







 公司kettle上30个业务并发执行时突发OOM事故。经排查,是94号Linux机器残留进程过多,凌晨4点线程并发峰值内存不足所致。文章给出四种解决方案,包括增加随机时间等待、拆分并行任务、引入监控框架和迁移部分项目到其他服务器。
公司kettle上30个业务并发执行时突发OOM事故。经排查,是94号Linux机器残留进程过多,凌晨4点线程并发峰值内存不足所致。文章给出四种解决方案,包括增加随机时间等待、拆分并行任务、引入监控框架和迁移部分项目到其他服务器。
目录
(1)在kettle中对并行执行的任务增加一个随机时间等待,如下
场景:
公司kettle上有30个子业务,每个业务对应一个项目id(projId),在kettle中设置30个业务并发执行,平时机器都运行健康,本次是突发OOM事故。
本次Linux OOM的出现标志是:
(1)94号Linux机器上,凌晨4点多出现大量的hs_err_pidXXXXX.log文件
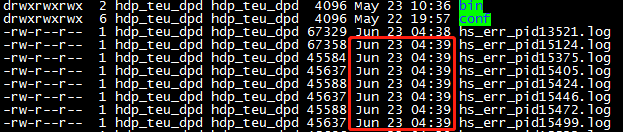
(2)收到公司平台报警邮件
查看hs_err_pidXXXXX.log文件,发现是OOM
排查:
一、
首先通过free和top命令查看机器内存情况,
发现机器内存只用了18%左右,判断不是机器总内存不够
二、查看报错日志
一般OOM的原因分两种:内存不足和线程数过多
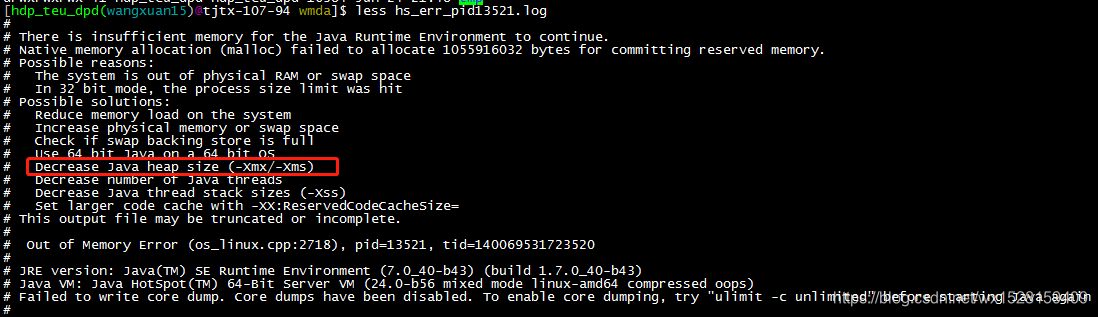
查看运行任务的运行日志,发现一切正常,只是发生了OOM
初步判断一种优化方案就是调低-Xmx的参数,降低堆内存,增大线程内存
参考文章:
强推!5种常见OOM现象原因
三、最终排查原因
最终排查原因为,94号Linux机器的残留进程过多导致凌晨4点多线程并发峰值内存不足引起OOM,
机器上定时跑的任务都是以进程的方式执行的,天级别的任务设定在每天凌晨4点跑,同时凌晨4点还会跑小时级别的任务,都是并行任务;可能的一种情况是,任务跑成功了,但是有些进程还是会残留下来,占用cpu和内存。
四、解决方案考虑有四种
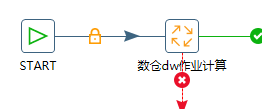
(1)在kettle中对并行执行的任务增加一个随机时间等待,如下
原始kettle
优化后的kettle
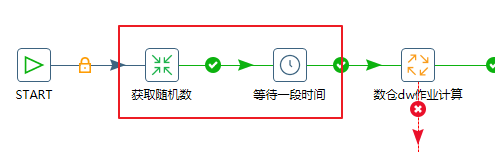
这样的结果是,30个任务并行执行的时候,每个任务的启动时间节点不一致,造成错峰处理,
但是劣势是如果等待的随机时间设定的比较短,那么只能造成每个任务启动时间不一致,并不能保证峰值运行线程数降低。
(2)30个并行任务分3次跑
也就是把并行度进行拆分,
原来一次并行跑30个项目任务,改成一次并行跑10个项目任务,分三次跑
因为跑的是前一天的离线任务,所以对于时间要求不高,这样峰值并行度显著降低,但总并行度任务量并不变。
(3)考虑引入zabbix和zaa监控框架
增加一个这样的监控框架,可以明显看出机器在什么时间点内存不足,并且能够看出是哪些线程占据大量cpu,对于以后解决这种OOM问题有很大的好处。
同时也可以写一个脚本,每隔10min运行一次,抓取当前top5的线程情况,加上系统时间,写出到一个日志log里面;
这样可以通过OOM的报错文件时间点,来定位log里面那个时间节点的cpu占用率top5的线程是哪些,来定位问题;
可以作为一个补充措施,最好的还是加个监控框架。
(4)将部分项目迁移到别的服务器
由于任务数过多导致服务器OOM,也可以考虑将部分项目的任务迁移到别的服务器,最简单省事

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









