







 本文详细介绍了CPU设计中的Lab7,涵盖了版本控制、Top顶层接口信号、五级流水线结构以及IF、ID、EXE、MEM、WB各阶段的接口和时序设计。特别讨论了数据通路设计,包括LWX指令处理、存储格式和LWL/LWR指令的实现,以及在设计中遇到的错误和解决方案,如 lw、sb、lwl、lwr、srav、bgez 等指令的处理和调试过程。
本文详细介绍了CPU设计中的Lab7,涵盖了版本控制、Top顶层接口信号、五级流水线结构以及IF、ID、EXE、MEM、WB各阶段的接口和时序设计。特别讨论了数据通路设计,包括LWX指令处理、存储格式和LWL/LWR指令的实现,以及在设计中遇到的错误和解决方案,如 lw、sb、lwl、lwr、srav、bgez 等指令的处理和调试过程。
Lab7 V4.0
版本控制
| 版本 | 描述 |
|---|---|
| V0 | Lab3 |
| V1.0 | Lab3 相对V0变化: 修改了文件名,各阶段以_stage结尾(因为if是关键词,所以module名不能叫if,遂改为if_stage,为了统一命名,将所有module后缀加上_stage) 删除了imm_sign信号(默认对立即数进行有符号数扩展) 由于对sw指令进行了重新理解:无论如何都是需要将rt_data传递给EXE阶段,故将部分译码逻辑进行后移至EXE阶段,避免id_to_exe_data总线过于庞大 将ins_shmat剔除出id_to_exe_data,因为imm包括ins_shamt 对信号进行重命名(例如在ID阶段有个信号叫rf_we,最终要传递给WB阶段,那么在EXE阶段,该信号叫作exe_rf_we,同理mem_rf_we,wb_rf_we),不然都叫rf_we,Debug的时候太痛苦了。 |
| V2.0 | Lab4 相对V1.0的变化 引入`ifdef-`else-`endif来实现相对V1.0的代码增量 增加了旁路控制,减少流水线阻塞(因为增加了旁路,所以修改了ID、EXE、MEM的接口) 修改了ready_go命令,用于控制流水线的阻塞 |
| V3.0 | Lab6(加载的是func_lab6的.coe文件,而不是func_lab5的,因为没有func_lab5这个东西) 相对V2.0的变化:电路细节变化详见:“CPU设计实战电路图”,图中Lab6的变化均以红色背景的方框框起来,并以黄色背景的“Lab6复用/新增信号”标注。本lab6.docx中,新增及修改的信号以红色标注。 删掉了ALU.v的接口,将alu_shamt合并至data_1,方便对新加指令sllv、srlv、srav的数据通路的复用 增加了ID.v中的alu_add的“或门”的输入 扩充了id_to_exe_data总线数据, 因为alu_op扩充了新的指令 添加了imm_zero_ext信号 修改了ins_R、ins_J、ins_I,因为增加了新的指令 乘法器和除法器调用vivado的IP,其周期参数化可配置设计 乘法和除法结果存放的寄存器HI/LO放在WB.v中 增加了sfr.v,用于特殊寄存器的存储 增加了mul_div.v,用于处理乘法和除法。增加了mul.v用于处理乘法,增加了divu.v用于处理无符号除法,增加了divs.v用于处理有符号除法 修改了id_to_exe_data,添加了新信号:imm_zero_ext_en 修改了id_to_exe_data,扩充了alu_op的位宽,并将alu_op调整至id_to_exe_data的最高位,方便未来扩充指令 |
| V4.0 | Lab7 修改了alu_op的位宽 新增了两个bus:lw_bus、sw_bus,同时将mem_rd整合至lw_bus,将mem_we整合至sw_bus 扩大了id_to_exe_data lw_bus传递至MEM阶段结束,sw_bus传递至EXE阶段结束 修改了旁路,之前都是lw的旁路,这里将其扩充了lb、lbu、lh、lhu、lwl、lwr |
Top顶层
接口信号
MYCPU_TOP.v(TOP)
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 取指端访存接口 | |||
| inst_sram_en | 1 | O | 指令RAM使能信号,高电平有效 |
| inst_sram_wen | 4 | O | 指令RAM字节写使能信号,高电平有效 |
| inst_sram_addr | 32 | O | 指令RMA读写地址,字节寻址 |
| inst_sram_wdata | 32 | O | 指令RAM写数据 |
| inst_sram_rdata | 32 | I | 指令RAM读数据 |
| 数据端访存接口 | |||
| data_sram_en | 1 | O | 数据RAM使能信号,高电平有效 |
| data_sram_wen | 4 | O | 数据RAM字节写使能信号,高电平有效 |
| data_sram_addr | 32 | O | 数据RAM读写地址,字节寻址 |
| data_sram_wdata | 32 | O | 数据RAM写数据 |
| data_sram_rdata | 32 | I | 数据RAM读数据 |
| debug信号,供验证平台使用 | |||
| debug_wb_pc | 32 | O | 写回级(多周期最后一级)的PC,需要myCPU里将PC一路传递到写回级 |
| debug_wb_rf_wen | 4 | O | 写回级写寄存器堆(regfiles)的写使能,为字节使能,如果myCPU写regfiles为单字节写使能,则将写使能扩展成4位即可 |
| debug_wb_rf_wnum | 5 | O | 写回级写regfiles的目的寄存器号 |
| debug_wb_rf_wdata | 32 | O | 写回级写regfiles的写数据 |
接口时序
略(MIPS经典五级流水线)
代码结构
MYCPU_TOP.v
|____IF.v
|____ID.v
|____RF.v(2个读端口,1个写端口)
|____SFR.v(1个读端口,2个写端口)
|____EXE.v
|____ALU.v
|____MUL_DIV.v(专门处理乘法和除法)
|____MUL.v
|____DIVU.v
|____DIVS.v
|____MEM.v
|____WB.v
|____MYCPU.h
DATA_RAM.v
IF.v(修改为IF_STAGE,因为会与关键词if冲突)
接口信号
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与TOP | |||
| inst_sram_en | 1 | O | RAM使能信号,高电平有效 |
| inst_sram_wen | 4 | O | RAM字节写使能信号,高电平有效 |
| inst_sram_addr | 32 | O | RMA读写地址,字节寻址 |
| inst_sram_wdata | 32 | O | RAM写数据 |
| inst_sram_rdata | 32 | I | RAM读数据 |
| 与ID | |||
| id_to_if_allowin | 1 | I | pipe allowin |
| if_to_id_vld | 1 | O | pipe valid |
| if_to_id_data | 64 | O | pipe data(instruction 32-bits, pc 32-bits) |
| jump_bus | 33 | I | branch instructions(enable 1bit,address 32-bits) |
接口时序
ID.v
接口信号
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与IF | |||
| id_to_if_allowin | 1 | O | pipe allowin |
| if_to_id_vld | 1 | I | pipe valid |
| if_to_id_data | 64 | I | pipe data(instruction 32-bits, pc 32-bits) |
| jump_bus | 33 | O | branch instructions(enable 1bit,address 32-bits) |
| 与EXE | |||
| exe_to_id_allowin | 1 | I | pipe allowin |
| id_to_exe_vld | 1 | O | pipe valid |
| id_to_exe_data | 162 | O | {alu_op:21, shamt_is_shamt:1, imm_zero_ext_en:1, ins_R:1, ins_I:1, imm:16, mem_rd:1, mem_we:1, rf_we:1, rf_dst_addr:5, rt_data:32, rs_sfr_data_2:32, pc:32} {alu_op:21, shamt_is_shamt:1, imm_zero_ext_en:1, ins_R:1, ins_I:1, imm:16, lwx_bus_less2:8, swx_bus:8, rf_we:4, rf_dst_addr:5, rt_data:32, rs_sfr_data_2:32, pc:32} |
| exe_bypass_bus | 38 | I | {exe_rf_we:1, exe_rf_dst_addr:5, exe_rf_data:32} |
| exe_to_id_sfr_bus | 76 | I | [75] exe_sfr_we1 [74:70] exe_sfr_w_addr1 [69:38] exe_sfr_data1 [37] exe_sfr_we2 [36:32] exe_sfr_w_addr2 [31:0] exe_sfr_data2 |
| lwx_bus_less2 将其合并至id_to_exe_data中 | 10 | O | lwx类总线: ins_lb: 1, ins_lbu: 1, ins_lh: 1, ins_lhu: 1, ins_lwl: 1, ins_lwr: 1, ins_lw: 1, rs_low2: 2 mem_rd: 1 |
| swx_bus 将其合并至id_to_exe_data中 | 8 | O | swx类总线: ins_sb: 1, ins_sh: 1, ins_swl: 1, ins_swr: 1, mem_we[3:0]: 4 |
| mul_div_busy | 1 | I | 正在进行乘法或除法运算 |
| 与MEM | |||
| mem_bypass_bus | 38 | I | {mem_rf_we:1, mem_rf_dst_addr:5, mem_rf_data:32} |
| 与WB | |||
| wb_to_rf_bus | 41 | I | {rf_we:4, rf_addr:5, rf_data:32} |
接口信号(RF.v)
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| 与ID内部信号 | |||
| rf_r_addr1 | 5 | I | RF读地址1 |
| rf_r_data1 | 32 | O | RF读数据1 |
| rf_r_addr2 | 5 | I | RF读地址2 |
| rf_r_data2 | 32 | O | RF读数据2 |
| rf_wen1 | 4 | I | RF写使能1 |
| rf_w_addr1 | 5 | I | RF写地址1 |
| rf_w_data1 | 32 | O | RF写数据1 |
接口信号(SFR)
当写入同一地址时,以sfr_we_1优先
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与ID内部信号 | |||
| sfr_r_addr1 | 5 | I | SFR读地址1 |
| sfr_r_data1 | 32 | O | SFR读数据1 |
| sfr_we_1 | 1 | I | SFR写使能1 |
| sfr_w_addr1 | 5 | I | SFR写地址1 |
| sfr_w_data1 | 32 | I | SFR写数据1 |
| sfr_we_2 | 1 | I | SFR写使能2 |
| sfr_w_addr2 | 5 | I | SFR写地址2 |
| sfr_w_data2 | 32 | I | SFR写数据2 |
接口时序
电路设计
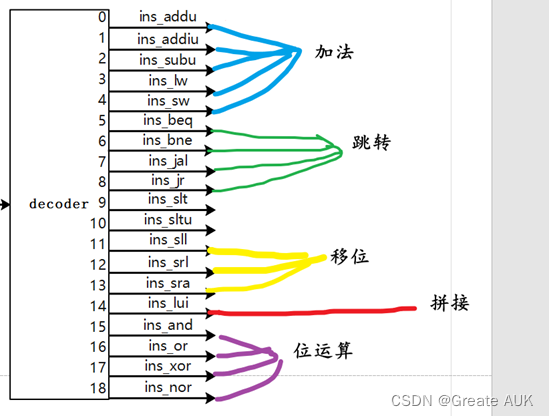
图3-4-1 译码电路分组(注:黄线少画了两条)
根据附录——MIPS指令。由于跳转指令不传递给EXE阶段,直接传递给IF阶段,且为纯组合逻辑输出,有可能成为关键路径,故对跳转指令单独处理。除了跳转指令外,涉及加法(减法归为加法)的指令如图3-4-1所示,即ins_addu、ins_addiu、ins_subu、ins_lw、ins_sw。
对于图3-4-1的拼接运算,可以当作移位运算执行。
EXE.v
接口信号
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与TOP(外接的DATA_RAM) | |||
| data_sram_en | 1 | O | 数据RAM使能信号,高电平有效 |
| data_sram_wen | 4 | O | 数据RAM字节写使能信号,高电平有效(4个比特,应该代表32 = 4 bytes) |
| data_sram_addr | 32 | O | 数据RAM读写地址,字节寻址 |
| data_sram_wdata | 32 | O | 数据RAM写数据 |
| 与ID | |||
| exe_to_id_allowin | 1 | O | pipe allowin |
| id_to_exe_vld | 1 | I | pipe valid |
| id_to_exe_data | 162 | O | {alu_op:21, shamt_is_shamt:1, imm_zero_ext_en:1, ins_R:1, ins_I:1, imm:16, mem_rd:1, mem_we:1, rf_we:1, rf_dst_addr:5, rt_data:32, rs_sfr_data_2:32, pc:32} {alu_op:21, shamt_is_shamt:1, imm_zero_ext_en:1, ins_R:1, ins_I:1, imm:16, lwx_bus_less2:10, swx_bus:8, rf_we:4, rf_dst_addr:5, rt_data:32, rs_sfr_data_2:32, pc:32} |
| exe_bypass_bus | 41 | O | {exe_rf_we:4, exe_rf_dst_addr:5, exe_rf_data:32} |
| exe_to_id_sfr_bus | 76 | O | [75] exe_sfr_we1 [74:70] exe_sfr_w_addr1 [69:38] exe_sfr_data1 [37] exe_sfr_we2 [36:32] exe_sfr_w_addr2 [31:0] exe_sfr_data2 |
| mul_div_busy | 1 | O | 正在进行乘法或除法运算 |
| lwx_bus 将其合并至id_to_exe_data中 | 10 | I | lwx类总线: ins_lb: 1, ins_lbu: 1, ins_lh: 1, ins_lhu: 1, ins_lwl: 1, ins_lwr: 1, ins_lw: 1, rs_low2: 2 mem_rd: 1 |
| swx_bus 将其合并至id_to_exe_data中 | 8 | I | swx类总线: ins_sb: 1, ins_sh: 1, ins_swl: 1, ins_swr: 1, mem_we[3:0]: 4 |
| 与MEM | |||
| mem_to_id_allowin | 1 | I | pipe allowin |
| exe_to_mem_vld | 1 | O | pipe valid |
| exe_to_mem_data | 83 | O | {mem_rd:1, rf_we:1, rf_dst_addr:5, pc:32(其实可以删掉pc,这里是debug显示用的,可以叫debug_pc), exe_result:32 {lwx_bus:10, rf_we:4, rf_dst_addr:5, pc:32(其实可以删掉pc,这里是debug显示用的,可以叫debug_pc), exe_result:32 |
| lwx_bus 将其合并至id_to_exe_data中 | 10 | O | lwx类总线: ins_lb: 1, ins_lbu: 1, ins_lh: 1, ins_lhu: 1, ins_lwl: 1, ins_lwr: 1, ins_lw: 1, rs_low2: 2 mem_rd: 1 |
接口信号(ALU.v)
暂时不需要时钟和复位,纯组合逻辑
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与ID内部信号 | |||
| alu_shamt | 6 | I | ALU移位(R-指令的shamt部分) |
| alu_op | 19 | I | ALU操作(加、减、乘除、位运算) |
| alu_din1 | 32 | I | ALU输入1 |
| alu_din2 | 32 | I | ALU输入2 |
| alu_out | 32 | O | ALU输出 |
| mul_div_busy | 1 | O | 正在进行乘法或除法运算 |
接口信号(MUL_DIV.v)
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与ALU内部信号 | |||
| alu_mult | 1 | I | 有符号乘 |
| alu_multu | 1 | I | 无符号乘 |
| alu_div | 1 | I | 有符号除 |
| alu_divu | 1 | I | 无符号除 |
| alu_mthi | 1 | I | 将寄存器 rs 的值写入到 HI 寄存器中 |
| alu_mtlo | 1 | I | 将寄存器 rs 的值写入到LO寄存器中 |
| alu_din1 | 32 | I | ALU输入1 |
| alu_din2 | 32 | I | ALU输入2 |
| exe_to_id_sfr_bus | 76 | O | [75] exe_sfr_we1 [74:70] exe_sfr_w_addr1 [69:38] exe_sfr_data1 [37] exe_sfr_we2 [36:32] exe_sfr_w_addr2 [31:0] exe_sfr_data2 |
| mul_div_busy | 1 | O | 正在进行乘法或除法运算 |
接口信号MUL.v
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与ALU内部信号 | |||
| mul_din_vld | 1 | I | 数据有效信号 |
| mul_din1 | 33 | I | 乘数1 |
| mul_din2 | 33 | I | 乘数2 |
| mul_result_hi | 32 | O | 乘法高32位 |
| mul_result_lo | 32 | O | 乘法低32位 |
接口信号DIVU.v
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与ALU内部信号 | |||
| divu_din_vld | 1 | I | 数据有效信号 |
| divu_din1 | 33 | I | 被除数 |
| divu_din2 | 33 | I | 除数 |
| divu_hi | 32 | O | 结果高32位 |
| divu_lo | 32 | O | 结果低32位 |
接口信号DIVS.v
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与ALU内部信号 | |||
| divs_din_vld | 1 | I | 数据有效信号 |
| divs_din1 | 33 | I | 被除数 |
| divs_din2 | 33 | I | 除数 |
| divs_hi | 32 | O | 结果高32位 |
| divs_lo | 32 | O | 结果低32位 |
接口时序
MEM.v
接口信号
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与TOP(外接的DATA_RAM) | |||
| data_sram_rdata | 32 | I | 数据RAM读数据 |
| 与EXE | |||
| mem_to_exe_allowin | 1 | O | pipe allowin |
| exe_to_mem_vld | 1 | I | pipe valid |
| exe_to_mem_data | 83 | I | {mem_rd:1, rf_we:1, rf_dst_addr:5, pc:32(其实可以删掉pc,这里是debug显示用的,可以叫debug_pc), exe_result:32} {lwx_bus: 10, rf_we:4, rf_dst_addr:5, pc:32(其实可以删掉pc,这里是debug显示用的,可以叫debug_pc), exe_result:32} |
| lwx_bus 将其合并至id_to_exe_data中 | 10 | I | lwx类总线: ins_lb: 1, ins_lbu: 1, ins_lh: 1, ins_lhu: 1, ins_lwl: 1, ins_lwr: 1, ins_lw: 1, rs_low2: 2 mem_rd: 1 |
| 与WB | |||
| wb_to_mem_allowin | 1 | I | pipe allowin |
| mem_to_wb_vld | 1 | O | pipe valid |
| mem_to_wb_data | 73 | O | { rf_we:4, rf_dst_addr:5, mem_result:32, pc:32(其实可以删掉pc,这里是debug显示用的,可以叫debug_pc)} |
| 与ID | |||
| mem_bypass_bus | 38 | O | {mem_rf_we:4, mem_rf_dst_addr:5, mem_rf_data:32} |
WB.v
接口信号
| 名称 | 宽度 | 方向 | 描述 |
|---|---|---|---|
| 时钟与复位 | |||
| clk | 1 | I | 时钟信号,来自clk_pll的输出时钟 |
| resetn | 1 | I | 复位信号,低电平同步复位 |
| 与TOP | |||
| debug_wb_pc | 32 | O | 写回级(多周期最后一级)的PC,需要myCPU里将PC一路传递到写回级(与原书保持一致) |
| debug_wb_rf_wen | 4 | O | 写回级写寄存器堆(regfiles)的写使能,为字节使能,如果myCPU写regfiles为单字节写使能,则将写使能扩展成4位即可(与原书保持一致) |
| debug_wb_rf_wnum | 5 | O | 写回级写regfiles的目的寄存器号(与原书保持一致) |
| debug_wb_rf_wdata | 32 | O | 写回级写regfiles的写数据(与原书保持一致) |
| 与MEM | |||
| wb_to_mem_allowin | 1 | O | pipe allowin |
| mem_to_wb_vld | 1 | I | pipe valid |
| mem_to_wb_data | 73 | I | { rf_we:4, rf_dst_addr:5, mem_result:32, pc:32(其实可以删掉pc,这里是debug显示用的,可以叫debug_pc)} |
| 与ID | |||
| wb_to_rf_bus | 41 | O | {rf_we:4, rf_addr:5, rf_data:32} |
接口时序
附录——参考
附录——原书指令
| 指令 | sel_nextpc | inst_ram_wen | inst_ram_wen | sel_alu_src1 | sel_alu_src2 | alu_op | data_ram_en | data_ram_wen | rf_we | sel_rf_dst | sel_rf_res |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ADDU | 0001 | 1 | 0 | 001 | 001 | 000000000001 | 0 | 0 | 1 | 001 | 0 |
| ADDIU | 0001 | 1 | 0 | 001 | 010 | 000000000001 | 0 | 0 | 1 | 010 | 0 |
| SUBU | 0001 | 1 | 0 | 001 | 001 | 000000000010 | 0 | 0 | 1 | 001 | 0 |
| LW | 0001 | 1 | 0 | 001 | 010 | 000000000001 | 1 | 0 | 1 | 010 | 1 |
| SW | 0001 | 1 | 0 | 001 | 010 | 000000000001 | 1 | 1 | 0 | 000 | 0 |
| BEQ | 0010 | 1 | 0 | 000 | 000 | 000000000000 | 0 | 0 | 0 | 000 | 0 |
| BNE | 0010 | 1 | 0 | 000 | 000 | 000000000000 | 0 | 0 | 0 | 000 | 0 |
| JAL | 0100 | 1 | 0 | 010 | 100 | 000000000001 | 0 | 0 | 1 | 100 | 0 |
| JR | 1000 | 1 | 0 | 000 | 000 | 000000000000 | 0 | 0 | 0 | 000 | 0 |
| SLT | 0001 | 1 | 0 | 001 | 001 | 000000000100 | 0 | 0 | 1 | 001 | 0 |
| SLTU | 0001 | 1 | 0 | 001 | 001 | 000000001000 | 0 | 0 | 1 | 001 | 0 |
| SLL | 0001 | 1 | 0 | 100 | 001 | 000100000000 | 0 | 0 | 1 | 001 | 0 |
| SRL | 0001 | 1 | 0 | 100 | 001 | 001000000000 | 0 | 0 | 1 | 001 | 0 |
| SRA | 0001 | 1 | 0 | 100 | 001 | 010000000000 | 0 | 0 | 1 | 001 | 0 |
| LUI | 0001 | 1 | 0 | 000 | 010 | 100000000000 | 0 | 0 | 1 | 010 | 0 |
| AND | 0001 | 1 | 0 | 001 | 001 | 000000010000 | 0 | 0 | 1 | 001 | 0 |
| OR | 0001 | 1 | 0 | 001 | 001 | 000001000000 | 0 | 0 | 1 | 001 | 0 |
| XOR | 0001 | 1 | 0 | 001 | 001 | 000010000000 | 0 | 0 | 1 | 001 | 0 |
| NOR | 0001 | 1 | 0 | 001 | 001 | 000000100000 | 0 | 0 | 1 | 001 | 0 |
Lab7完结
Lab7 后记
指令分析
摘自原书第6章
Lab7需要添加的指令如下:
MIPS中的转移指令包括分支指令(B开头)和跳转指令(J开头),前者是否跳转需要进行判断,后者一定跳转。
| BGEZ | 类似BEQ和BNE,就是判断条件不同。(不写回寄存器) |
|---|---|
| BGTZ | |
| BLEZ | |
| BLTZ | |
| J | JAL的指令的一半,只跳转,不写回寄存器 |
| BLTZAL | =BLTZ + JAL的写回寄存器31 |
| BGEZAL | =BGEZ + JAL的写回寄存器31 |
| JALR | =JR/JAL + 写回寄存器rd(是R型指令,默认写回的寄存器就是rd) 在ID阶段的PC跳转利用JR指令 在IDEXEMEMWB的写回寄存器操作复用JAL指令 |
| 分隔行--------------------------------------------------分隔行 | |
| LB | 取字节,并进行 有/无 符号扩展 可复用lw指令 |
| LBU | |
| LH | 取双字节(半字),并进行 有/无 符号扩展 可复用lw指令 |
| LHU | |
| LWL | 详见:lab7\V4\doc\ 指令释义(LWL_LWR_SWL_SWR).xlsx |
| LWR | |
| SB | 存字节 |
| SH | 存双字节(半字) |
| SWL | 详见:lab7\V4\doc\ 指令释义(LWL_LWR_SWL_SWR).xlsx |
| SWR |
SB与SH
摘自原书第6章P160
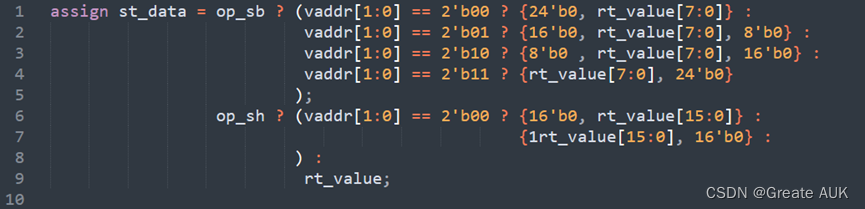
上面的代码,可以改为如下代码,并通过字节使能进行控制。下面的代码更简洁、逻辑更少、时序更好。

LWX指令
| LB |
|---|
| LBU |
| LH |
| LHU |
| LWL |
| LWR |
- 更新旁路,这几条指令的整体通路与LW指令类似,所以旁路与阻塞是必定要更新的
- 存储格式:注意,原书上P161明确指出:“现在,一般处理器中数据存储和处理实现为小尾端模式,本章设计的CPU也是如此,所以我们只需要实现小尾端模式下的非对齐访存”所以必须按小端处理,不然测试都没法测试。
- LWX指令
- 存储格式:注意,原书上P161明确指出:“现在,一般处理器中数据存储和处理实现为小尾端模式,本章设计的CPU也是如此,所以我们只需要实现小尾端模式下的非对齐访存”所以必须按小端处理,不然测试都没法测试。
| LB | |
|---|---|
| LBU | |
| LH | |
| LHU | |
| LWL | |
| LWR |
LWX指令与SWX指令
lwxxxx与swxxx指令:
-
与lw、sw指令类似,数据通路相同
-
关于书P163~P164的两种方案,我也陷入了纠结。
最终我选择了方案一。理由如下:方案二不利于软件优化且性能较低,因为方案二增加了流水线阻塞的概率。方案二看似增加了
原书P163~P164两种方案如下:
其次,LWL 和LWR 指令需要根据访存地址最低两位的情况用数据 RAM 取出的字内容的一部分更新目的寄存器的部分内容。这里的“只对目的寄存器进行部分更新”是一个新特性,需要我们重点关注。
有两种设计方案:一是为通用寄存器堆添加字节写使能信号,使其支持部分写;二是将目的寄存器作为源操作数,读取其旧值与待写人新值,拼接成最终的 32 位结果,再整体写回寄存器堆。两种方法各有优劣,我们来逐一分析。
方案一:
方案一的优点是不会与已执行的指令因目的寄存器而产生写后读相关关系,换言之,它
不会像方案二那样因为微结构实现而引人一种“非软件所期待的相关”。它的缺点是,要对寄存器堆和数据前递的逻辑进行大范围调整。寄存器堆的设计调整很好理解: 原来一次写满-项的 4个字节,现在一次只能写其中的若干个字节,显然要对寄存器的写控制信号进行调整。Verilog代码的修改也很简单,把现在 1比特的写使能改为 4 比特,然后把原来的写入逻辑拆分成四等份,每份都是一个字节宽,每份只用新写使能中的一个比特作为写使能。但是,很多初学者修改完寄存器堆就结束了,忘记还要调整数据前递的逻辑。当然,为了绕过这个“坑”,我们也可以不对 LWL 和 LWR 做数据前递。这个解决方法虽然对,但它是个“懒人的办法”,并不高效。所以,建议还是修改前递数据通路,原先访存级、写回级送到译码级的写目的寄存器的有效信号只有 1比特,要把它像寄存器堆那样拆成4个字节独立控制的4个有效信号。相应地,译码级的 32 位宽的前递数据多选一部分也要拆分成4个8位宽的部分。单纯从逻辑来看,译码级的多路选择器的电路资源并没有增加。当我们把这层“窗户纸”捅破之后,方案一实现起来也不那么复杂了。那么这个方案是不是完美方案呢?接下来我们再“加点料”,说说这个方案在功耗控制方面的一点“小坑”这部分内容难度较大,而且与 FPGA 这样的实现平台无关,因此仅供有兴趣进一步研究系统结构的读者参考,这里算是先开个小灶。
首先要注意几个关键词:静态功耗、动态功耗、时钟网络功耗、动态功耗优化、时钟门控技术。这些知识点需要太多篇幅来展开介绍,请读者自行上网查资料自学。总之,你应该有这样的总体认识:CPU 这样的数字逻辑电路的功耗可简单分为静态功耗和动态功耗两部分;时钟网络功耗和触发器的动态功耗在 CPU 的动态功耗中占比显著;时钟门控技术是一种降低时钟网络功耗和触发器动态功耗的常用技术,它使用时钟门控单元在触发器不需要更新时关断其时钟,目前主流 EDA 工具在综合实现过程中会自行插人时钟门控单元。了解了这些知识,再来看方案一的代码调整,如果不加任何处理,新代码的寄存器堆 EDA 工具会插入 128 个时钟门控单元,而旧代码的寄存器堆只有 32 个时钟门控单元。观察寄存器堆没有写入请求时的功耗,而新代码的功耗显著高于旧代码,为什么? 原因就在多出的那96个时钟门控单元上。因此,方案一会导致 CPU 轻负载情况下平均功耗的增加。一旦知道问题出在哪里,我们就有办法优化。考虑到 LWL 和 LWR 指令的出现频率并不是很高,大部分情况下,寄存器还是一次写入4个字节,所以我们调整代码的书写风格,使得 EDA 自动插入的门控时钟单元还是每一项只配一个。最终代码如下:

方案二:
方案二的优点与方案一的缺点互补,即整个寄存器堆以及数据前递逻辑都不需要进行调整。显然,此时目的寄存器要作为源操作数读出来。好在读第rt 项寄存器的数据通路已经存在,我们复用即可。但是,千万不要忘记将 LWL 和 LWR 指令的 rt 域作为源操作数添加到存器相关判断逻辑中。此外,rt 项读出的数据原本没有传递到访存流水级,这也需要添加相应的数据通路。至于寄存器的旧值和数据 RAM 的返回值如何拼接成最终的32 位结果,这逻辑不复杂,我们就不详细说明了。方案二的缺点在前面分析方案一的时候已经提到过,就是因为微结构实现而引人了一种“非软件所期待的相关”,也就是明明 rt 是 LWL 和 LWR的目的寄存器,但是如果前面有一个写rt 寄存器的操作,LWL 和 LWR 就需要等它的值。这个现象是否常见呢?其实很常见,回顾《计算机体系结构基础(第 2 版)》中 2.5.4 节第(1)部分给出的示例,你会发现,如果用一个 LWL+LWR 指令对来实现一个非字对齐地址上的取字操作,这两条指令之间就会产生这种“非软件所期待的相关”,从而造成一拍的阻塞,即需要 3个周期而非 2个周期才能执行完一个字的读取操作。
那么方案一和方案二哪个更好呢?读者可以按照自己的喜好自行选择。如果你愿意为了追求性能不怕麻烦,那么方案一更胜一筹
-
lwl等指令
lwl、lwr、swl、swr指令文档中没有写其指令编码,本人依据此链接下的编码进行编写:32位mips指令说明_lbu指令什么意思-优快云博客
rf_we与mem_we
- 刚开始本人将这两个信号均在ID阶段实现,后来发现指令忘读了,lwl、swl等指令是根据ALU出来的加法结果来决定rf_we和mem_we的,因此不可能在ID阶段就实现。mem_we还好,因为不会涉及旁路,但是rf_we会影响旁路,但是rf_we在ID阶段不出来信号,就会影响exeID的旁路检测,故本人决定“造假”,即对于lwl、swl等指令在ID阶段,强制将rf_we置为全1,在exe阶段等ALU的加法结果出来后,再更正rf_we的结果。
- 对mem_we也进行造假,在ID阶段,将其置为全1,在EXE阶段再更正mem_we的结果(可以直接删掉mem_we的,但是这个信号后面还会用于判断,为了避免过度耦合,并且也只多出了4个寄存器,我接受了)。
RAM格式
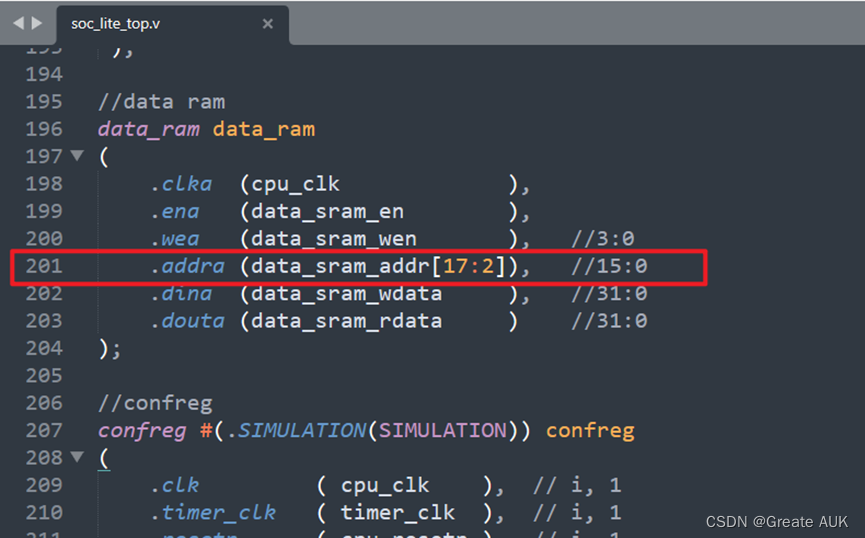
之前的data_ram的读写地址都是4的整数倍,所以不需要关注字节、半字长这种数据操作时的读写地址,但是Lab7涉及lb、lh、lwl、sb等指令,有必要关注一波:
- 在soc_lite_top.v中,可以看到读写地址并没有使用32bits,而是只使用了16bits,如下图所示:[17:2],所以可以见得这是将读写地址的低2位给忽略了,基于此才可以正确设计lb、lh等指令的数据通路。
LAB7——Debug
语法报错拼接
{8{bypass_rf_we_reverse[3]}, 8{bypass_rf_we_reverse[2]},8{bypass_rf_we_reverse[1]}, 8{bypass_rf_we_reverse[0]}}
改为:
{{8{bypass_rf_we_reverse[3]}}, {8{bypass_rf_we_reverse[2]}},{8{bypass_rf_we_reverse[1]}}, {8{bypass_rf_we_reverse[0]}}}
lw报错
控制信号都是对的,应该是数据错了,经排查发现错误:

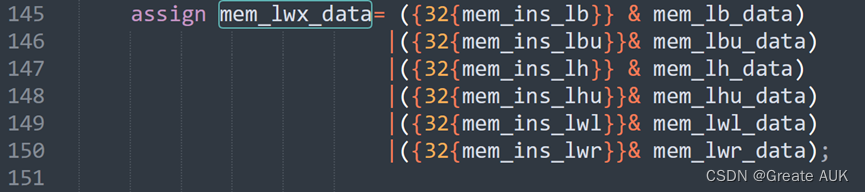
改为:
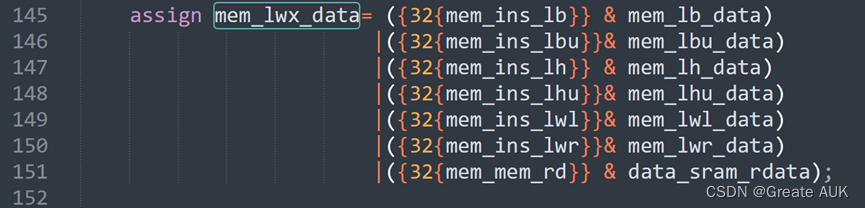
srav报错

-
这条指令就当是Lab6检查出来错误的,然而Lab6并没有报错,但是在Lab7进行的过程中报错了。
-
解决该Bug实际消耗本人一整天,从第一天晚上开始到第二天下午结束。
-
经过本人反复验证,重新添加inst_ram.coe,重新多次simulation,并反复计算验证,最终确定数据通路、控制通路没有问题,于是本人开始怀疑官方给的测试代码是不是有问题:
首先明确指令:
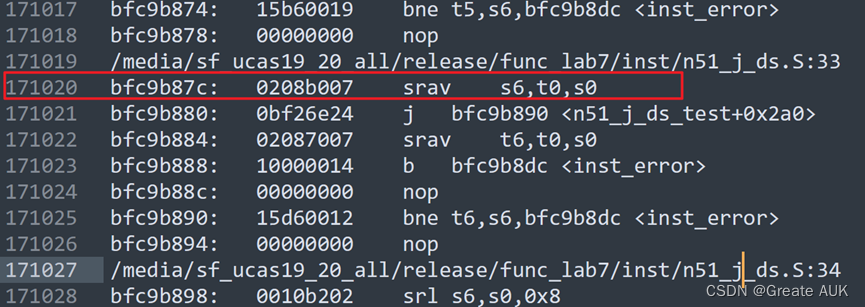
t0寄存器编号为8,s0寄存器编号为16(16进制下为10)
-
-
-
cpu132_gettrace工程下t0值为0x800d0000,s0的值为0x33
-
mycpu_verify工程下t0值为0x800d0000,s0的值为0x33
即数据是一样的,就看是怎样执行的了:
-
cpu132_gettrace工程下为0x800d0000 >>> 0x13 = 0xfffff_0001
-
mycpu_verify工程下t0值为0x800d0000>>> 0x33 = 0xffff_ffff
也就是移位出了问题
这个时候,我还没意识到是我对指令的理解出了问题,遂看了cpu132_gettrace的源码:
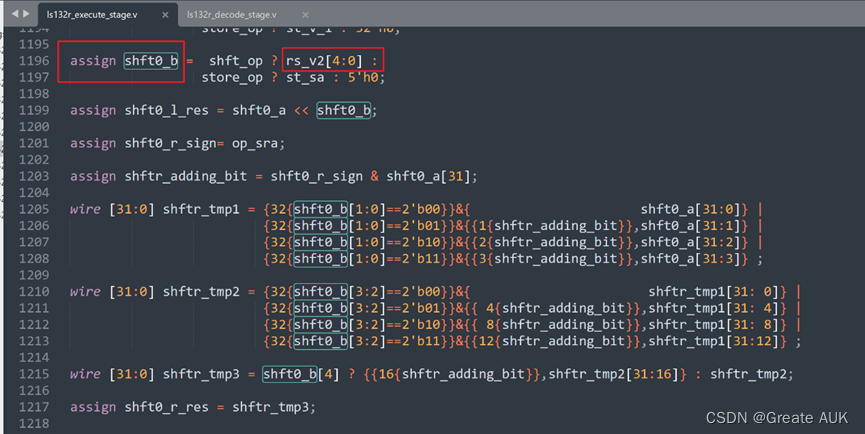
发现shft0_b的值是0x13,并且shft_op的值为1,然后取的是rs_v2的低5位,看到这了,我意识到对指令的理解有问题,遂取看指令:

查看srav指令知道,移位只取rs的低5位,好吧,我看得急,因为寄存器也是5位的,估计当时是直接当成寄存器编号了。(但是出错之后我也是第一时间看这个文档啊,怎么没有发现,直到看了源码才发现呢???先入为主害人啊。)
-
同理srav、srlv、sllv均理解出错,已在修正,更改如下:
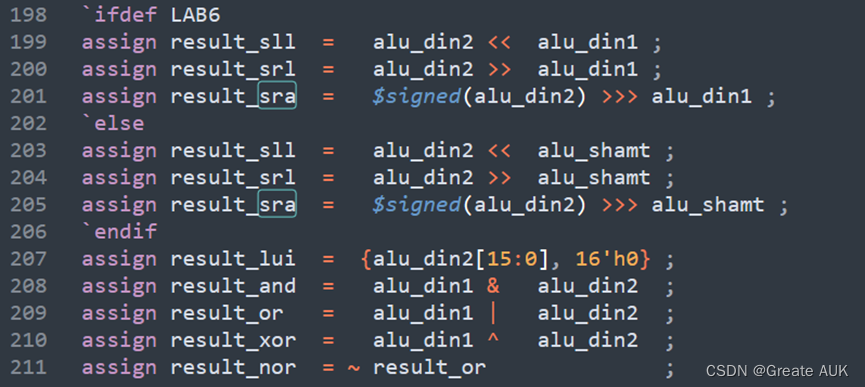
改为:
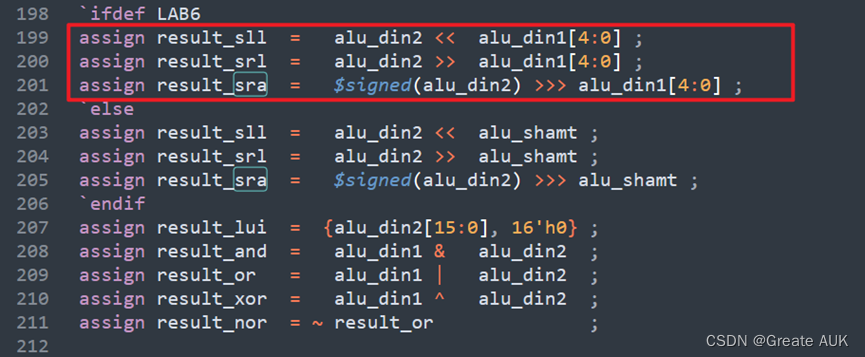
-
bgez报错
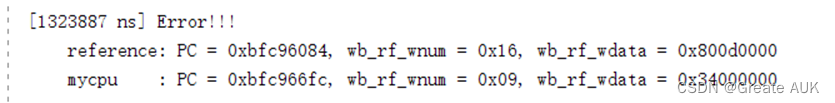
这个错误是因为前面的bgez错误导致跳转出错的,具体原因为:本人将32’h0和32’h8000_0000都当作0,故写成如下代码:
assign rs_eq_zero = id_rs_data[30:0] == 31’h0 ;
现已更改为:
assign rs_eq_zero = id_rs_data[31:0] == 32’h0 ;
lb错
忘了将lb指令添加至id_ins_I中了
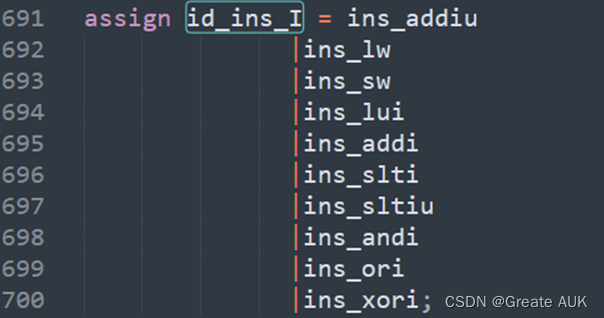
修改成:
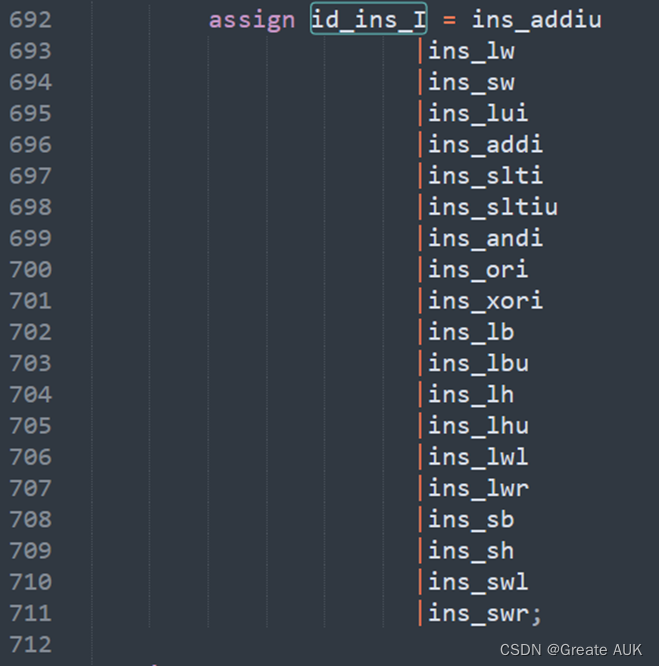
lw报错

14.3节中,进行了exe_data<0的清零操作,但是没有将mem_data进行清零操作,当进行连续lw操作时,会报错,因为mem_data会维持上一周期的数据,这会使旁路造成误判:
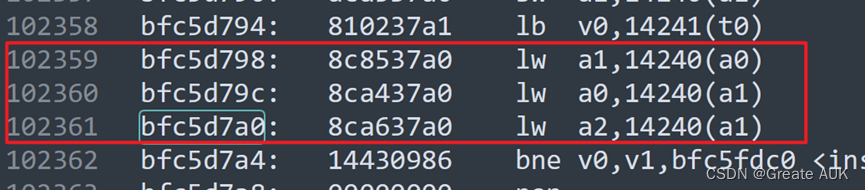
在执行到上面三条指令时,第1条是写寄存器a1,而第2、3条均需要读寄存器a1,如果不对mem_data进行清零,会使得在执行第3条指令的ID阶段时,误判为MEMID旁路,而实际上应该是WBID旁路。故需要对mem_data进行数据类似14.3节中的清零。经分析wb_data不需要清零,因为wb阶段是最后一阶段,不清零无影响。
这里的lw报错是流水线阻塞的问题,应当在Lab4阶段就查出来的,然而没有查出来,本人遂修改了Lab4、Lab6、Lab7的代码:
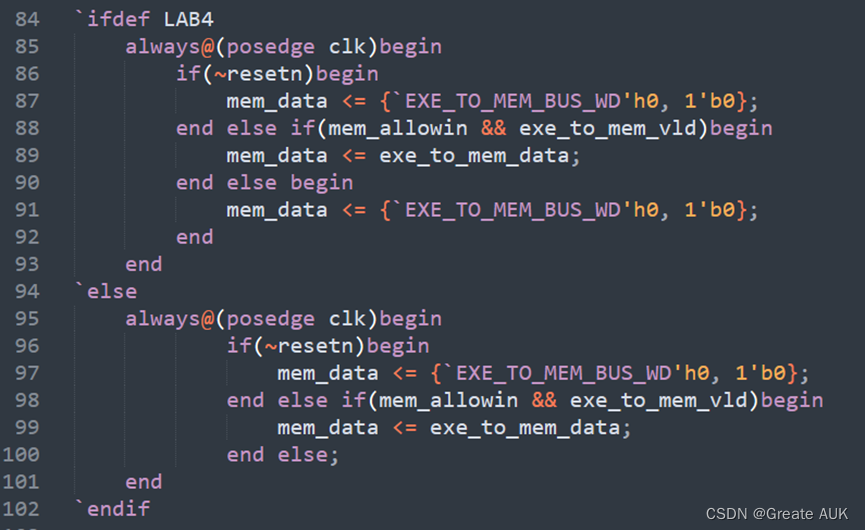
还是考虑的不周全!
lb报错

这个是遗漏的问题,直接拷贝的sw的mem的写使能,忘记更改了:实际上,lwx指令是全部写入寄存器的
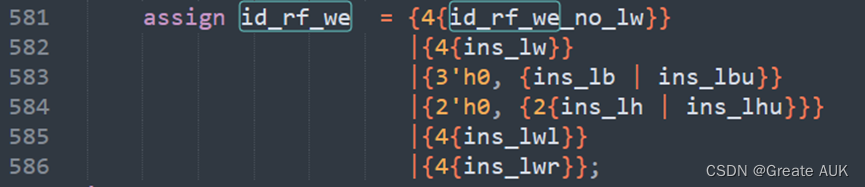
改为:
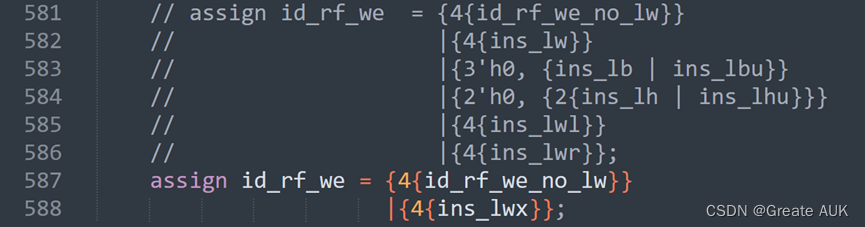
因为除了lwl、lwr,剩下的lwx指令全都是4’b1111,而lwl、lwr指令又会在EXE阶段更新rf_we:

因此,在ID阶段,直接:
assign id_rf_we = {4{ins_lwx}}
即可。
lh报错:

原因是在MEM.v中,对数据的控制出错,因此为lh的控制应当是mem_raddr_low2的第1-bit,而不是第0-bit

改为:

同理,我想到EXE.v中的sh_we有同样的问题:

改为:

lwr报错
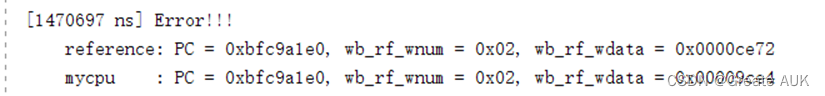
修改如下:一个是位选择写错了:31:15 改为 31:16
另一个也是位选择错了:23:0 改为 31:8
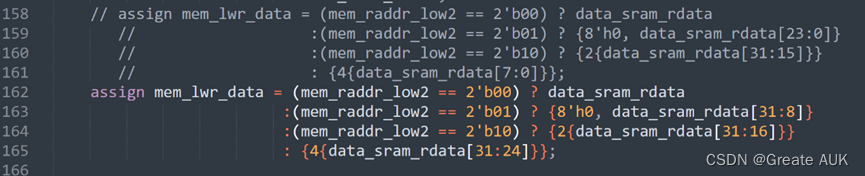
然后还发现一处错误,扩展应该是32,而不是4:


改为:
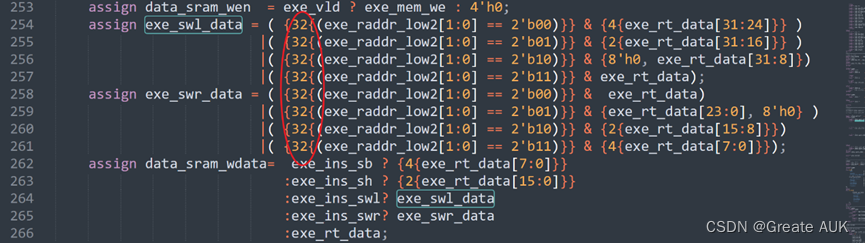
然而还发现一个错误:
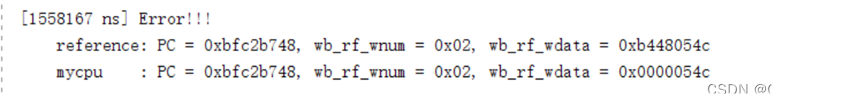
这里应该是15:0,而不是15:8。想捶自己。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











