




 本文提出一种新的视频分类方法TCLSTA,该方法通过双流网络(RGB和光流)捕捉静态和动态信息,并利用空间-时间关注模型强调关键区域和帧,实现静态与动态信息的协同学习和互补。此外,还引入了weights-pooling层以优化特征融合。
本文提出一种新的视频分类方法TCLSTA,该方法通过双流网络(RGB和光流)捕捉静态和动态信息,并利用空间-时间关注模型强调关键区域和帧,实现静态与动态信息的协同学习和互补。此外,还引入了weights-pooling层以优化特征融合。
Two-stream Collaborative Learning with Spatial-Temporal Attention for Video Classification
- 2017年11月
-
- 中国人
之前的算法割裂了时空信息,而我们的方法利用了静态信息和动态信息的互补、时间信息与空间信息的互补。
用于视频分类;双流网络(RGB和光流);CNN+LSTM;提出了weights-pooling。
简介
视频自然由静态和运动信息组成,可以用帧和光流来表示。最近,研究人员普遍采用深度网络来捕捉静态和动态信息,主要有两个局限性:(1)忽略空间和时间关注的共存关系,而要共同建模(2)忽视静态信息和运动信息在视频中共存的强互补性,同时要协同学习,相互促进。
为了解决上述两个限制,提出了一种时空关注的双流协同学习方法TCLSTA,该方法包括两个模型:
(1)空间 - 时间关注模型:空间关注强调框架中的显着区域,水平注意力利用视频中的判别性帧。他们共同学习,相互促进,学习有区别的静态和动作特征,以获得更好的分类性能。
(2)静态协同模型:不仅实现了静态和动态信息的互相引导,促进了特征学习,而且自适应地学习了静态和动态流的融合权重,以利用静态和动态之间的强互补性信息推广视频分类。
算法示意图
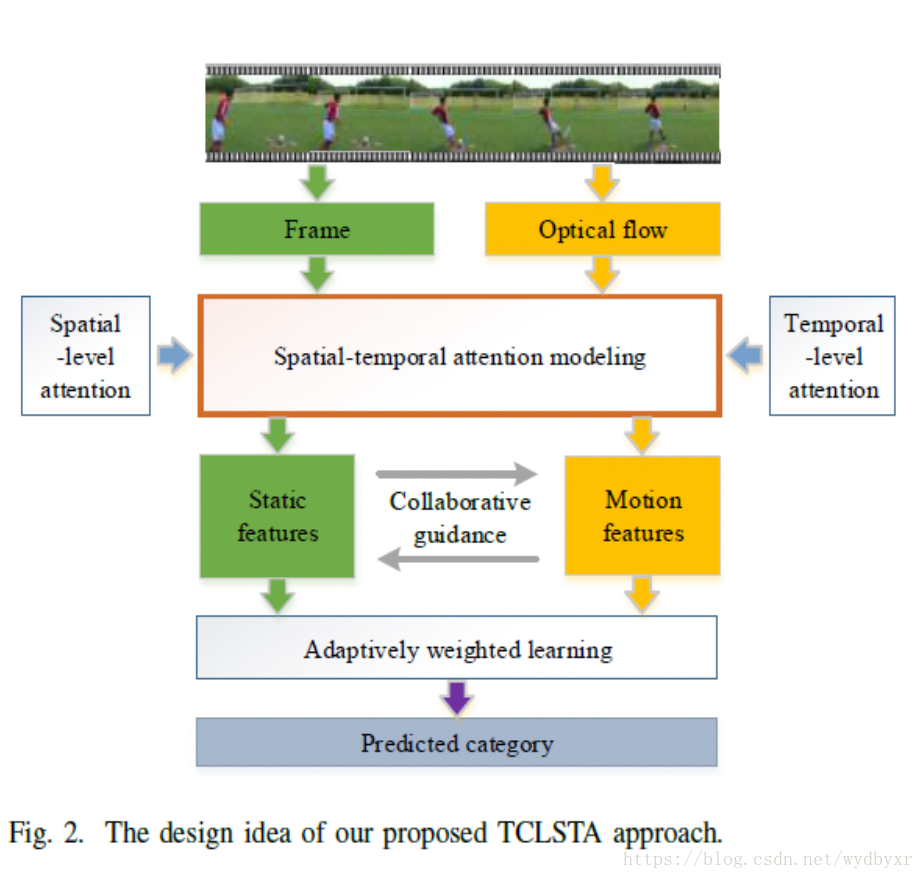
整体结构

weights-pooling
如上图,该层的输入是7*7*2048,输出是1*1*2048,计算时的乘数是图中黄色的softmax的输出1*1*2048
first multiplies the spatial-level attention with the corresponding output of convolutional layer in the same region, then conducts the pooling operation .首先将空间级的注意力与同一区域中卷积层的对应输出相乘,然后进行池操作。
猜测是max-pooling

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









