



AI大模型最直接的应用就是智能知识库,知识库提供了根据私域知识问答的能力,可以根据知识库构建智能问答系统、阅读助手等多种产品。知识库一般分为知识抽取、知识构建、知识向量化(Embedding)、知识存储、知识检索增强(RAG)。
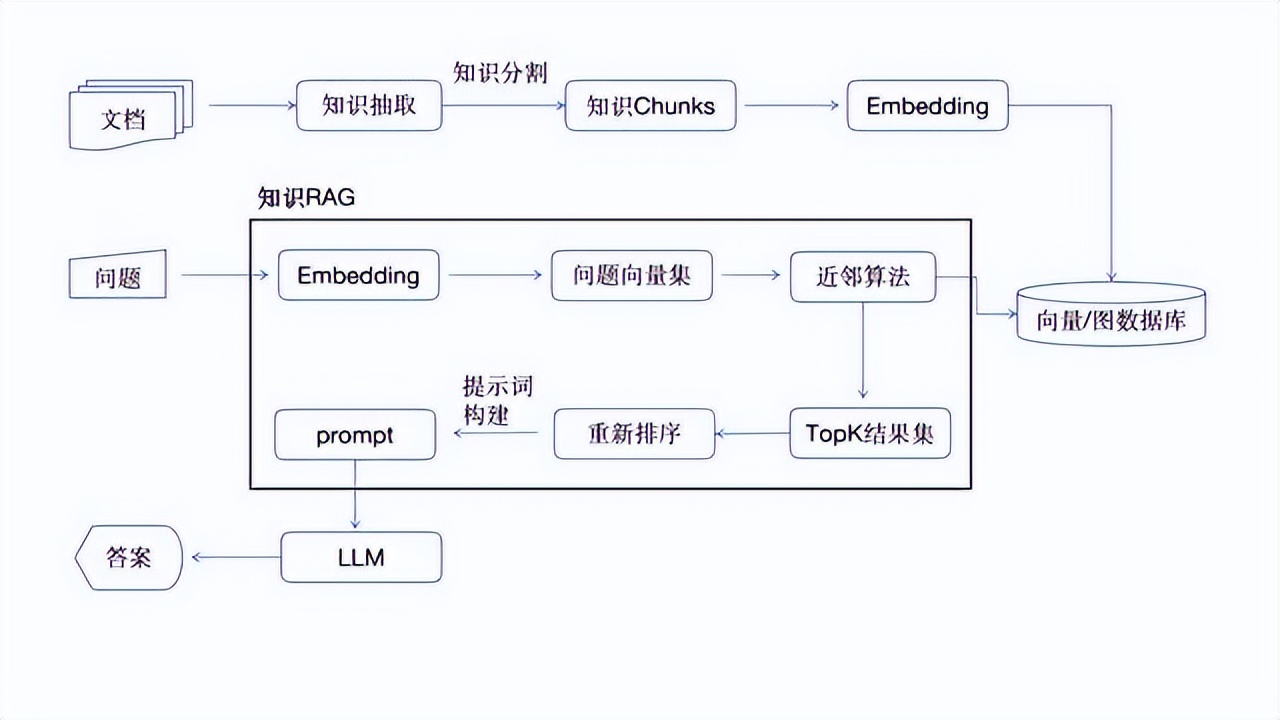
智能知识库工作流程图
知识抽取:对文档进行再加工处理,常用文档包含(word、ppt、excel、pdf、markdown等),其它类型文档一般要转化为常规文档后,再进行知识抽取;
知识抽取一般有两种常用的思路,一种是转化为标准的markdown形式,处理过程中对内嵌图片进行图片地址转换,对公式也转为图片进行地址转换,这种转换通过简单的工具就能实现。缺点是如果图片本身就含有知识内容,就会丢失,仅能在结果展示,没有应用到知识的上下文。
另外一种思路,知识抽取利用多模态大模型的特性,完成对图片、表格、公式,页眉页脚的处理,提取图片,图片的描述,保证知识内容的上下文和完整性。目前推荐使用开源的工具:MinerU,开源库地址:
https://github.com/opendatalab/MinerU/tree/master
该模型特点:
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为LaTeX格式
- 自动识别并转换文档中的表格为HTML格式
- 自动检测扫描版PDF和乱码PDF,并启用OCR功能
- OCR支持84种语言的检测与识别
- 支持多种输出格式,如多模态与NLP的Markdown、按阅读顺序排序的JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检
- 支持纯CPU环境运行,并支持 GPU(CUDA)/NPU(CANN)/MPS 加速
- 兼容Windows、Linux和Mac平台
目前开源的dify,coze(扣子),DB-GBT的知识库都没有知识抽取过程,仅仅支持块的分割,dify2.0准备集成MinerU对知识的抽取,大家可以实时关注。
知识分块的几种方式,见如下表格:

分块方式说明
知识分块完成后,就用通过知识的嵌入模型,把知识转化为向量。向量是一组高纬度的数组,存储在专门的向量数据库或者图数据库,查询的时候问题依然会转化为向量,通过向量之间的近似算法进行匹配。
嵌入模型主要有三种类型,文字类型、图文的多模态类型、边缘类型。
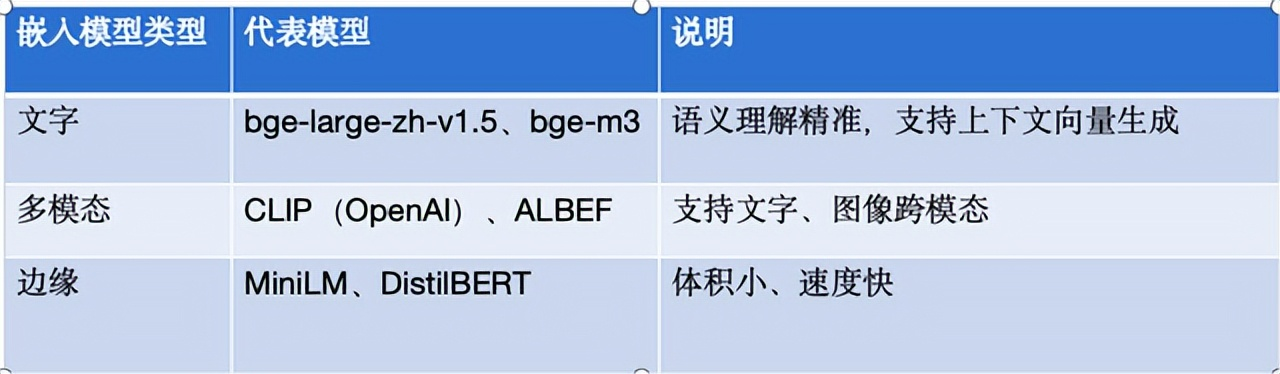
嵌入模型说明
知识存储就是把知识以向量的形式保存在向量数据库中,目前有很多向量数据库,常用的有:chroma、pgvector、milvus、weaviate。大家可以根据自己项目的性能、生态圈、sdk支持情况、数据量大小来决定使用哪种向量数据库。
支持向量的图数据库有tugraph,该库包含嵌入模型,能自动把知识进行知识图谱的生成,根据知识的上下文和关系,在查询的时候,除了近似、还可以根据临近关系给出提示建议。
知识库回答的时候,容易产生以下这些问题:
- 1、知识准确率低,单纯的近似匹配而忽略上下文导致准确率低下,答非所问。
- 2、知识上下文缺少,只能给出匹配片段,没有上下文的环境。
- 3、知识幻觉,LLM在根据知识片段进行补充和润色阶段,容易自己发挥,添加错误或者不严谨的知识。
为了解决这些问题,让知识准确率更高,更精准没有幻觉,且回答更专业,这就需要RAG来发挥作用了,RAG的工作原理如下:
- 首先对问题进行嵌入模型的分析,根据上下文语意转化为一个或者一组向量集合。
- 通过向量的近似算法,从向量数据库中查询出topK各结果集,k一般都是可配置的,通过向量搜索提高准确率,比倒排查询,全文检索更好。
- 对topK的结果集,结合上下文,再根据排序的规则算法,对结果集进行打分,根据新的分数对结果集进行再次排序,这个过程是重新排序(re-rank)。
- 对重新排序后的结果集,再结合上下文的知识库,再根据prompt的动态模块机制,生成一个新的prompt内容,里面包含用户原始问题、结果集、可参考的上下文知识块,回答规则,回答约束,例子等,提高知识的精准度和减少知识幻觉。
把prompt信息发给LLM,有大模型给出最终的答案,返回给用户。

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









