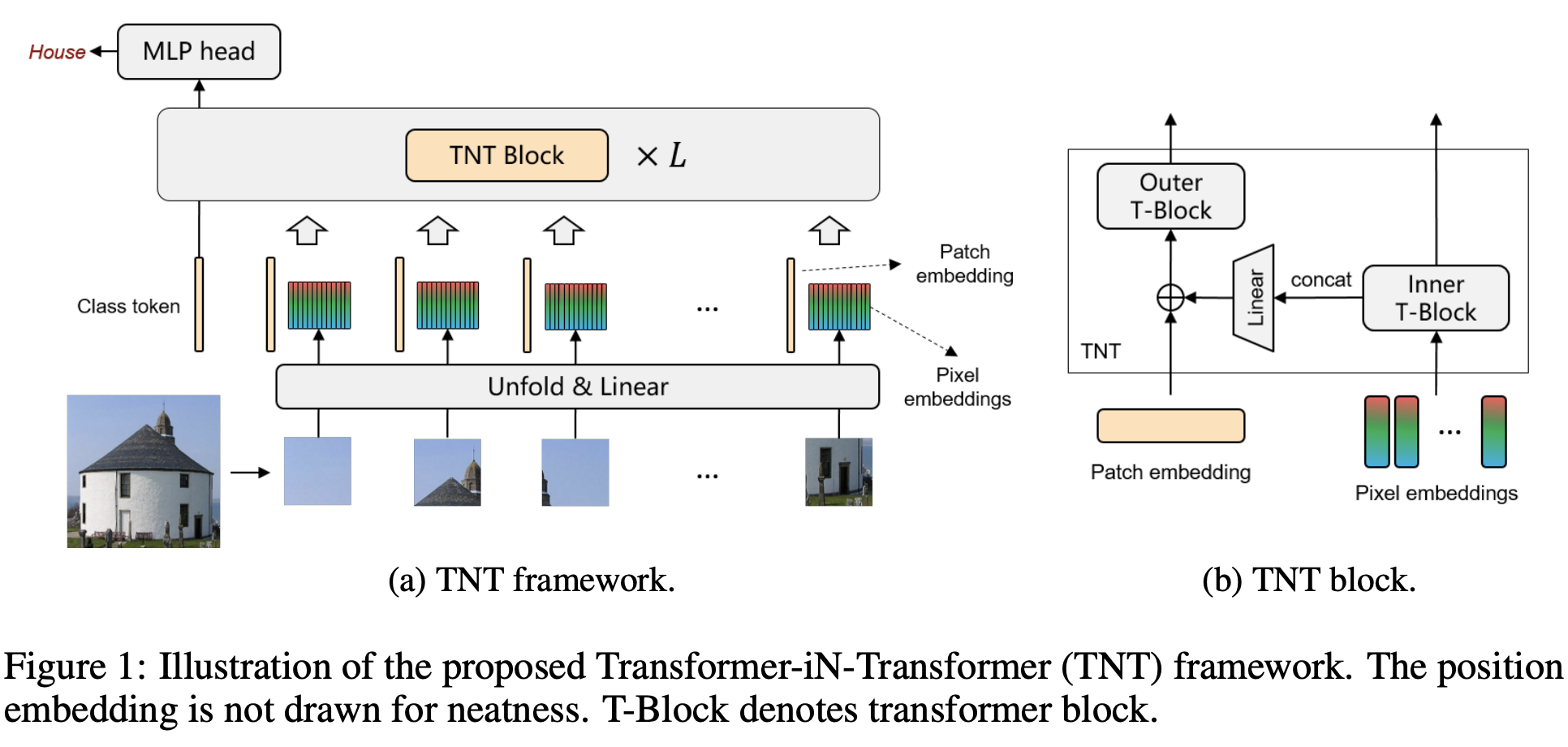
- 十九、Transformer in Transformer
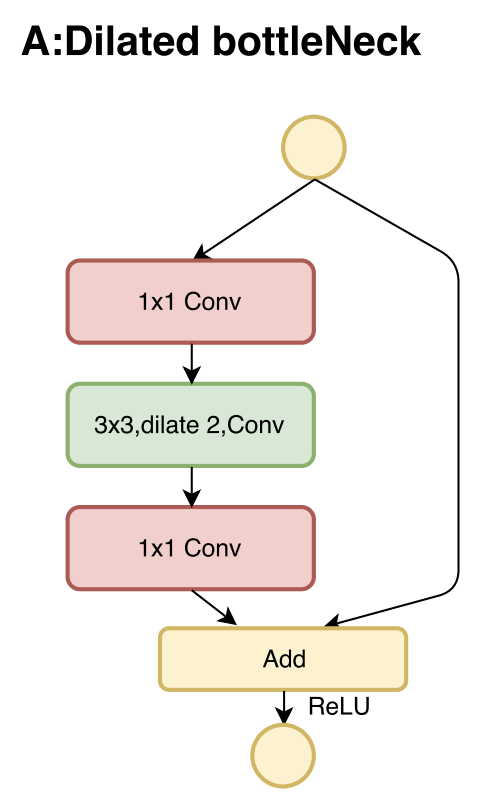
- 二十、Dilated Bottleneck Block
一、Inception-ResNet-v2-C
Inception-ResNet-v2-C 是 Inception-ResNet-v2 架构中使用的 8 x 8 网格的图像模型块。 它很大程度上遵循 Inception 模块和分组卷积的思想,但也包括残差连接。
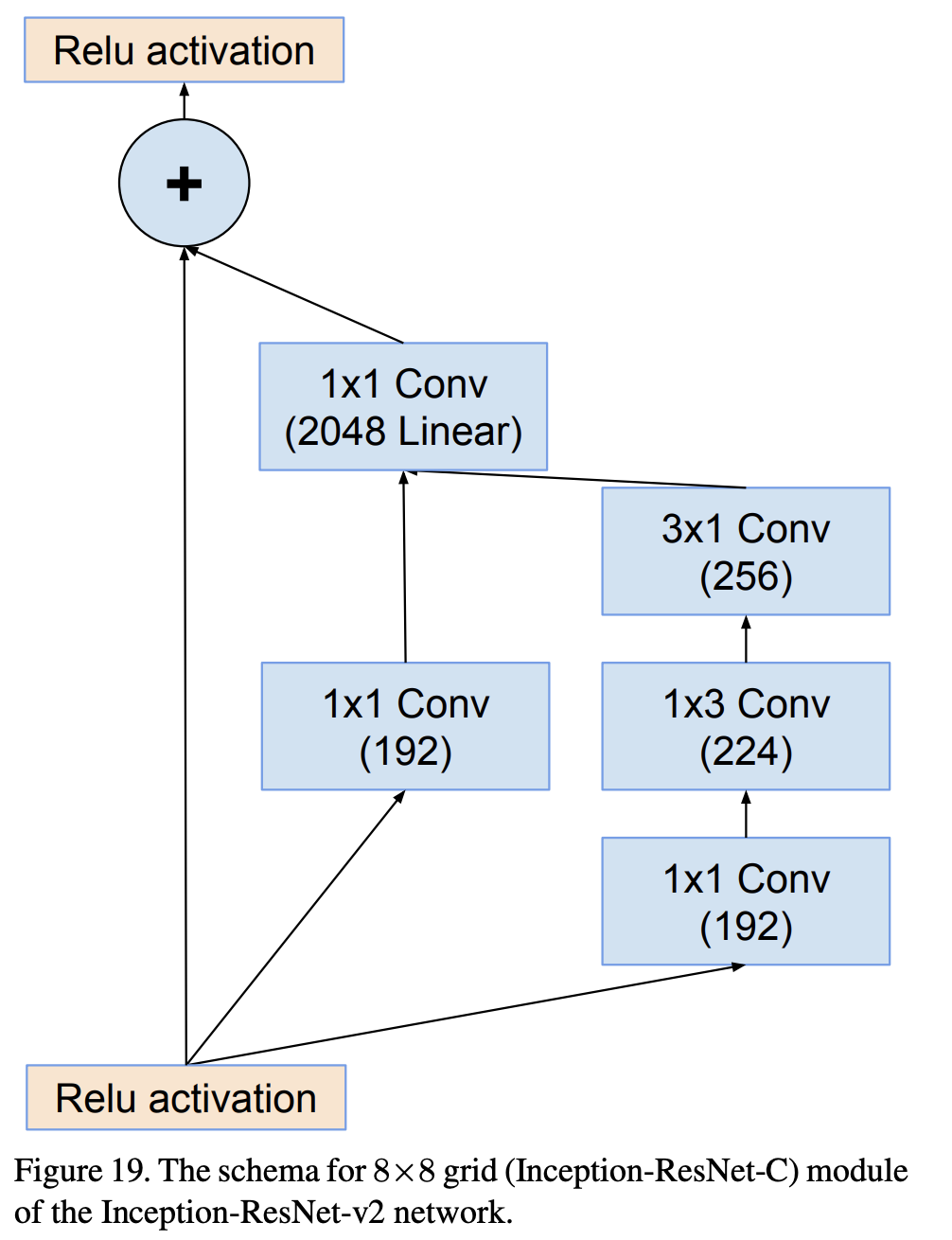
二、Inception-ResNet-v2-B
Inception-ResNet-v2-B 是 Inception-ResNet-v2 架构中使用的 17 x 17 网格的图像模型块。 它很大程度上遵循 Inception 模块和分组卷积的思想,但也包括残差连接。
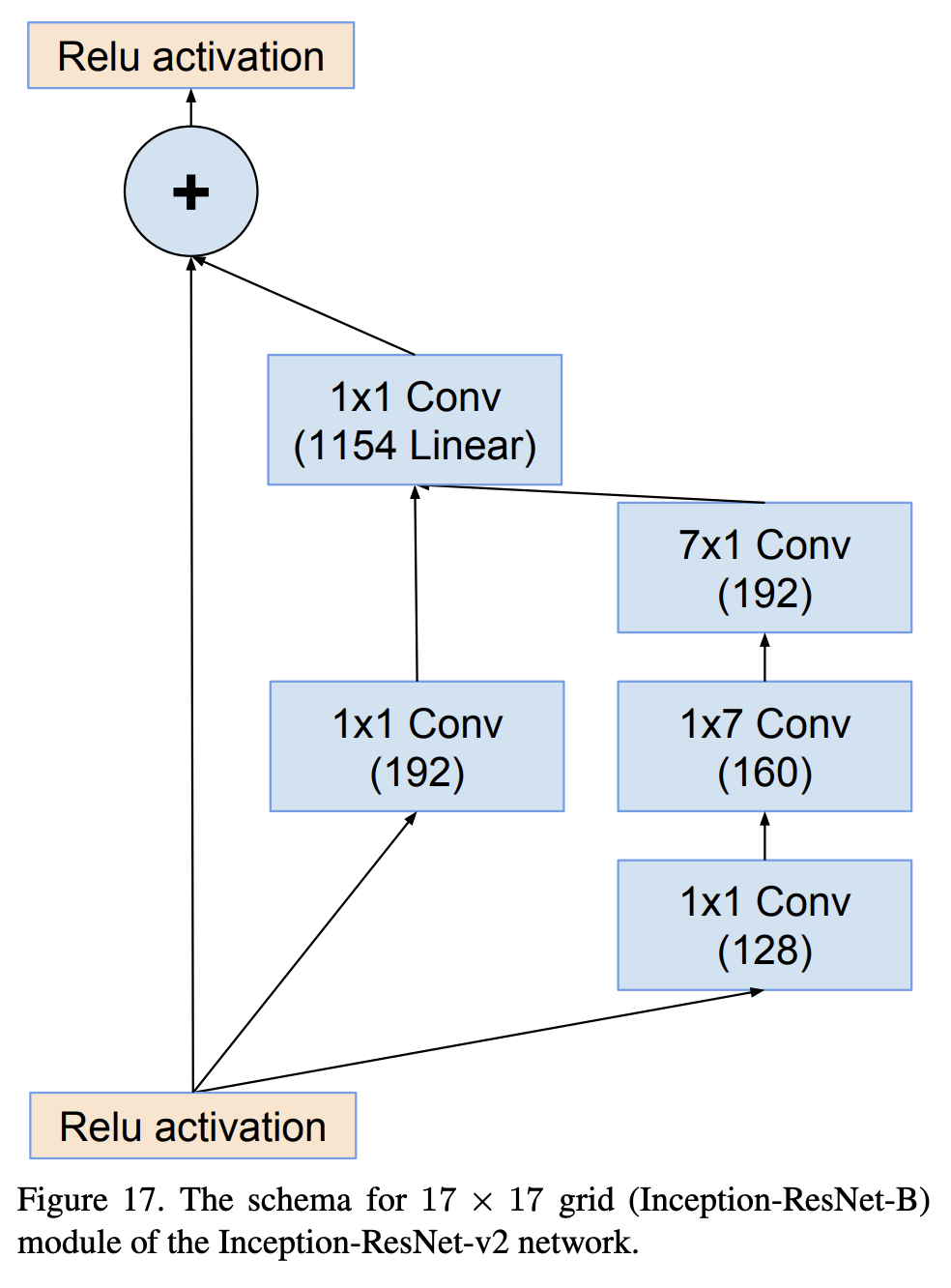
三、Inception-ResNet-v2-A
Inception-ResNet-v2-A 是 Inception-ResNet-v2 架构中使用的 35 x 35 网格的图像模型块。
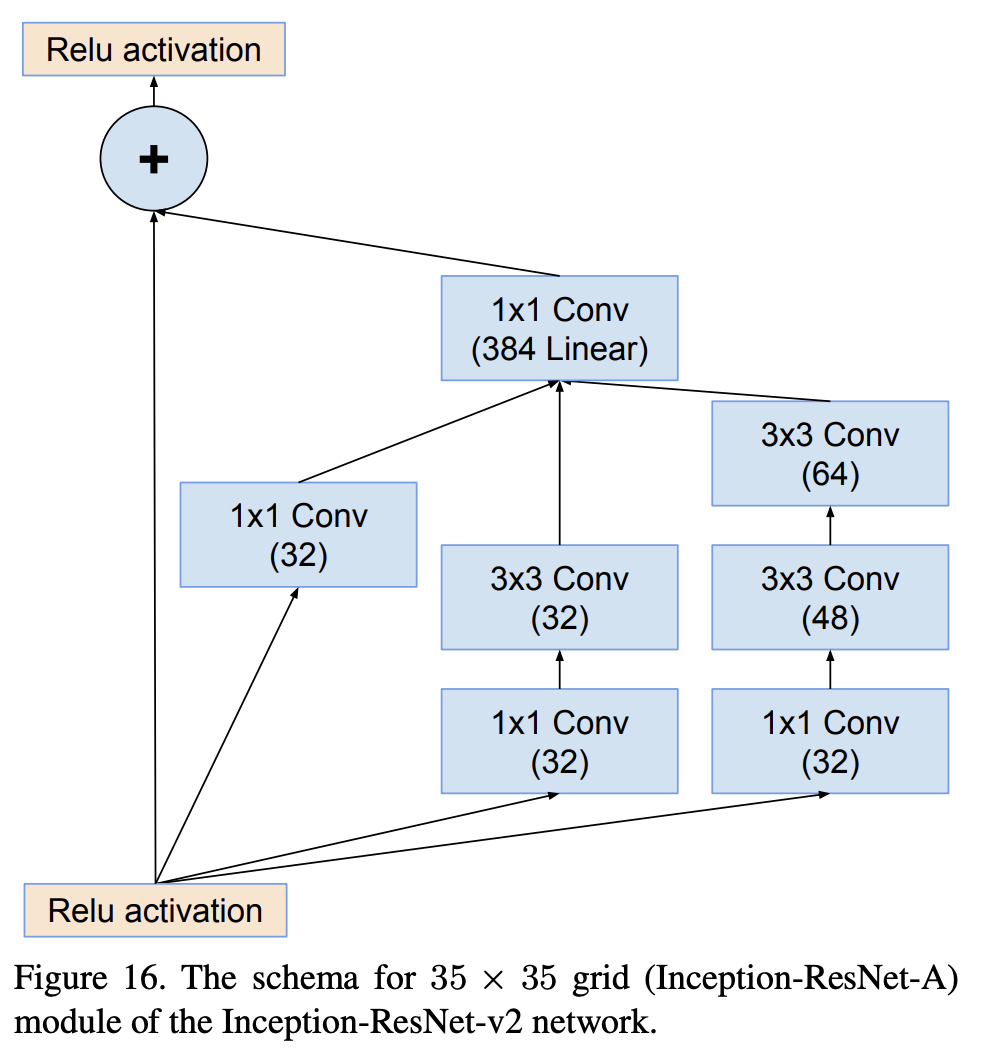
四、Inception-ResNet-v2 Reduction-B
Inception-ResNet-v2 Reduction-B 是 Inception-ResNet-v2 架构中使用的图像模型块。
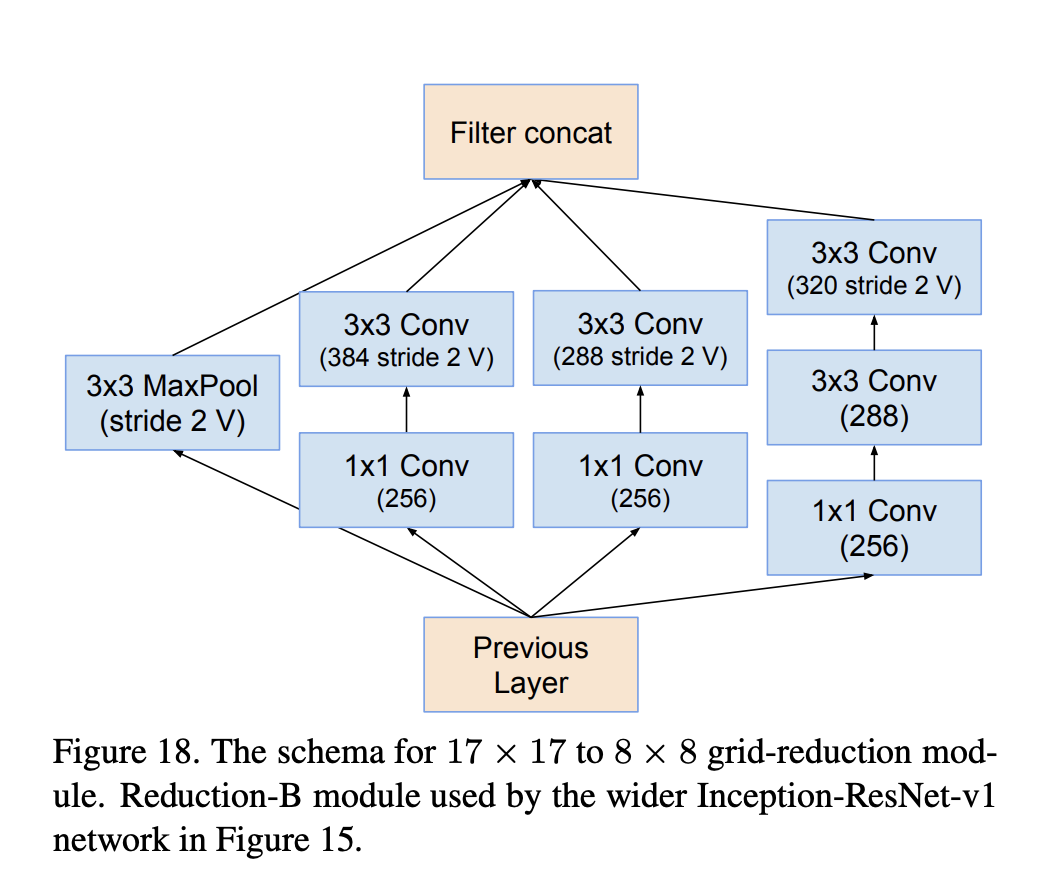
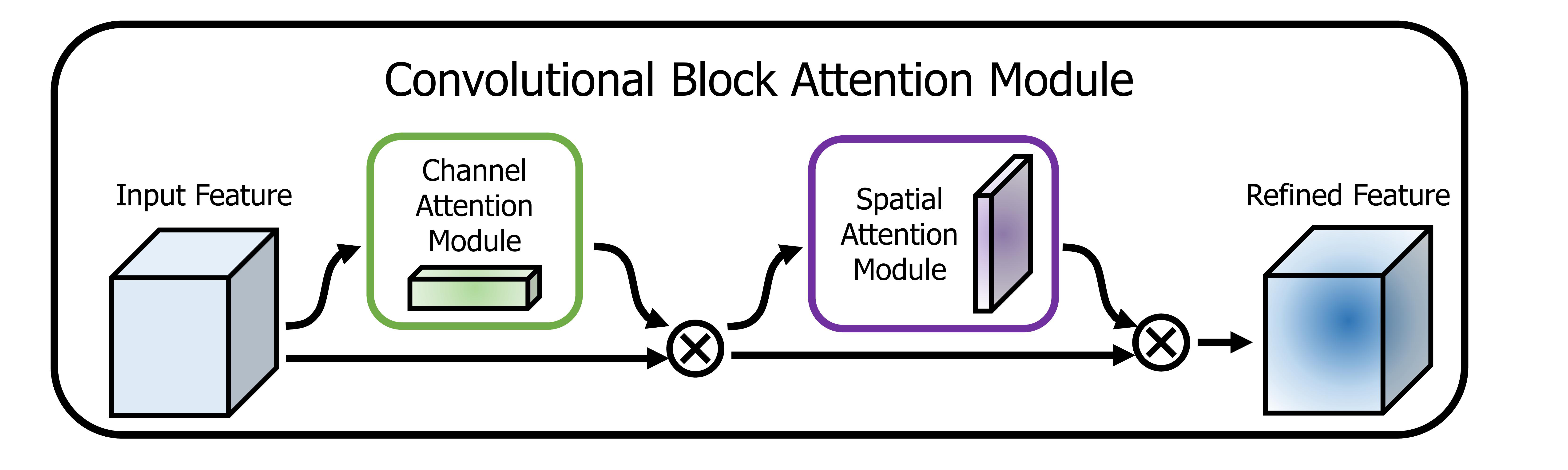
五、Convolutional Block Attention Module
卷积块注意力模块(CBAM)是卷积神经网络的注意力模块。 给定中间特征图,该模块沿着两个独立的维度(通道和空间)顺序推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征细化。

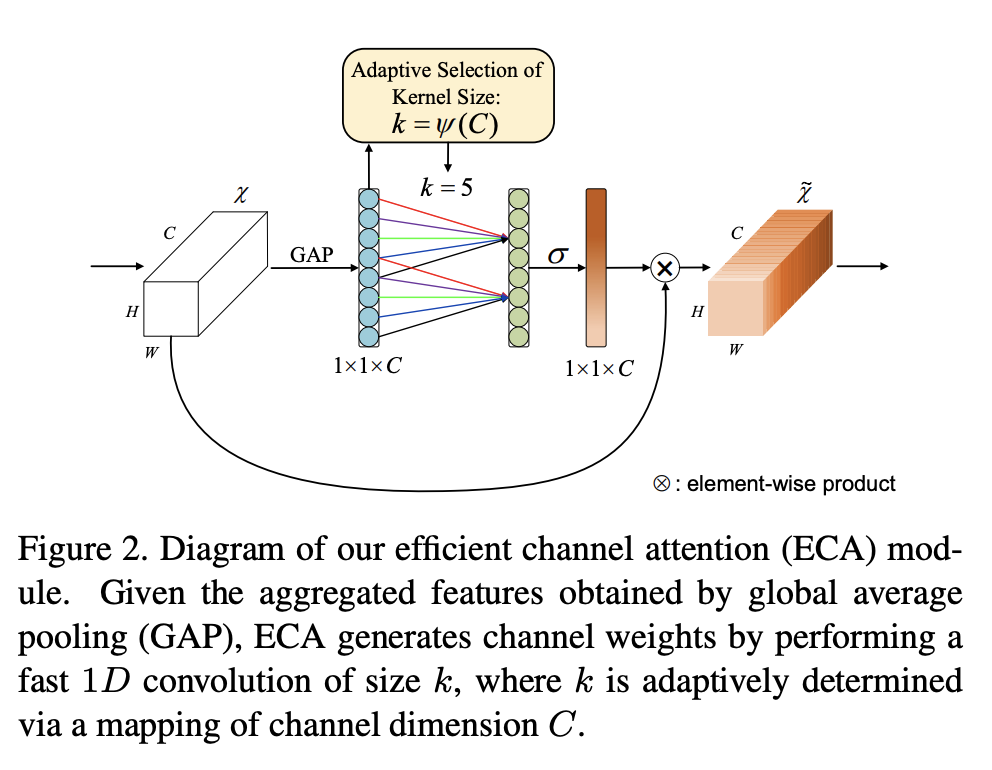
六、Efficient Channel Attention
高效通道注意力是一种基于挤压和激励块的架构单元,可以在不降低维度的情况下降低模型复杂性。 它被提议作为 ECA-Net CNN 架构的一部分。
在没有降维的情况下进行通道级全局平均池化之后,ECA 通过考虑每个通道及其通道来捕获局部跨通道交互k邻居。 ECA可以通过快速有效地实施1D尺寸卷积k,其中内核大小k表示局部跨通道交互的覆盖范围,即有多少邻居参与一个通道的注意力预测。
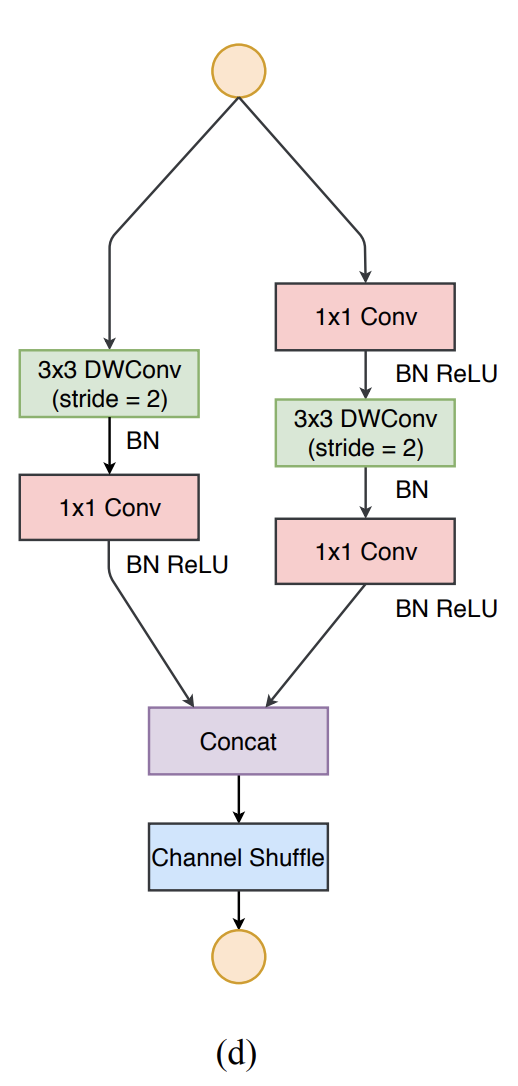
七、ShuffleNet V2 Downsampling Block
ShuffleNet V2 Downsampling Block 是 ShuffleNet V2 架构中使用的空间下采样块。 与常规 ShuffleNet V2 块不同,通道分割运算符被删除,因此输出通道的数量加倍。
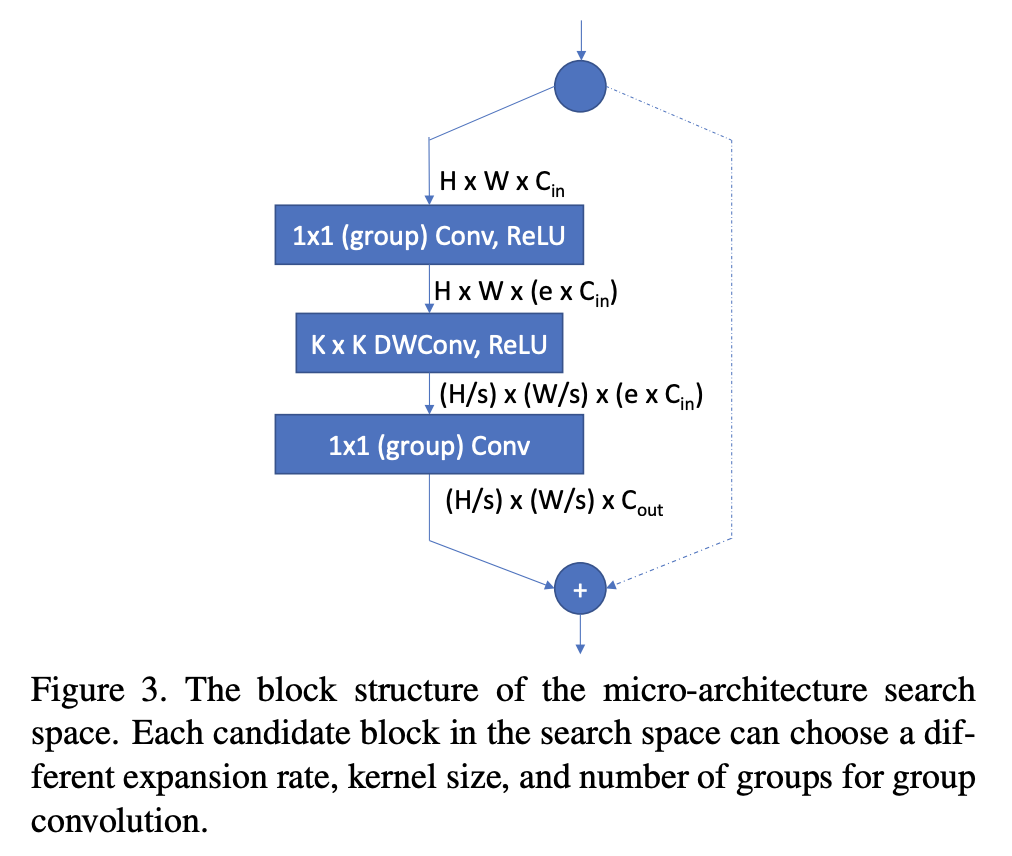
八、FBNet Block
FBNet Block 是通过 DNAS 神经架构搜索发现的 FBNet 架构中使用的图像模型块。 使用的基本构建块是深度卷积和残差连接。
九、Neural Attention Fields
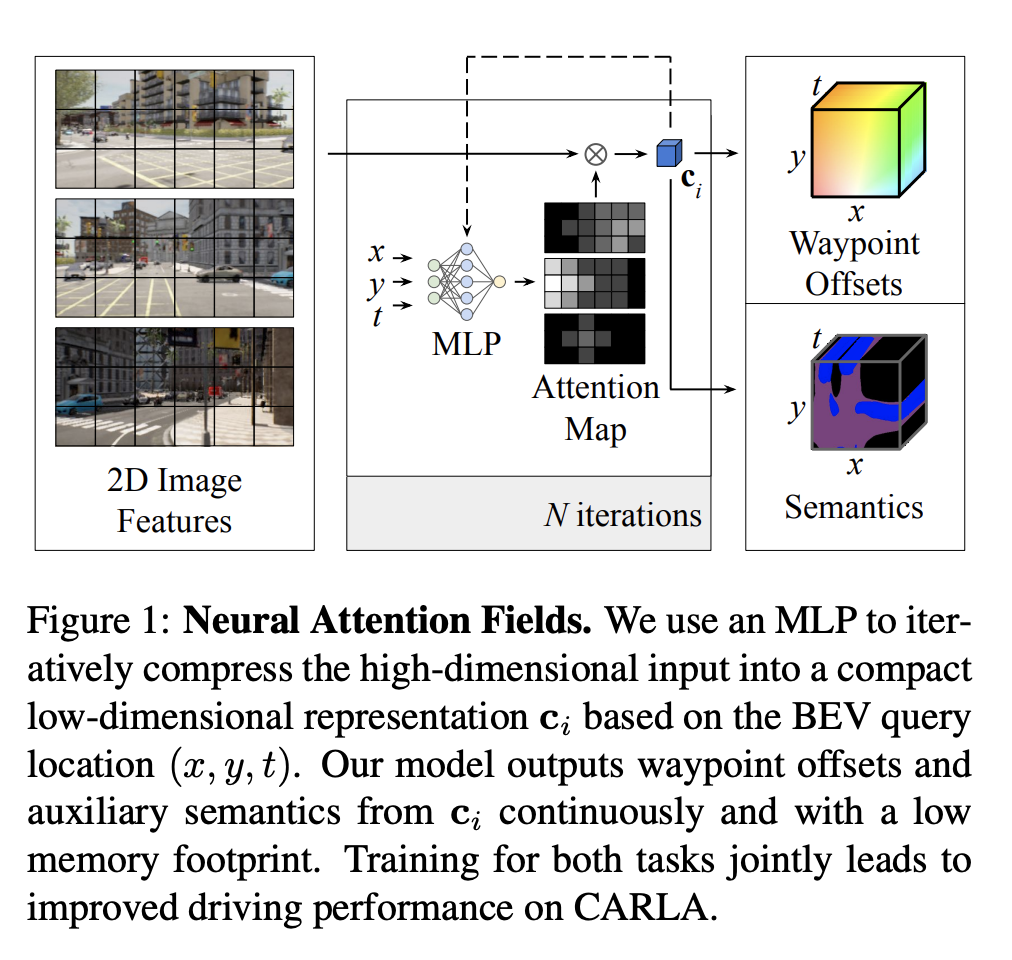
NEAT,即神经注意力域,是端到端模仿学习模型的特征表示。 NEAT 是一个连续函数,它将鸟瞰 (BEV) 场景坐标中的位置映射到路点和语义,使用中间注意力图迭代地将高维 2D 图像特征压缩为紧凑的表示。 这使得模型能够选择性地关注输入中的相关区域,同时忽略与驾驶任务无关的信息,从而有效地将图像与 BEV 表示相关联。 此外,使用 NEAT 中间表示可视化模型的注意力图可以提高可解释性。
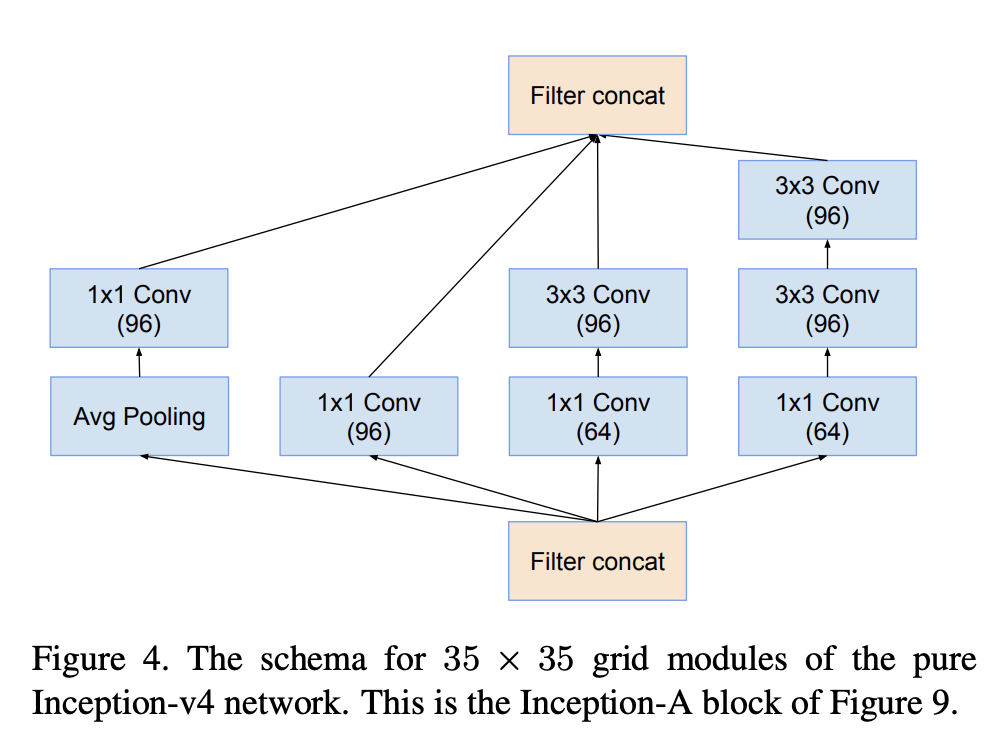
十、Inception-A
Inception-A 是 Inception-v4 架构中使用的图像模型块。
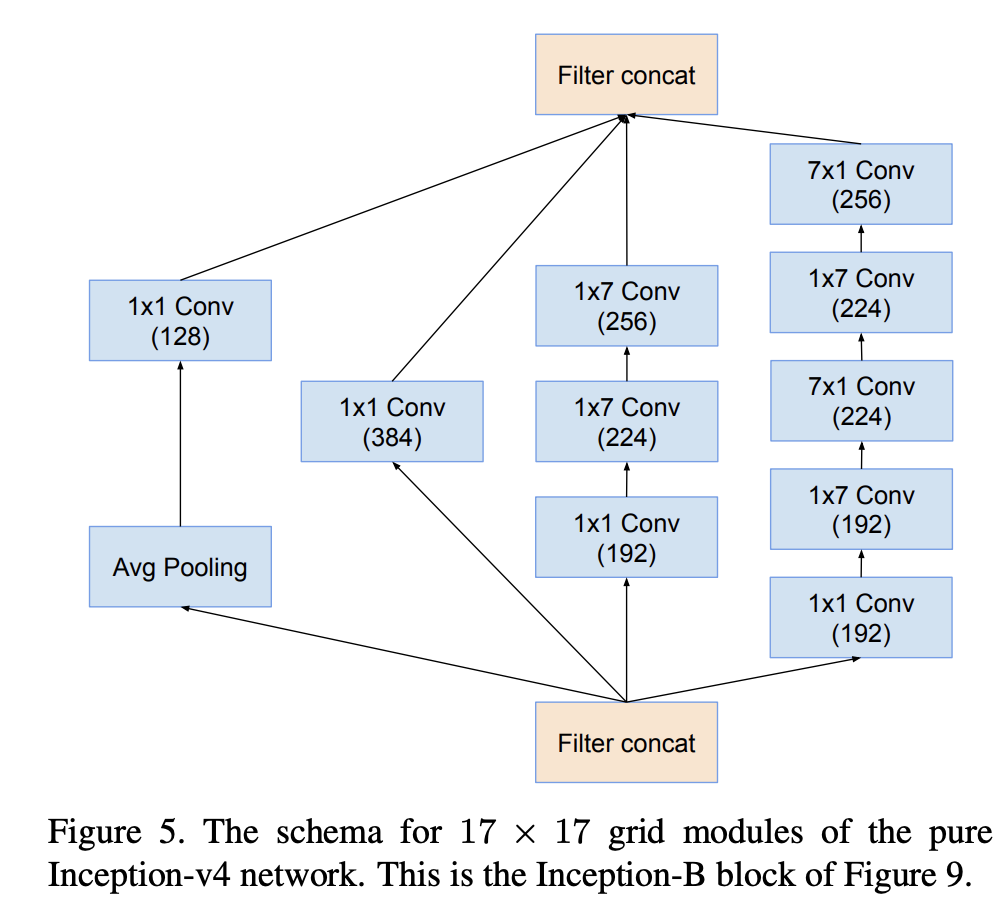
十一、Inception-B
Inception-B 是 Inception-v4 架构中使用的图像模型块。
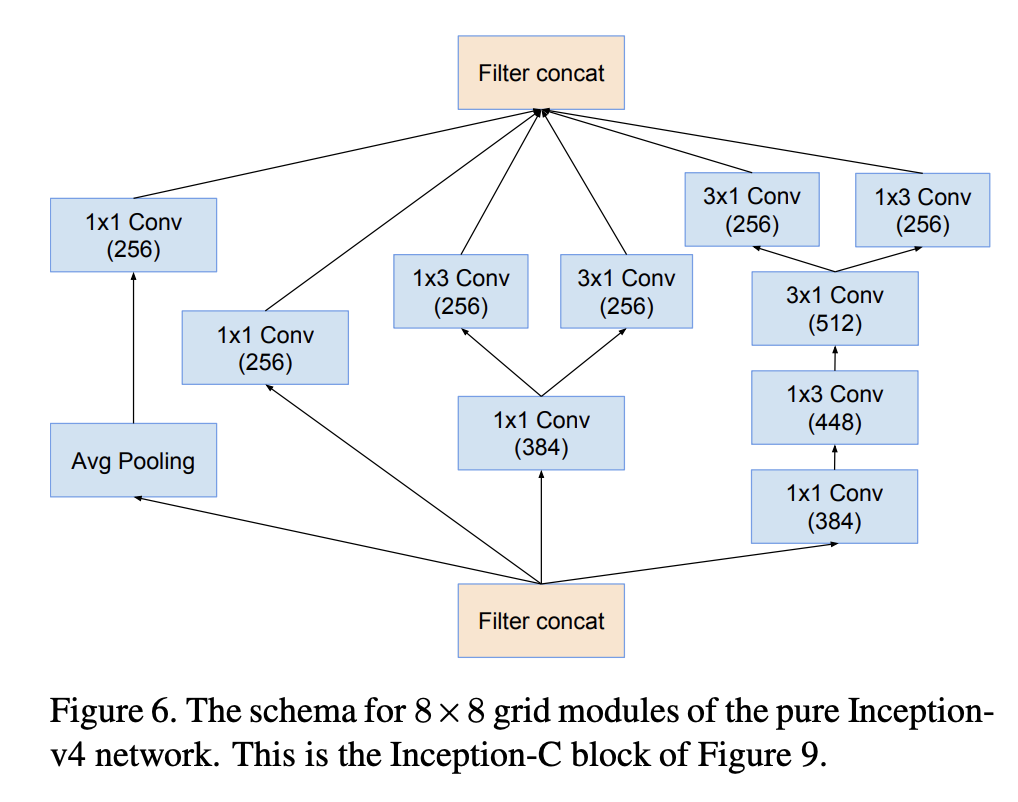
十二、Inception-C
Inception-C 是 Inception-v4 架构中使用的图像模型块。
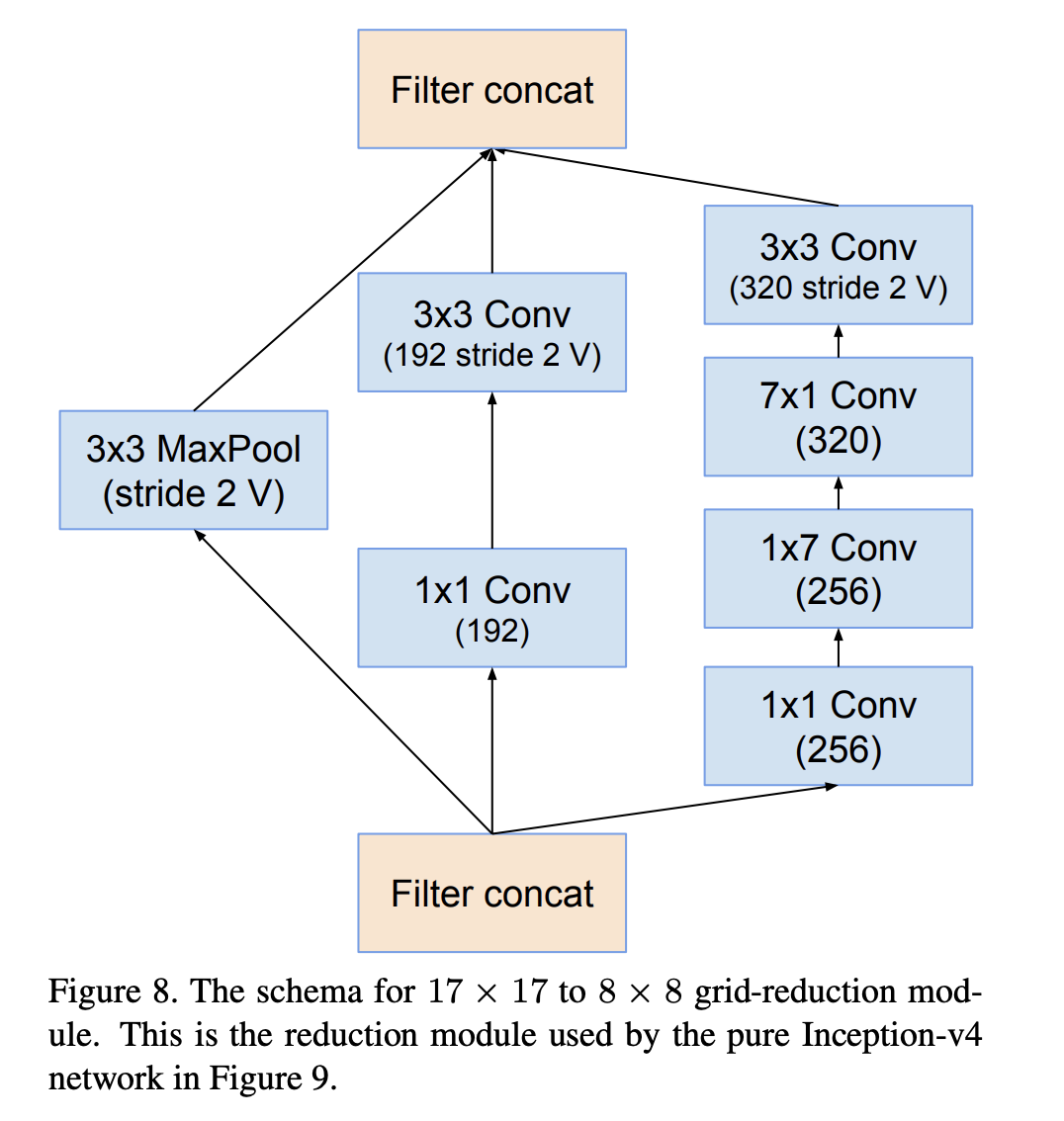
十三、Reduction-B
Reduction-B 是 Inception-v4 架构中使用的图像模型块。
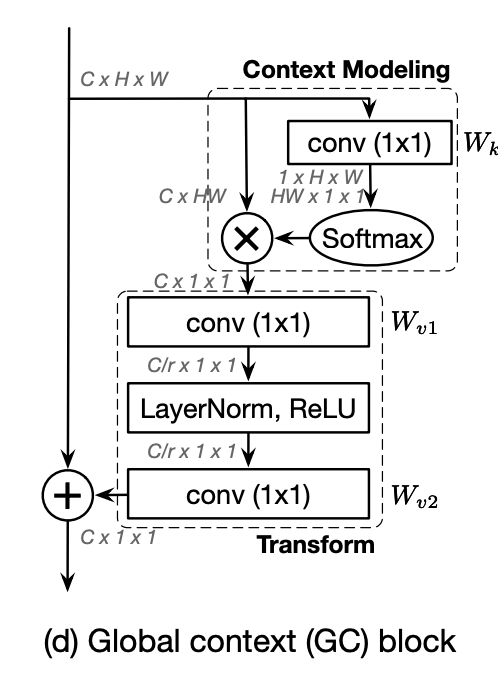
十四、Global Context Block
全局上下文块是用于全局上下文建模的图像模型块。 目的是兼具具有远程依赖性有效建模的简化非局部块和具有轻量级计算的挤压激励块的优点。

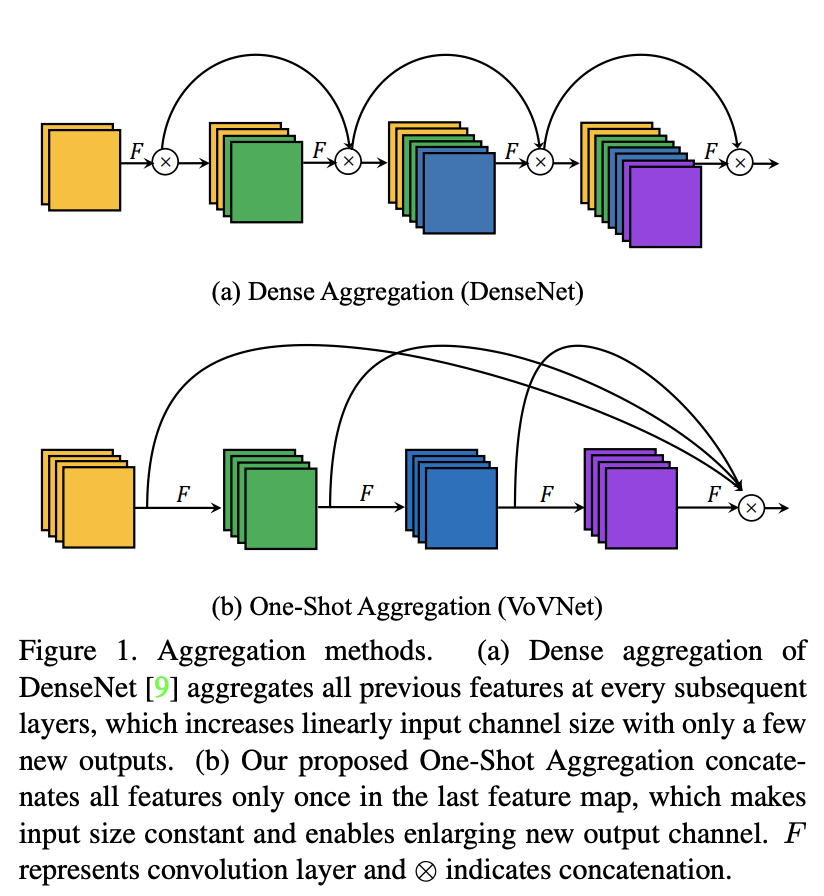
十五、One-Shot Aggregation
One-Shot Aggregation 是一种图像模型块,通过聚合中间特征来替代密集块。 它被提议作为 VoVNet 架构的一部分。 每个卷积层之间采用双向连接。 一种方式连接到后续层以产生具有较大感受野的特征,而另一种方式仅聚合一次到最终输出特征图中。 与 DenseNet 的区别在于,每层的输出不会路由到所有后续的中间层,这使得中间层的输入大小恒定。
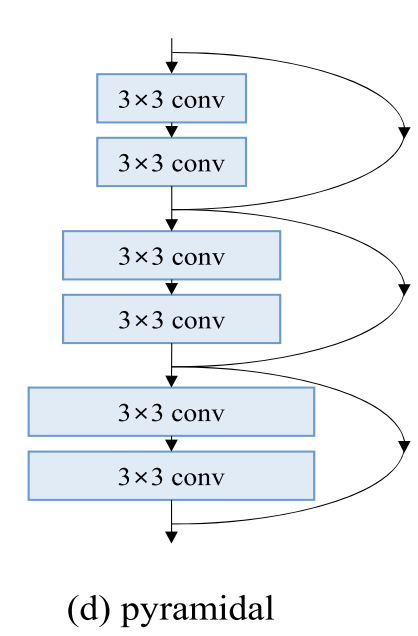
十六、Pyramidal Residual Unit
金字塔残差单元是一种残差单元,其中通道数随着层出现的深度而逐渐增加,类似于形状从顶部向下逐渐变宽的金字塔结构。 它是作为 PyramidNet 架构的一部分引入的。
十七、Pyramidal Bottleneck Residual Unit
金字塔瓶颈残差单元是一种残差单元,其中通道数随着层出现的深度而逐渐增加,类似于形状从上向下逐渐变宽的金字塔结构。 它还包含使用 1x1 卷积的瓶颈。 它是作为 PyramidNet 架构的一部分引入的。
十八、Fractal Block

十九、Transformer in Transformer
Transformer 是一种最初应用于 NLP 任务的基于自注意力的神经网络。 最近,提出了纯基于变压器的模型来解决计算机视觉问题。 这些视觉转换器通常将图像视为一系列补丁,而忽略每个补丁内部的内在结构信息。 在本文中,我们提出了一种新颖的 Transformer-iN-Transformer (TNT) 模型,用于对块级和像素级表示进行建模。 在每个 TNT 块中,外部变压器块用于处理补丁嵌入,内部变压器块从像素嵌入中提取局部特征。 像素级特征通过线性变换层投影到补丁嵌入的空间,然后添加到补丁中。 通过堆叠 TNT 块,我们构建了用于图像识别的 TNT 模型。
二十、Dilated Bottleneck Block
Dilated Bottleneck Block 是 DetNet 卷积神经网络架构中使用的图像模型块。 它采用带有扩张卷积的瓶颈结构来有效地扩大感受野。


















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











