







 本文介绍了一种新的图像分割框架FCBFormer,它通过双分支设计——全卷积分支(FCB)和Transformer分支(TB),优化了结肠镜图像中的息肉检测和分类。TB利用PVTv2和PLD增强局部特征,而FCB则保持全尺寸分辨率。实验结果显示了显著的性能提升。
本文介绍了一种新的图像分割框架FCBFormer,它通过双分支设计——全卷积分支(FCB)和Transformer分支(TB),优化了结肠镜图像中的息肉检测和分类。TB利用PVTv2和PLD增强局部特征,而FCB则保持全尺寸分辨率。实验结果显示了显著的性能提升。
本文提出了一种名为Fully Convolutional Branch-TransFormer (FCBFormer)的图像分割框架。该架构旨在结合Transformer和全卷积网络(FCN)的优势,以提高结肠镜图像中息肉的检测和分类准确性。
1,框架结构:
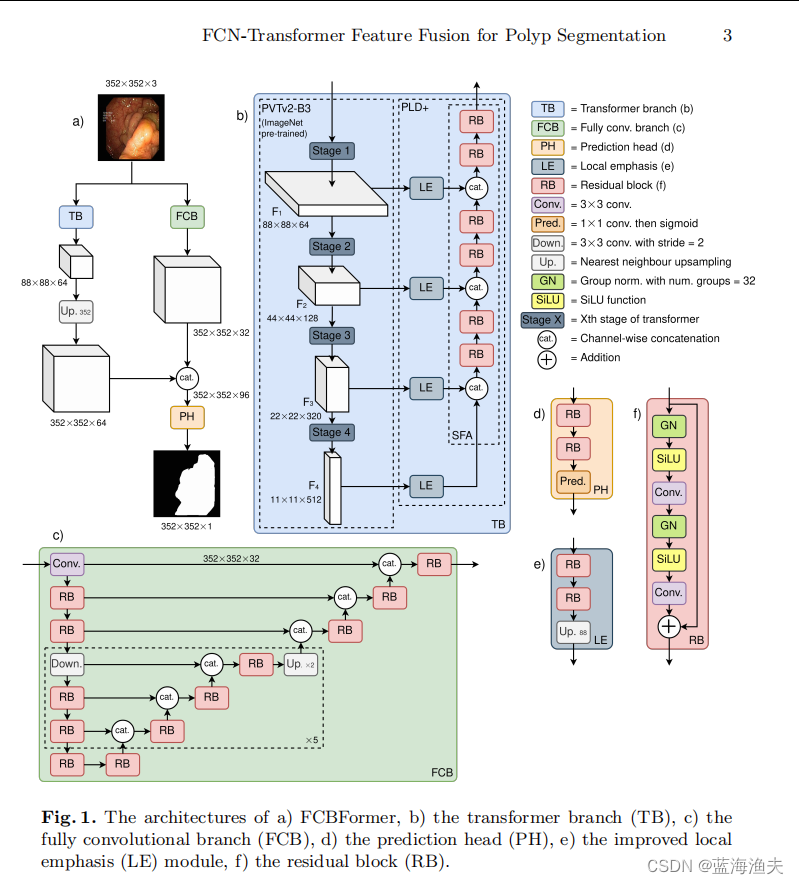
模型采用双分支结构,两个并行分支:一个全卷积分支(FCB)和一个Transformer分支(TB)。FCB返回全尺寸(h×w)特征图,而TB返回降尺寸(h/4 × w/4)的特征图。TB的输出张量经过上采样并与FCB的输出张量在通道维度上进行拼接,然后通过预测头(PH)处理,生成输入图像的全尺寸分割图。
2,TB分支的结构
TB使用ImageNet预训练的金字塔视觉Transformer V2(PVTv2)作为图像编码器,该编码器返回一个具有4个级别的特征金字塔,这个金字塔随后被用作渐进式局部解码器(PLD)的输入。
在PLD中,金字塔的每个级别首先通过一个局部强调(LE)模块进行处理,以解决基于Transformer的模型在特征表示中表示局部特征的不足,然后通过逐步特征聚合(SFA)融合经过局部强调的金字塔特征。最后,融合的多尺度特征用于预测输入图像的分割图。
3,LE模块的结构
LE模块,即局部强调(Local Emphasis)模块,是SSFormer架构中用于增强Transformer编码器提取的特征的局部特征表示的组件。在FCBFormer的TB(Transformer Branch)中,LE模块的目的是通过强调图像的局部区域来改善Transformer模型在处理细节时的性能。
LE模块的具体由卷积层、激活函数、残差连接、组归一化、通道数调整等部分组成。
LE模块的设计旨在通过突出局部特征来弥补Transformer在处理精细细节时的不足,从而在分割任务中提供更准确的局部边界信息。
4,FCB分支的结构
如上图C所示,是由残差模块组成的U型结构。
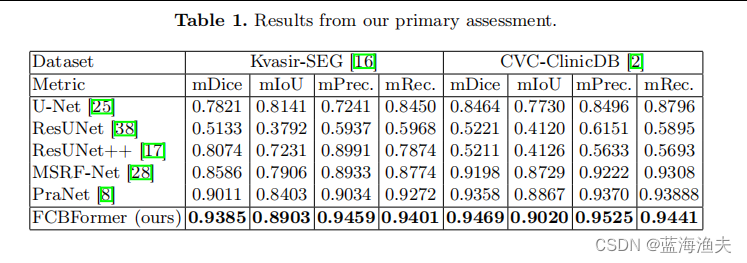
5,实验结果



















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











