






大家好啊,我是小一
截止今晚的20:58分,本次的抽书活动已经结束,感谢57位参与留言的读者
说真的,没想到这次会有这么多人参与,我原以为可能会和上次送书活动的人数差不多,也就40个人左右。这样抽4条留言,每个人也还会有10%的几率。不过这也说明了留言抽书越来越卷了 ,后面我可能会在朋友圈抽书,大家想参与的可以围观下
,后面我可能会在朋友圈抽书,大家想参与的可以围观下
上面提到的57位读者,有几位删了留言,也有几位是今天才参与的。
按照点赞最后一名送一本的规则,昨天我在推文里也补充了本次抽奖留言上墙截止到昨天凌晨。所以,为了公平起见,今天的留言就没有再翻出来,这几位读者以后可以早早参与哈。
先是点赞最多的:
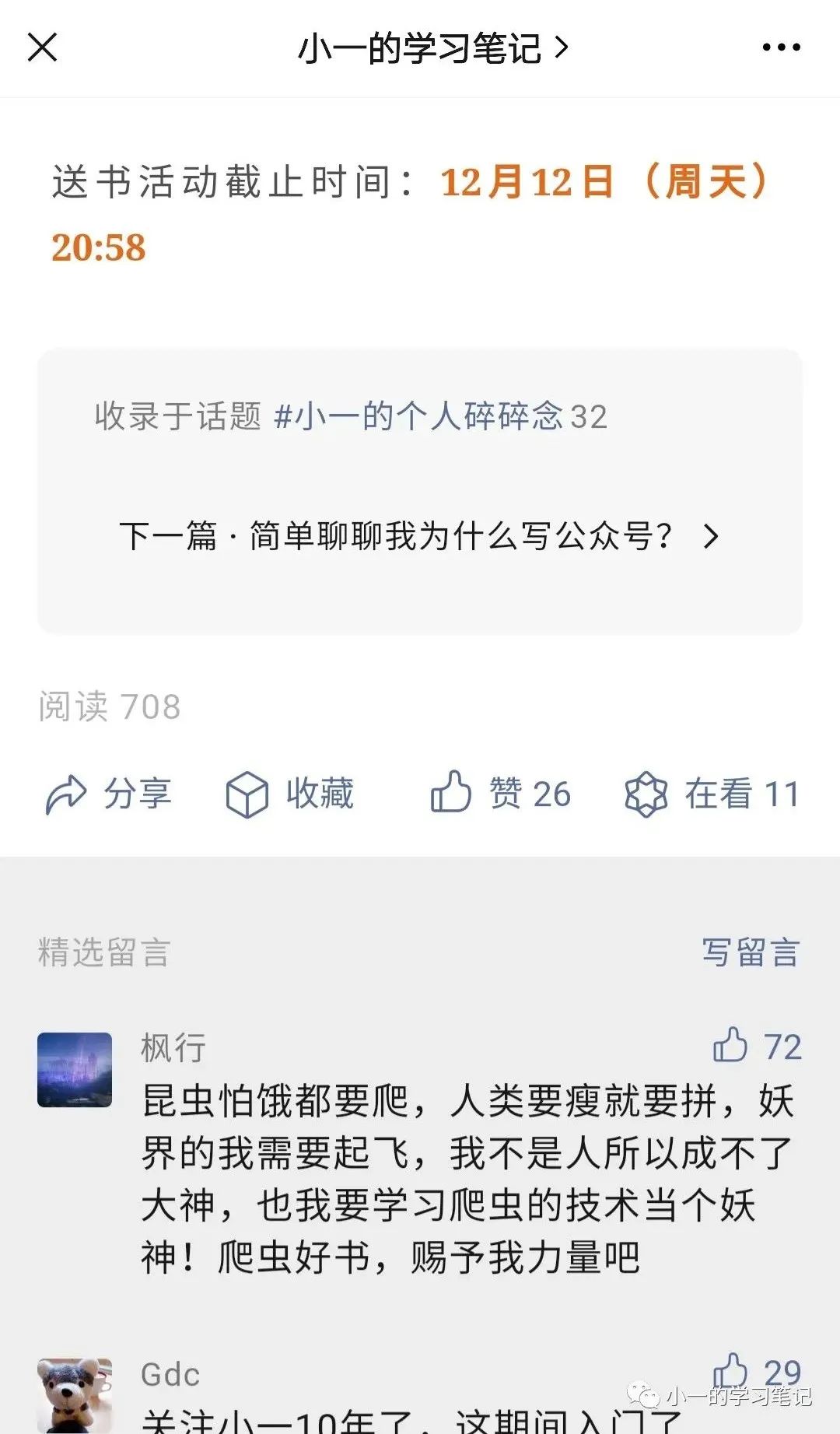
枫行,交流群里很活跃的一位大佬,2020年1月18号关注的,算是我老读者中的老读者了,感谢一路陪伴
再是点赞最少的:
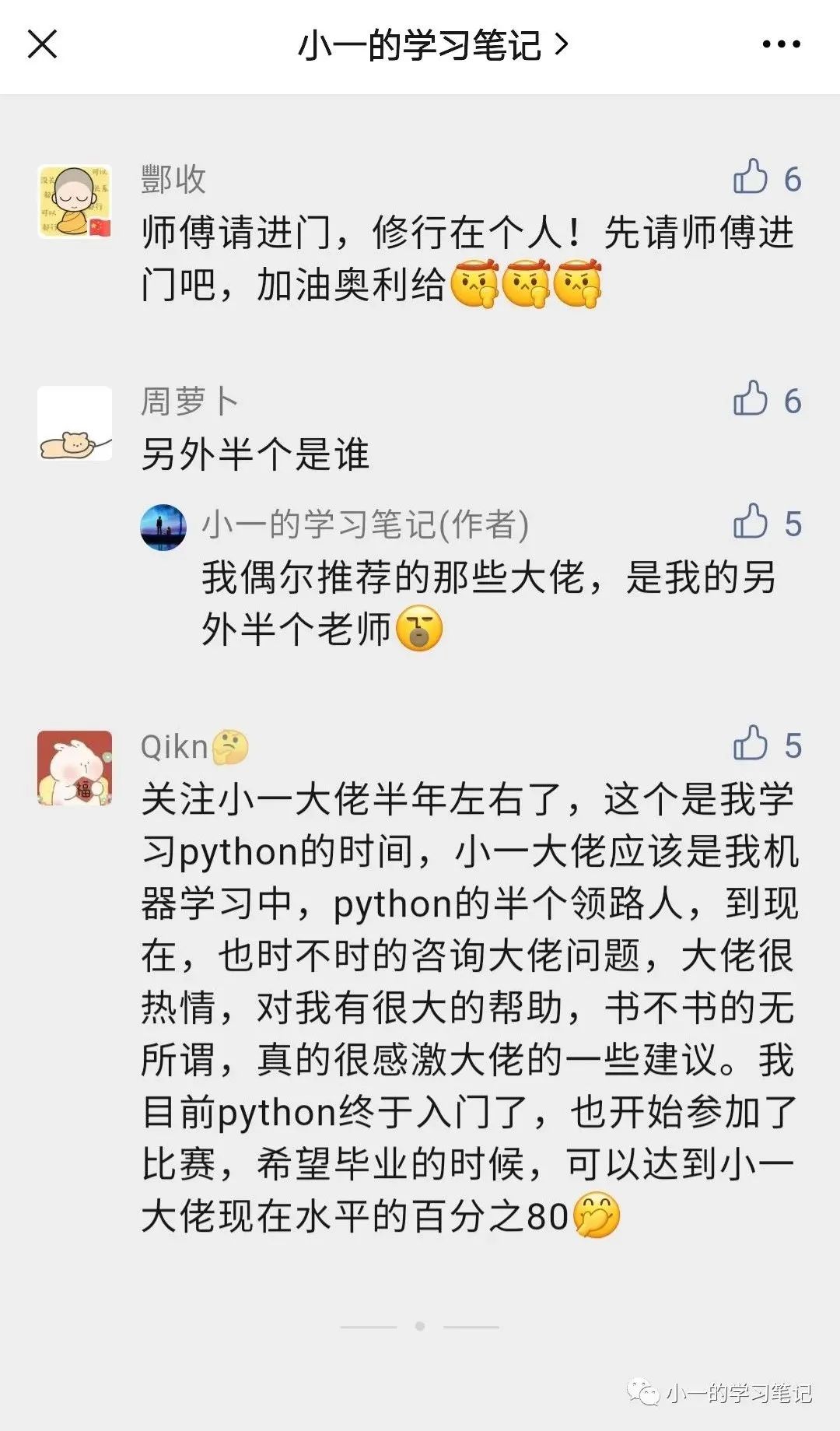
Qikn,今年6月份关注的,不知道为啥你的点赞最少,我觉得你能清楚的记得关注了多久,这点就很走心了!!
最后是两条走心留言,说实话,有点难选,候选的大概有四五条吧,很想给你们都送一本书,但是出版社的赞助有限,4本已经是我把出版社送我的那本也拿出来抽了。
其实出版社在送书的时候一般都会给号主留一本,上次送书也是,但是这两次我都直接全拿出来抽给大家了
走心留言第一条:
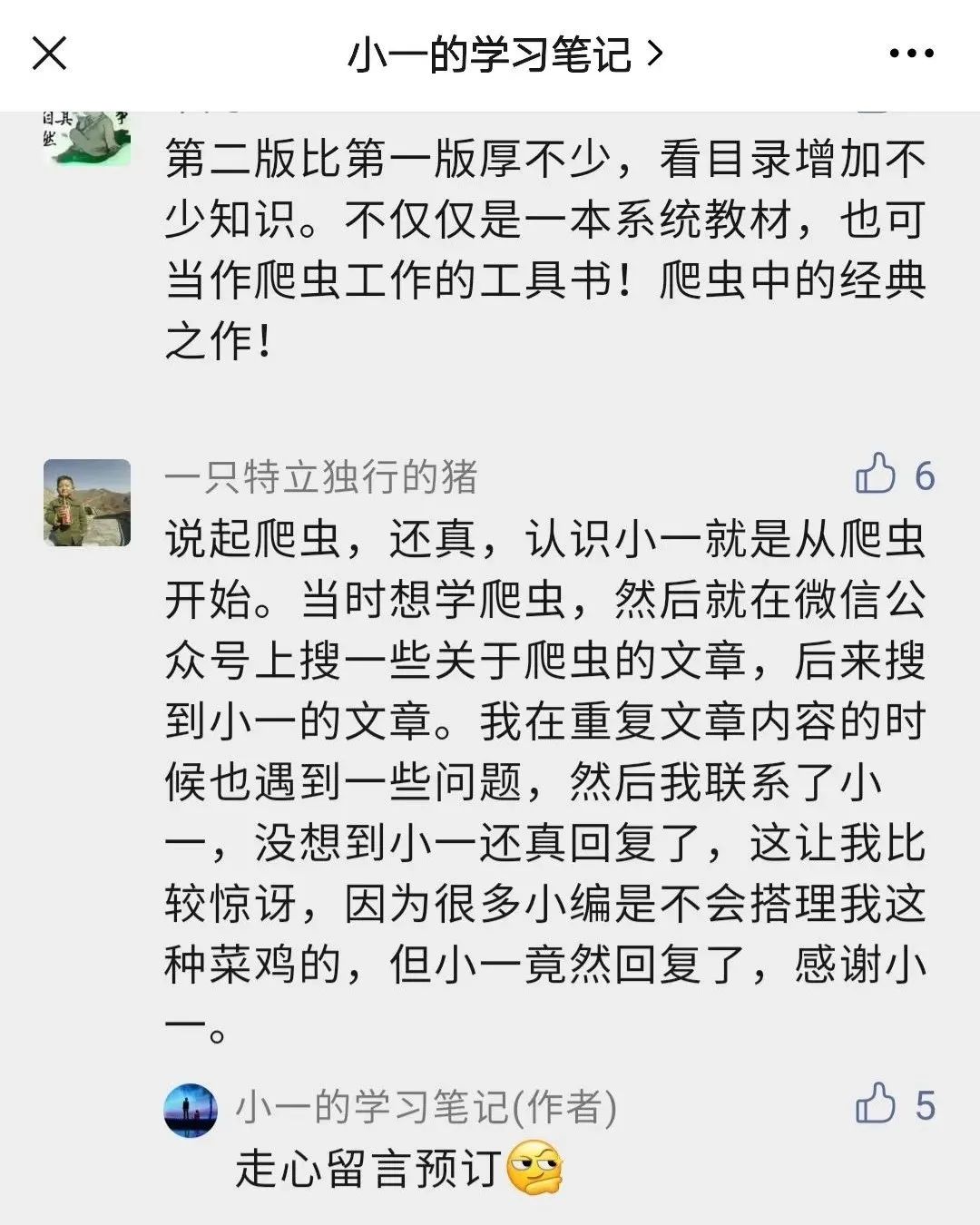
一只特立独行的猪,今年7月份关注的,早期的文章源码都是在github上的,但是因为部分函数做了封装,所以对编程刚入门的小伙伴可能第一次运行会报错,我印象最深的就是 craw_tools 下面的爬虫头部封装的那个函数,有很多人都不知道错哪了。
关于公众号上的源码有什么问题,运行不了的,直接私信我就好,别因为一个小问题把自己吭哧吭哧卡好几天的
走心留言第二条
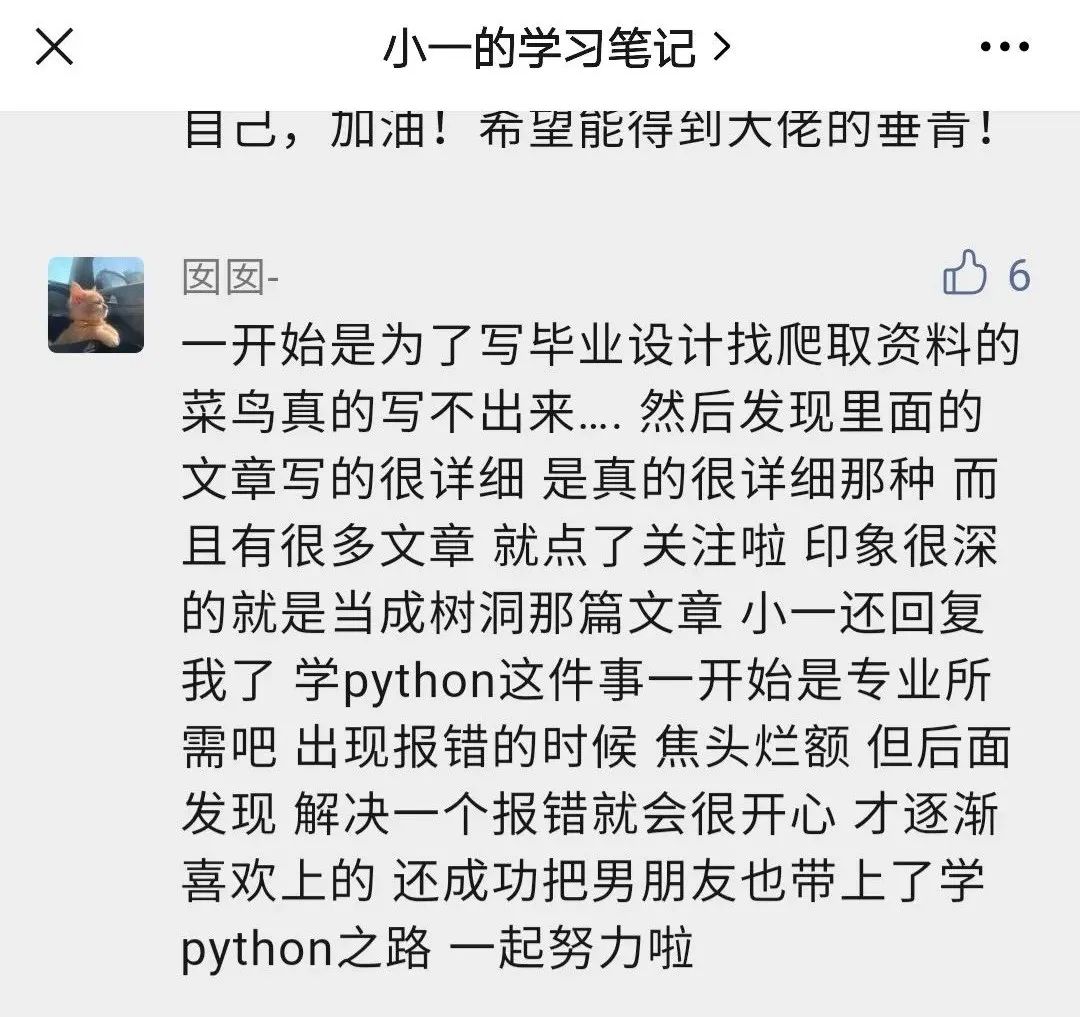
囡囡- 上个月关注的新读者,树洞那篇文章当时确实是我心态有点崩,看到原帖的时候突然就共鸣了,就分享给大家,结果......
不过话说到这,把公众号分享给你男朋友这个要求不过分吧
走心留言第三条
千弦,今年年初关注的,不过这次没书送你了,下次给你预留一本。大话机器学习系列是我自己在学习的时候做的一个笔记,说实话,我刚开始看算法真的是一脸懵,后来学一个算法做一篇实战,发现很有成就感,也就坚持了下来,推荐给大家这种学习算法的方法!

看到你们的留言,以及留言中提到的文章,我仿佛又看到了自己在熬夜写文章的那段时光,
害,时间,终究是从我身旁悄悄滑过
或许,也就只有公众号上的历史文章,和文章下面的一条条留言,我才能回忆起曾经的那段时光
还有很多留言看了之后都很感动的,不过确实名额有限,后面我尽量多抱抱出版社老师的大腿,多给大家争取福利,以后可能会不定时在朋友圈抽书,感兴趣的可以围观小一的朋友圈!

另外,上面中奖的四位读者,没加我微信的可以扫上面的码,顺便发一下地址和收获信息,明天就安排给大家发货
就这,大家晚安!

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









