







 博客介绍了从Huggingface官网下载预训练模型的方法。访问官网搜索所需模型,点击Files and versions查看文件,只需下载部分,关键文件有配置文件、词典文件和预训练模型文件,还以google - bert/bert - base - chinese为例说明,同时提及了使用时指定模型名字和路径。
博客介绍了从Huggingface官网下载预训练模型的方法。访问官网搜索所需模型,点击Files and versions查看文件,只需下载部分,关键文件有配置文件、词典文件和预训练模型文件,还以google - bert/bert - base - chinese为例说明,同时提及了使用时指定模型名字和路径。
- 访问huggingface官网,搜索需要下载的预训练模型
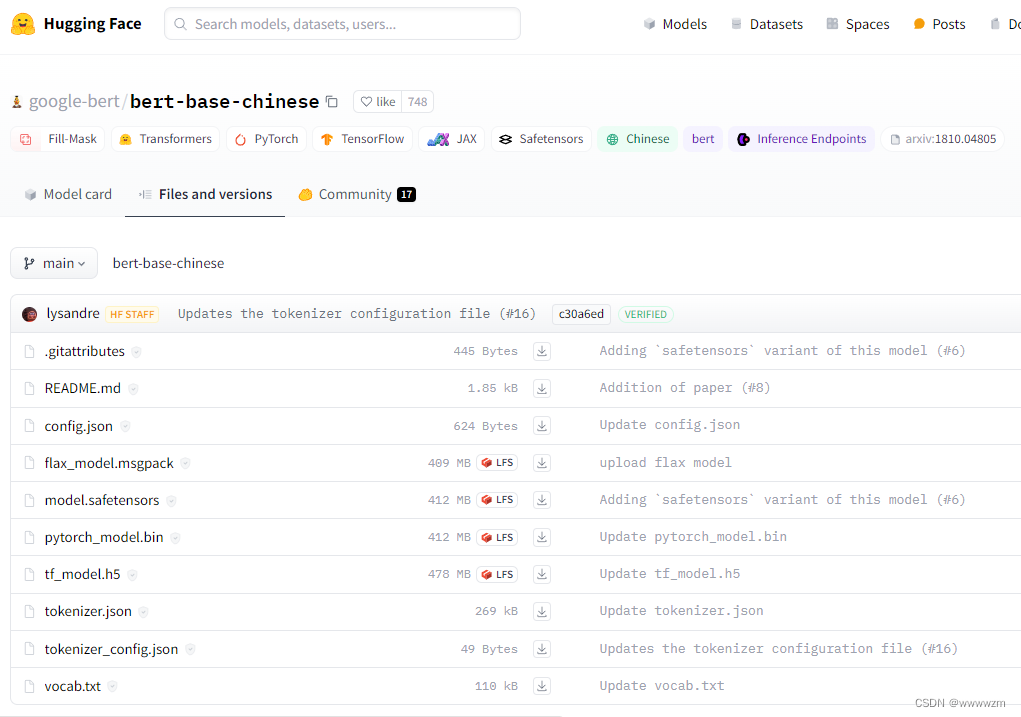
- 点击Files and versions,查看模型包含的文件,只需要下载部分文件即可。最关键的是三个文件:
- 第一个是配置文件,config.json
- 第二个是词典文件,vocab.json或vocab.txt
- 第三个是预训练模型文件,pytorch_model.bin或tf_model.h5。(根据使用的框架选择)
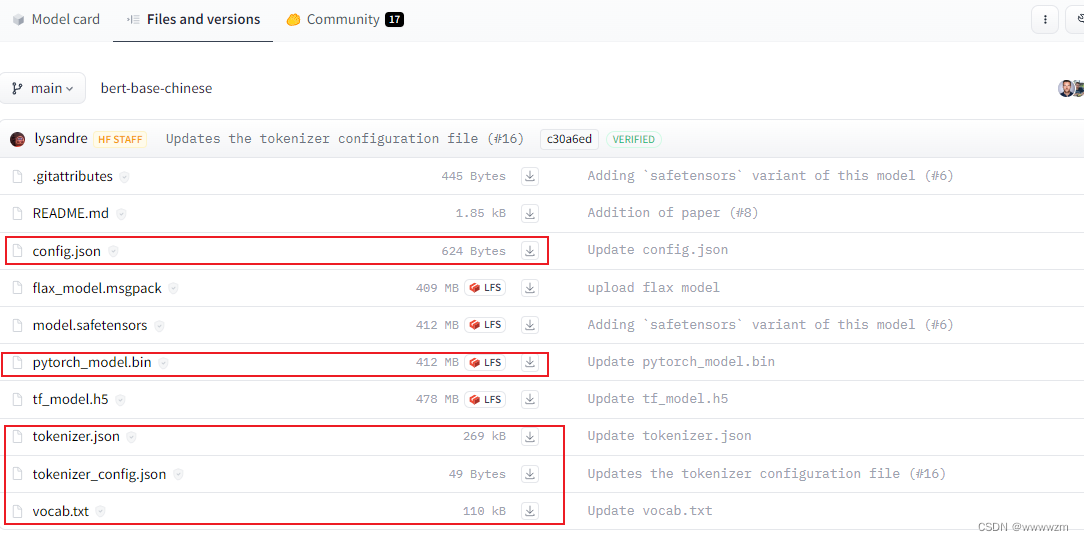
- 以google-bert/bert-base-chinese为例,红色框是必须下载的
- 使用方式
- 指定模型名字
from transformers import AutoTokenizer, AutoModel
tokenizer =</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









