







8-langChian开发agent智能体
创建和运行 Agent
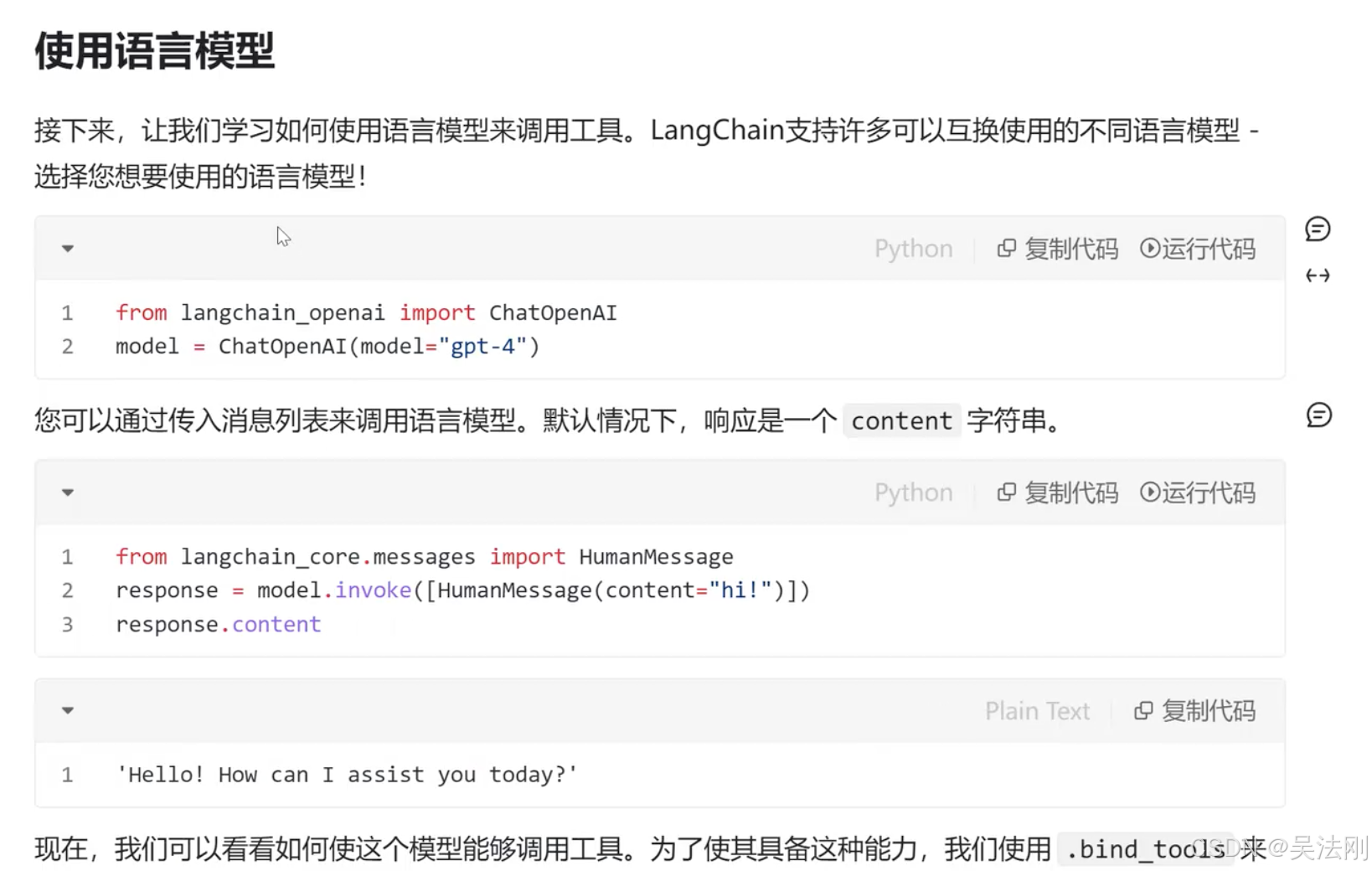
单独来说,语言模型无法采取行动 - 它们只能输出文本。
LangChain 的一个重要用例是创建代理。
代理是使用 LLM 作为推理引擎的系统,用于确定应采取哪些行动以及这些行动的输入应该是什么。
然后可以将这些行动的结果反馈给代理,并确定是否需要更多行动,或者是可以结束。
在本次课程中,我们将构建一个可以与多种不同工具进行交互的代理:一个是本地数据库,另一个是搜索引擎。您将能够向该代理提问,观察它调用工具,并与它进行对话。
下面将介绍使用 LangChain 代理进行构建。LangChain 代理适合入门,但在一定程度之后,我们可能希望拥有它们无法提供的灵活性和控制性。要使用更高级的代理,我们建议查看 LangGraph。
概念
我们将涵盖的概念包括:
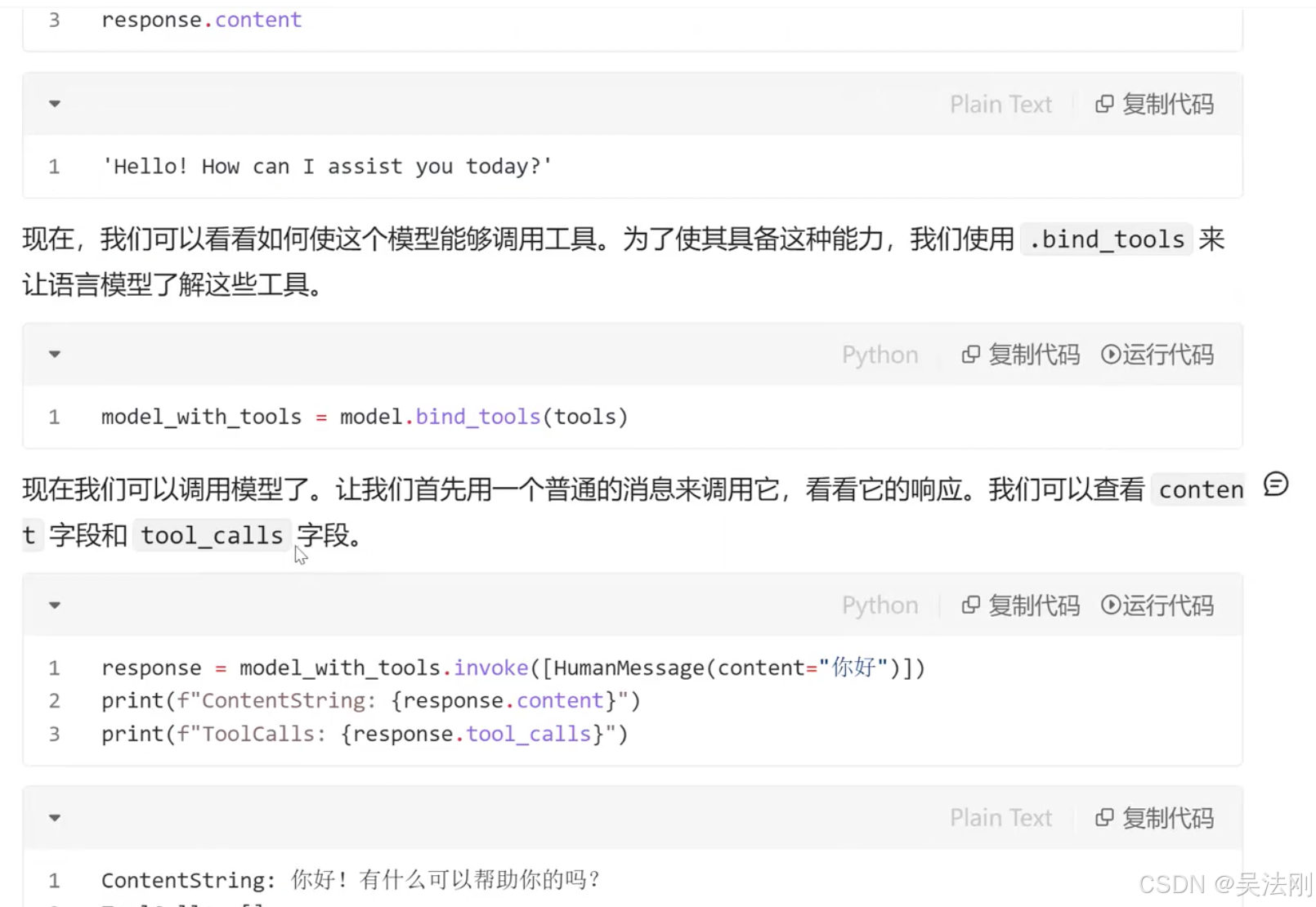
- 使用语言模型,特别是它们的工具调用能力
- 创建检索器以向我们的代理公开特定信息
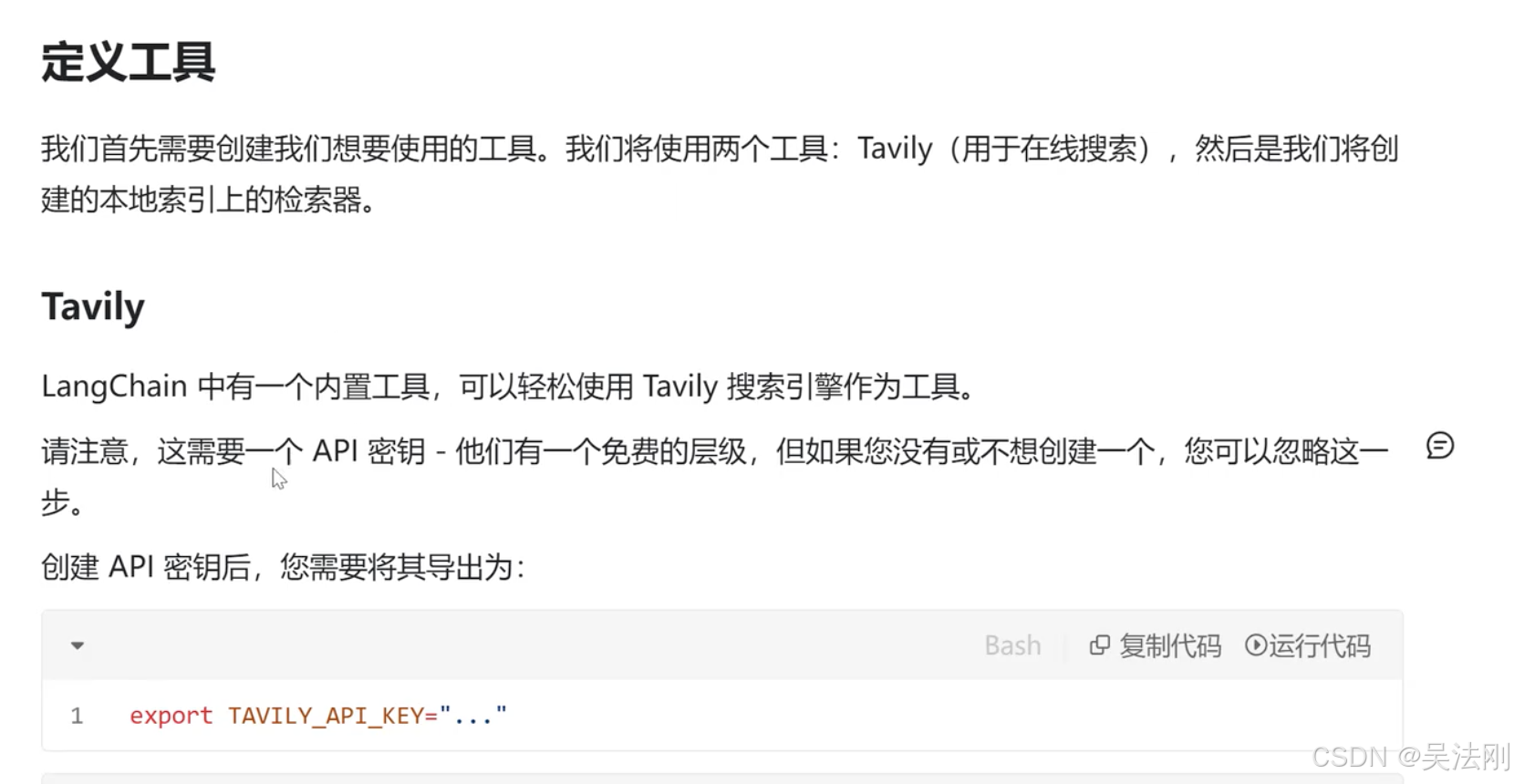
- 使用搜索工具在线查找信息
- 聊天历史,允许聊天机器人“记住”过去的交互,并在回答后续问题时考虑它们。
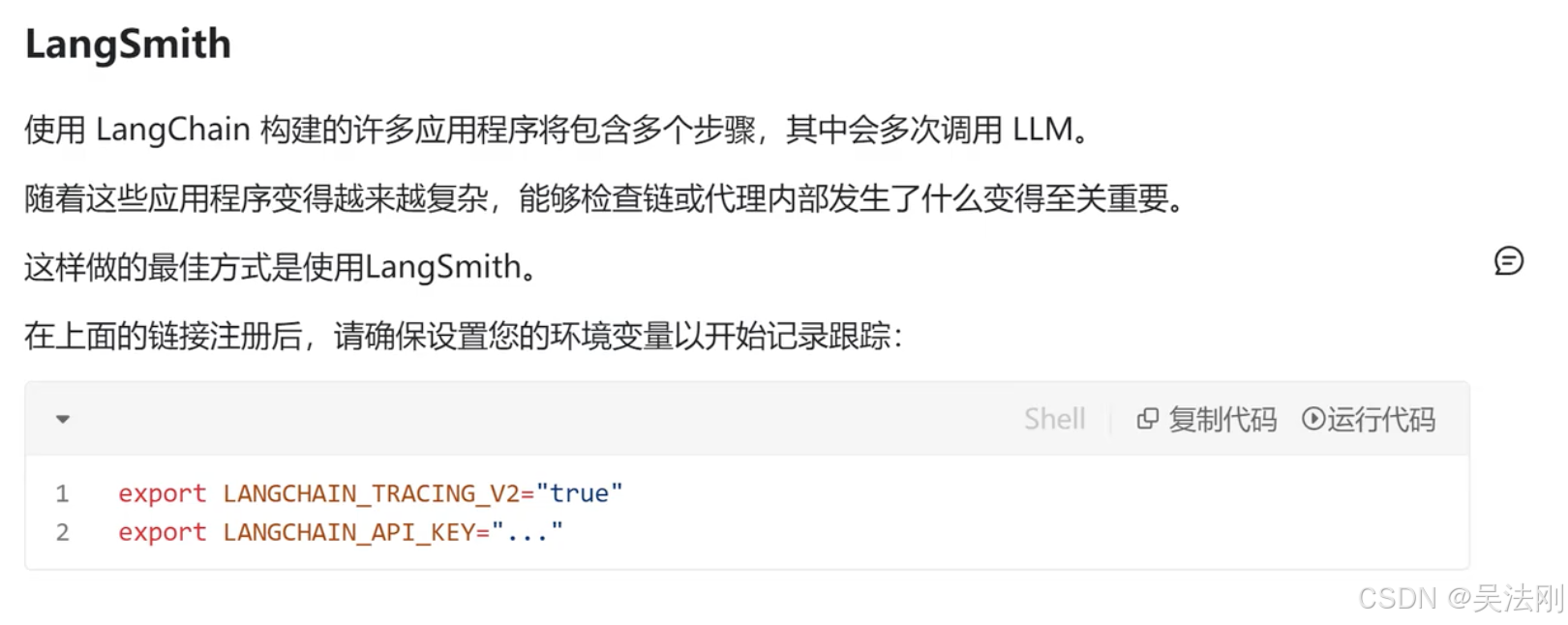
- 使用 LangSmith 调试和跟踪您的应用程序
from tavily import TavilyClient
tavily_client = TavilyClient()
response = tavily_client.search("Who is Leo Messi?")
print(response)

# 导入所需模块
# pip install fastembed
# pip install faiss-cpu
import os
from langchain_core.tools import create_retriever_tool
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
os.environ["TOKENIZERS_PARALLELISM"] = "True"
# 然后继续执行你的代码
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
# 加载文档
loader = TextLoader("../example_data/cat/cat.txt")
documents = loader.load()
# 文本切分
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 嵌入向量表示
# embeddings = OpenAIEmbeddings()
# pip install fastembed
from langchain_community.embeddings import FastEmbedEmbeddings
fastembed = FastEmbedEmbeddings()
vectorstore = FAISS.from_documents(texts, fastembed) # 使用FAISS向量存储
retriever = vectorstore.as_retriever()
print(retriever.invoke("猫的特征")[0])
retriever_tool = create_retriever_tool(retriever, "serach_badu_baike", "百度百科")
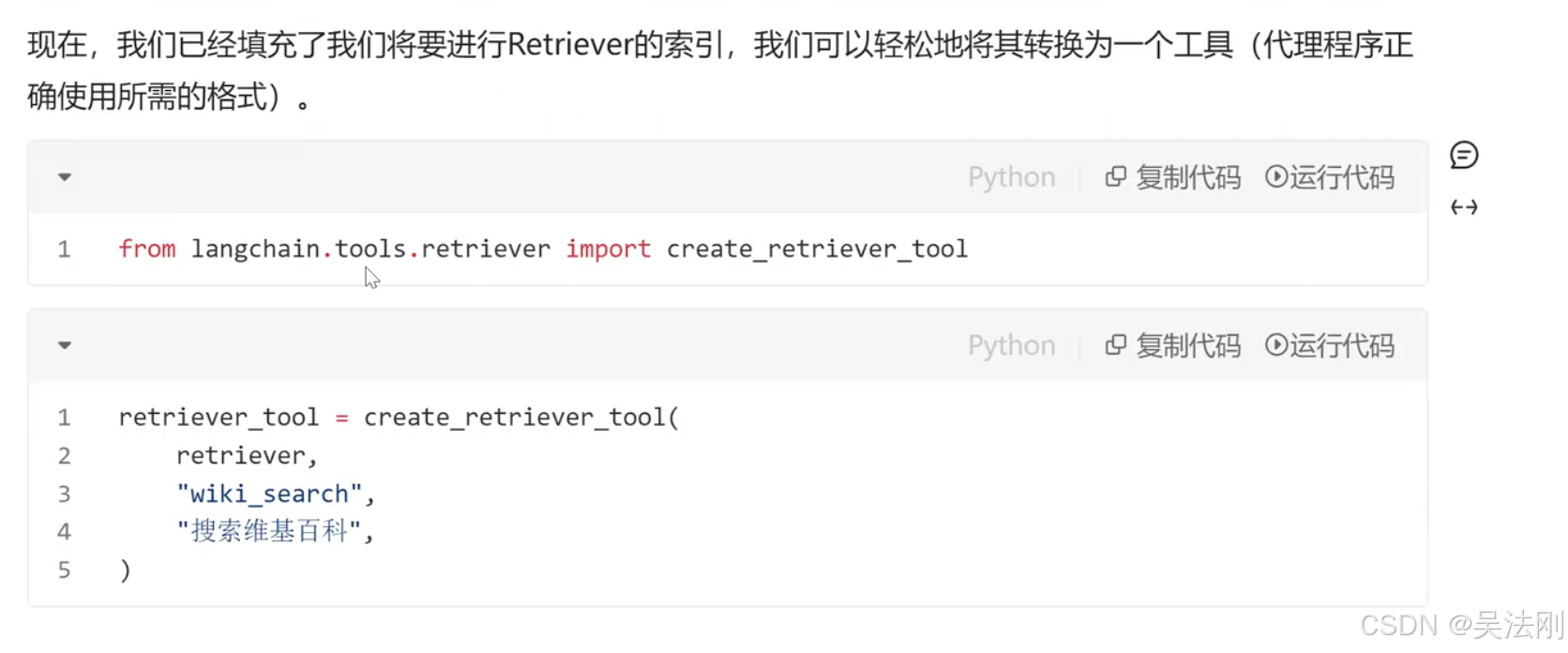
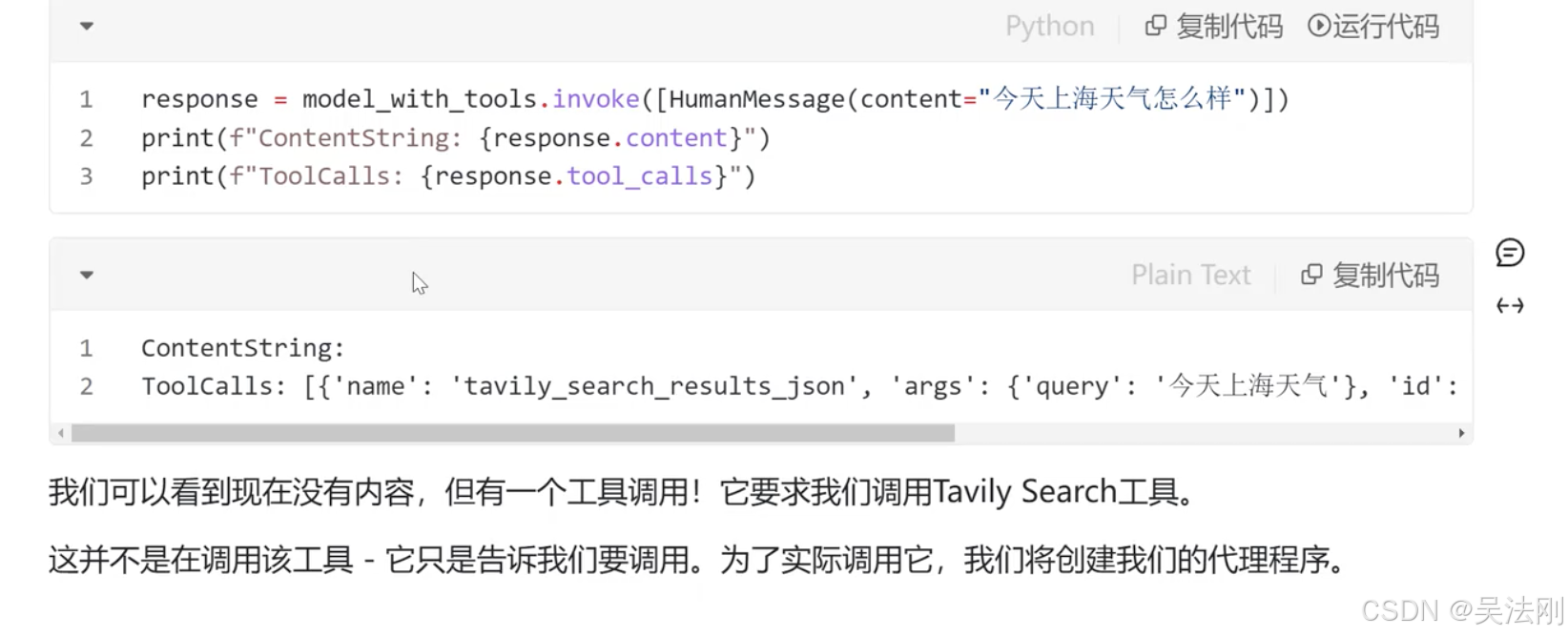
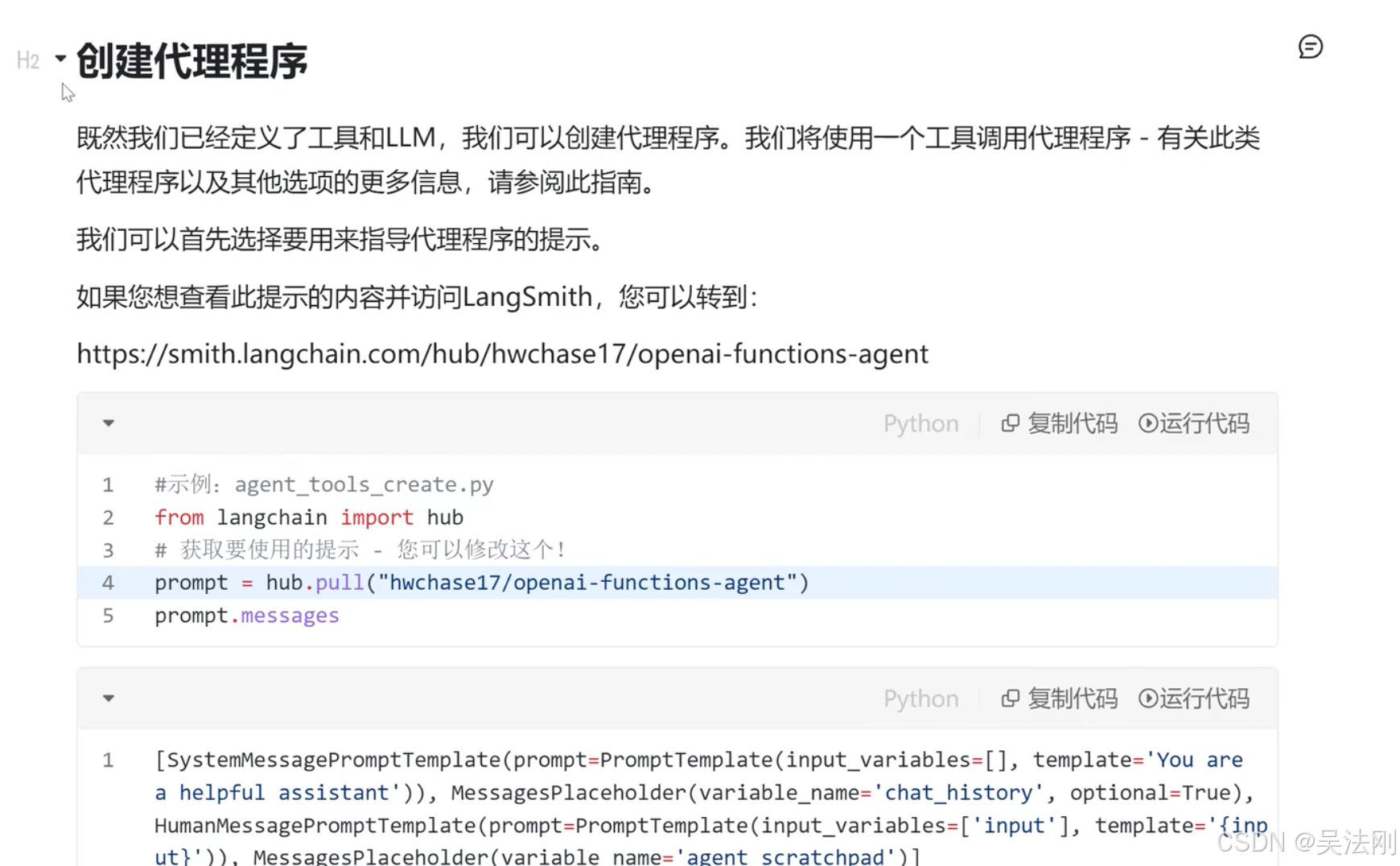
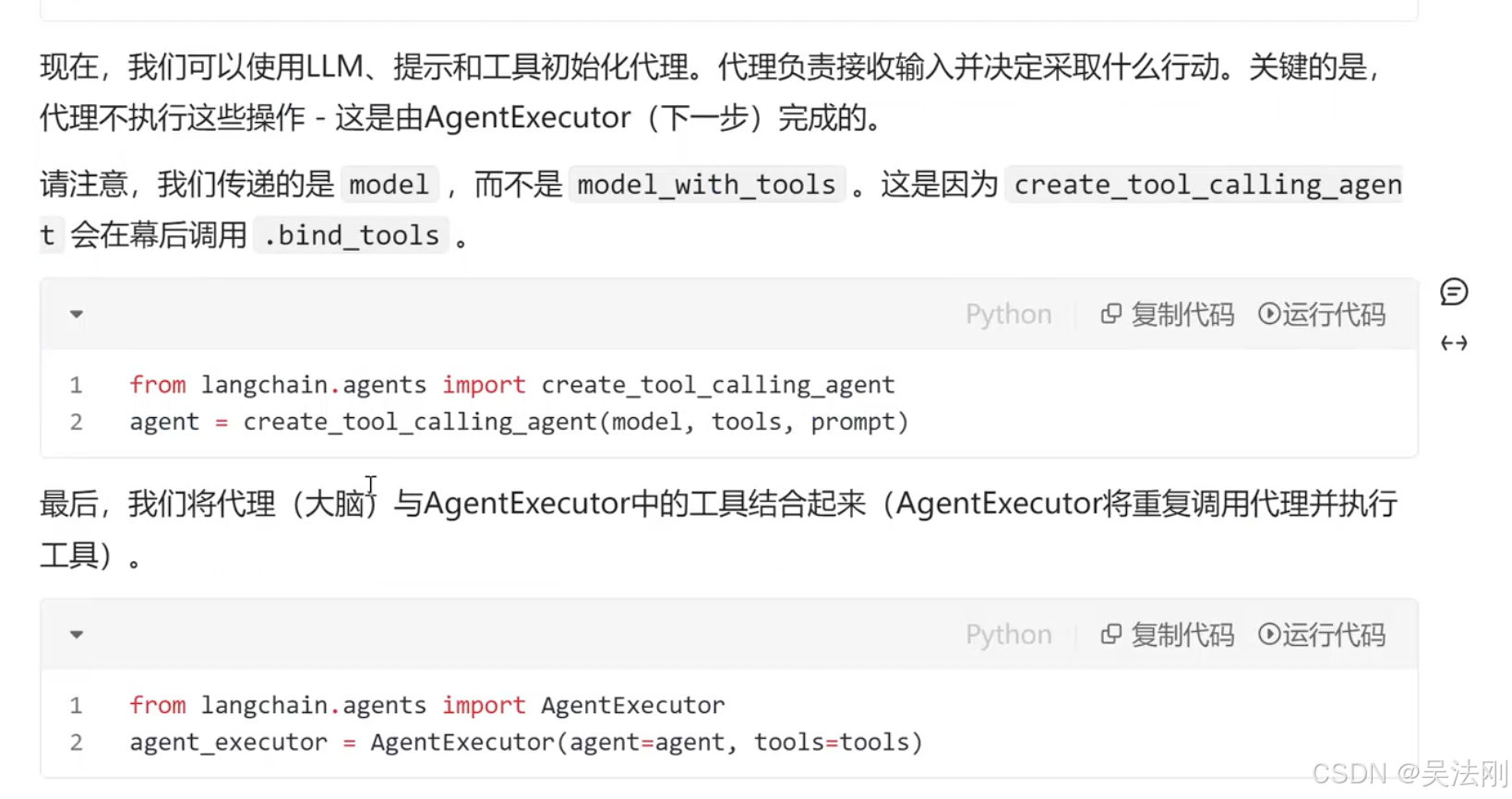
创建代理程序
# 导入所需模块
# pip install fastembed
# pip install faiss-cpu
import os
from langchain_community.tools import TavilySearchResults
from langchain_core.tools import create_retriever_tool
from langchain_openai import ChatOpenAI
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
os.environ["TOKENIZERS_PARALLELISM"] = "True"
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.embeddings import FastEmbedEmbeddings
# 加载文档
loader = TextLoader("../example_data/cat/cat.txt")
documents = loader.load()
# 文本切分
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
fastembed = FastEmbedEmbeddings()
vectorstore = FAISS.from_documents(texts, fastembed) # 使用FAISS向量存储
retriever = vectorstore.as_retriever()
print(retriever.invoke("猫的特征")[0])
retriever_tool = create_retriever_tool(retriever, "serach_badu_baike", "百度百科")
llm = ChatOpenAI(
model='qwen-plus',
openai_api_base='https://dashscope.aliyuncs.com/compatible-mode/v1',
max_tokens=1024
)
search = TavilySearchResults(max_result =1)
tools = [search, retriever_tool]
from langchain import hub
prompt = hub.pull("hwchase17/openai-functions-agent")
print(prompt.messages)
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools)
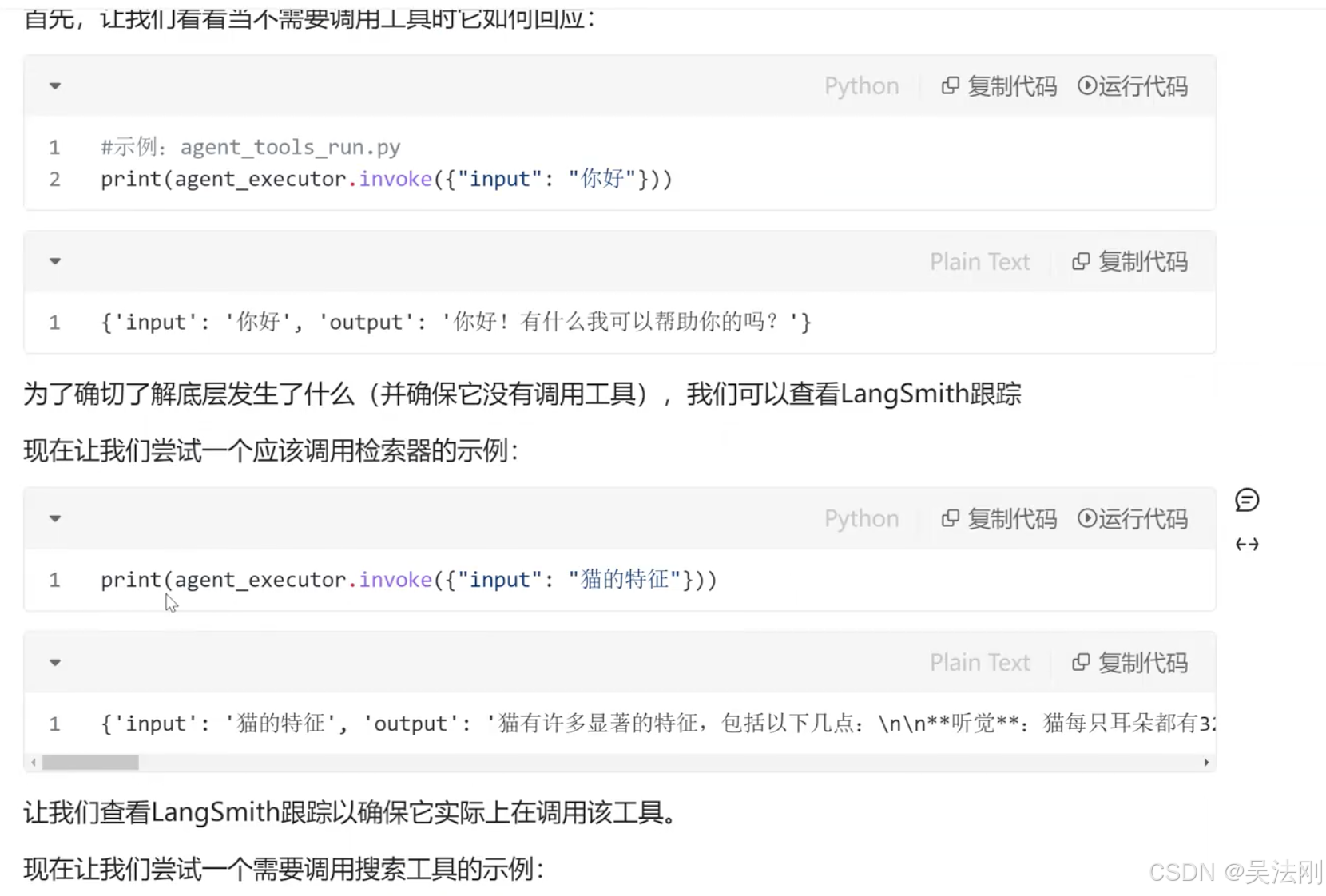
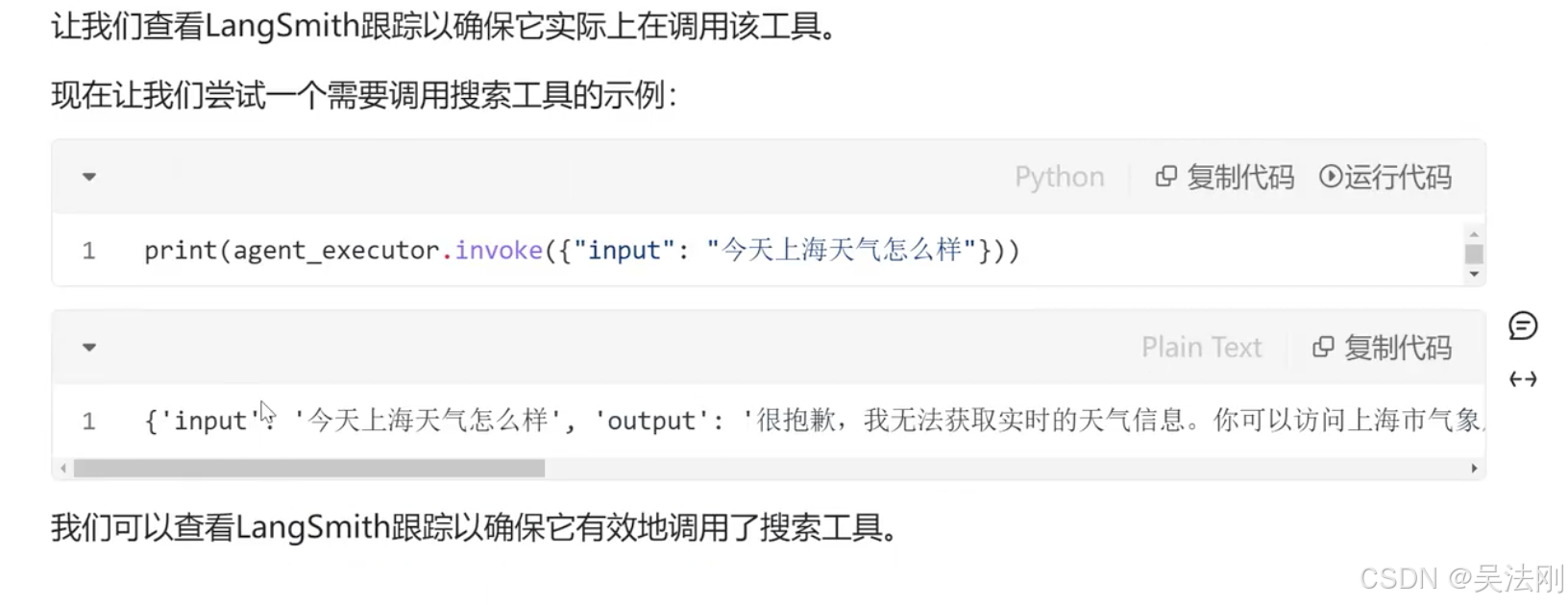
print(agent_executor.invoke({"input":"猫的特征,北京的天气"}))
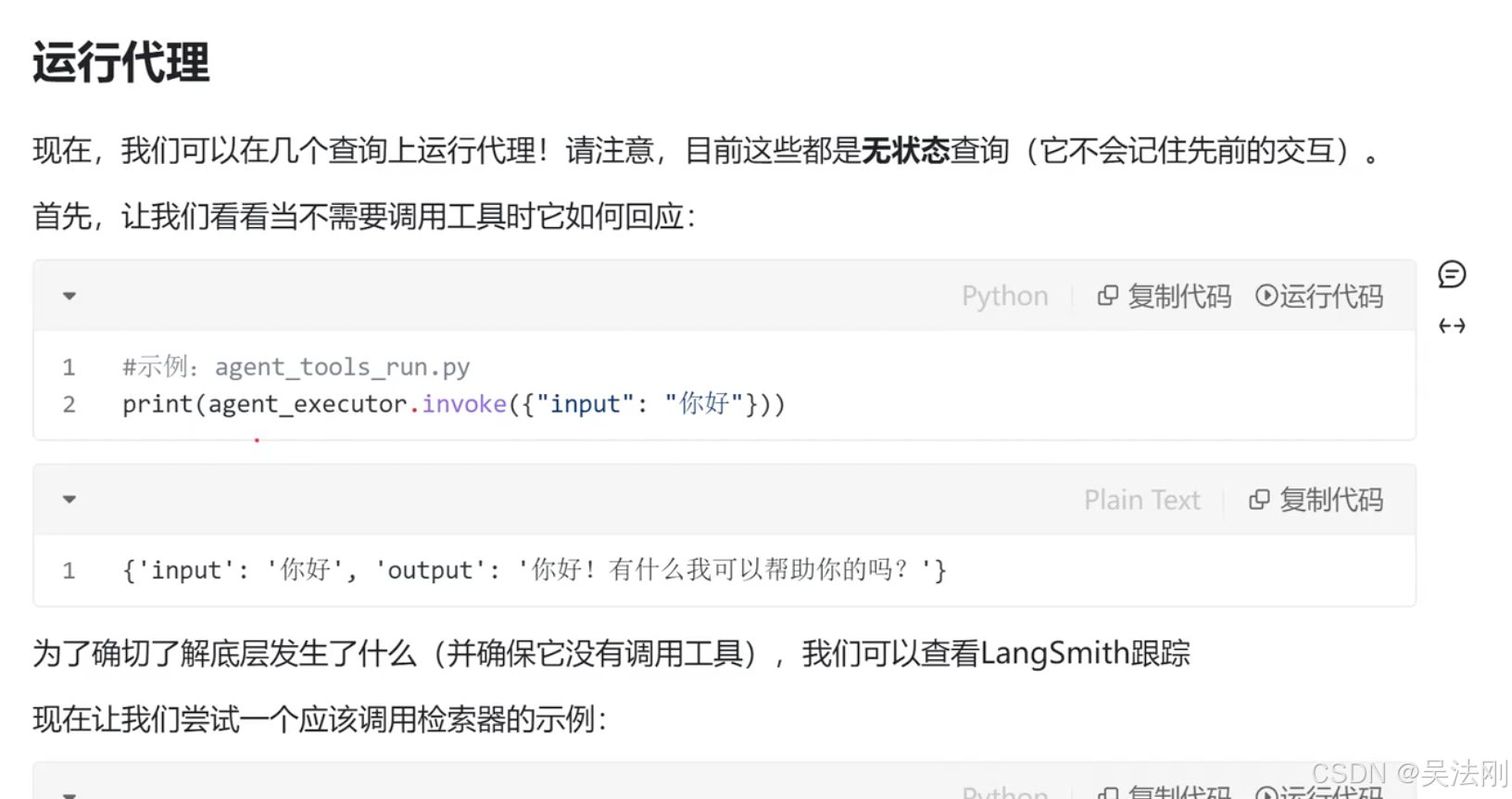
{'input': '猫的特征,北京的天气', 'output': '猫的特征如下:\n\n猫有276种不同的面部表情,这些表情可能是在其与人类相处的过程中逐步进化出来的。它们共有26种独特面部动作,如瞳孔放大或收缩、舔鼻子、延长或缩回胡须、不同的耳朵位置等。\n\n猫体型小,体色由蓝灰色到棕黄色不等,身长一般在0.3-0.5米之间。全身毛被密而柔软,锁骨小,吻部短,眼睛圆,颈部粗壮,四肢较短,足下有数个球形肉垫;舌面被有角质层的丝状钩形乳突。雄性头部较为粗圆,个体较大。猫有多种毛色,身形像狸,外貌像老虎,毛柔而齿利(有几乎无毛的品种)。以尾长腰短,目光如金银,上腭棱多的为佳。猫的身体分为头、颈、躯干、四肢和尾五部分,大多数部位披毛,少数为无毛猫。猫的趾底有脂肪质肉垫,因而行走无声,捕鼠时不会惊跑鼠,趾端生有锐利的趾甲。爪能够缩进和伸出。猫在休息和行走时爪缩进去,只在捕鼠和攀爬时伸出来,防止趾甲被磨钝。猫的前肢有五趾,后肢有四趾。猫的牙齿分为门齿、犬齿和臼齿。犬齿特别发达,尖锐如锥,适于咬死捕到的鼠类,臼齿的咀嚼面有尖锐的突起,适于把肉嚼碎;门齿不发达。\n\n北京的天气预报如下:\n\n根据多个来源的数据汇总,近期北京的天气预计会有晴天和多云的情况,气温有所波动。白天最高温度在1℃至14℃之间,夜间最低温度在-10℃至-4℃之间。风向主要为微风,西南风和北风交替出现,风力等级通常小于3级。具体温度和天气情况可能会有所不同,请参考最新的天气预报进行出行计划。'}
添加记忆
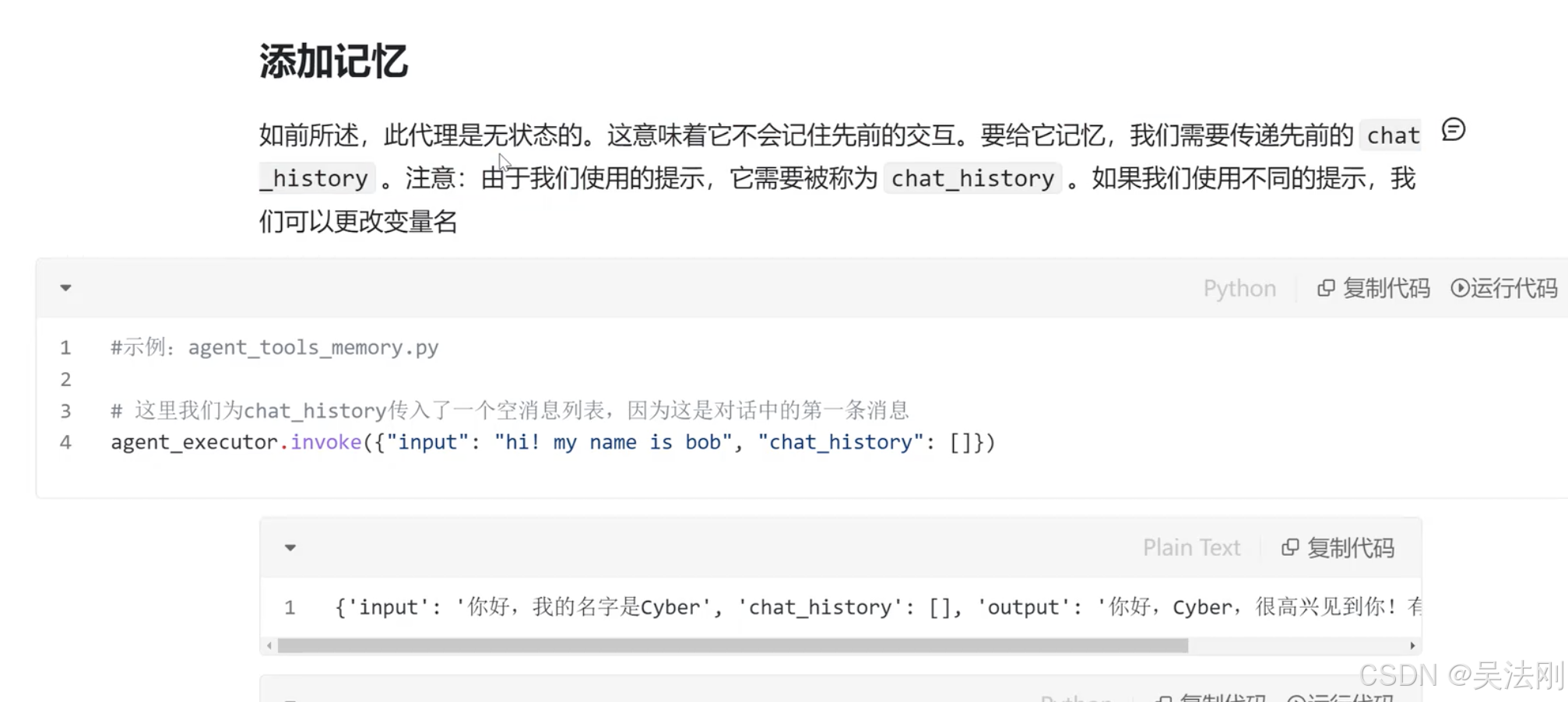
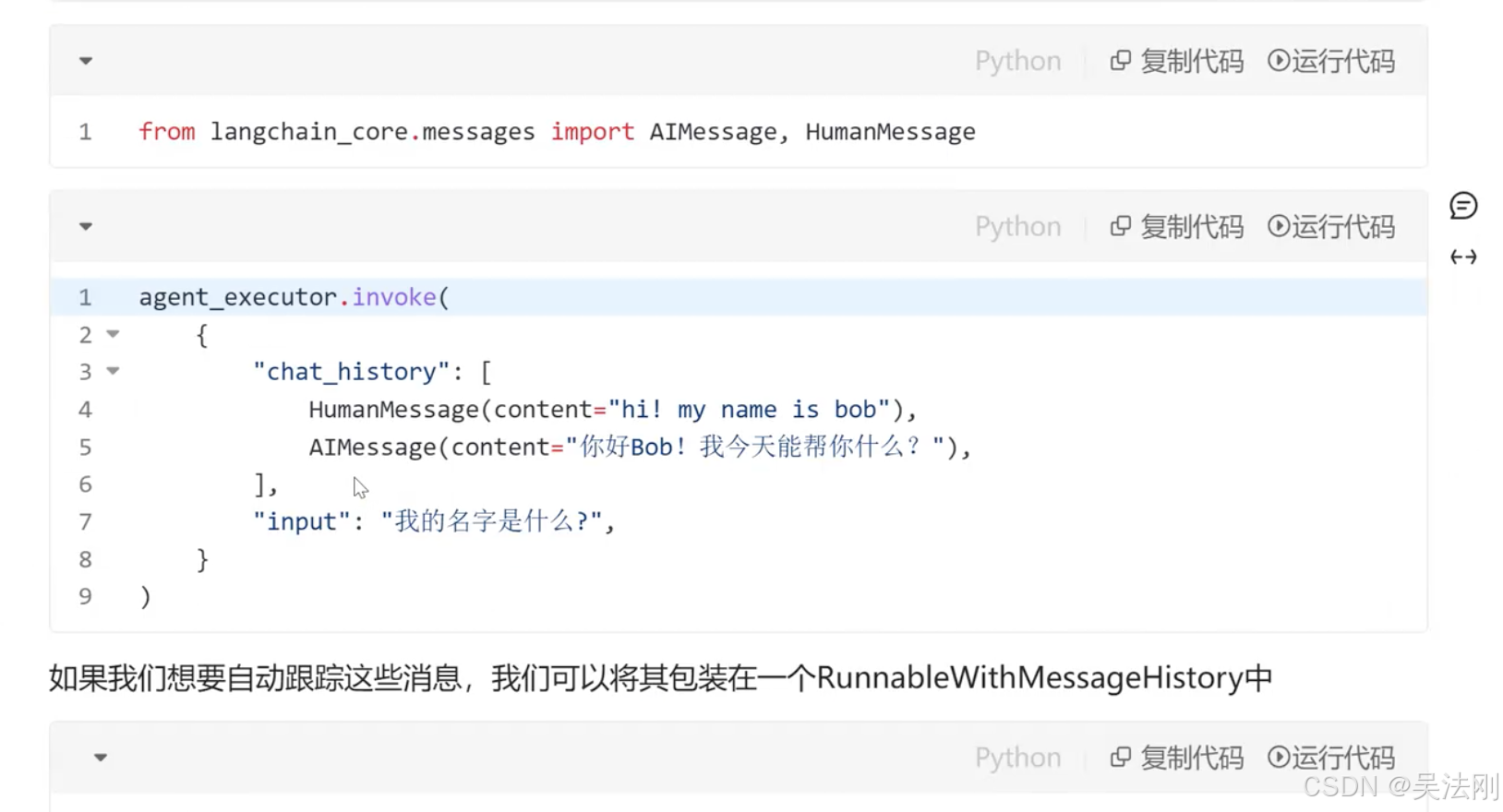
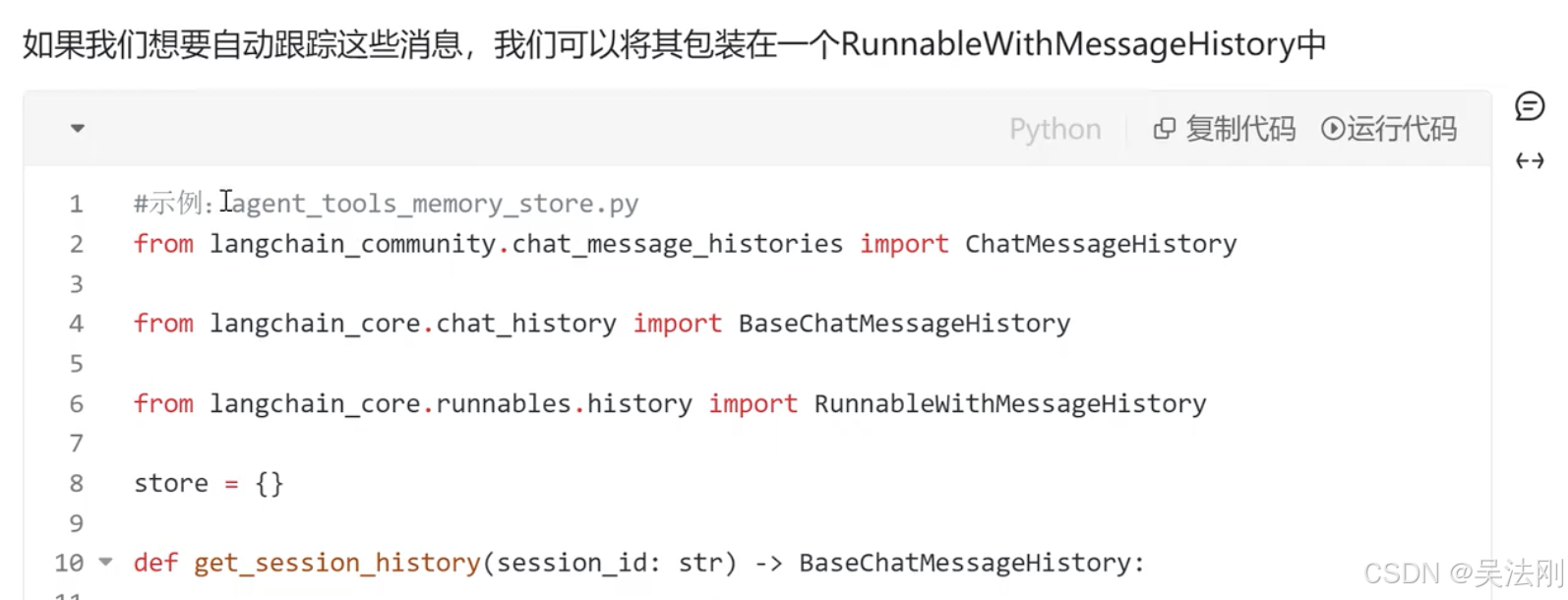

# 导入所需模块
# pip install fastembed
# pip install faiss-cpu
import os
from langchain_community.tools import TavilySearchResults
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.tools import create_retriever_tool
from langchain_openai import ChatOpenAI
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
os.environ["TOKENIZERS_PARALLELISM"] = "True"
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.embeddings import FastEmbedEmbeddings
# 加载文档
loader = TextLoader("../example_data/cat/cat.txt")
documents = loader.load()
# 文本切分
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
fastembed = FastEmbedEmbeddings()
vectorstore = FAISS.from_documents(texts, fastembed) # 使用FAISS向量存储
retriever = vectorstore.as_retriever()
print(retriever.invoke("猫的特征")[0])
retriever_tool = create_retriever_tool(retriever, "serach_badu_baike", "百度百科")
llm = ChatOpenAI(
model='qwen-plus',
openai_api_base='https://dashscope.aliyuncs.com/compatible-mode/v1',
max_tokens=1024
)
search = TavilySearchResults(max_result =1)
tools = [search, retriever_tool]
from langchain import hub
prompt = hub.pull("hwchase17/openai-functions-agent")
print(prompt.messages)
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools)
store = {}
from langchain_community.chat_message_histories import ChatMessageHistory
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if(session_id not in store):
store[session_id] = ChatMessageHistory()
return store[session_id]
agent_with_chat_history = RunnableWithMessageHistory(agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history")
response = agent_with_chat_history.invoke({"input":"his 我的名字是Jack"},
config={"configurable":{"session_id":"123"}})
print(response)
response = agent_with_chat_history.invoke({"input":"his 我的名字叫什么"},
config={"configurable":{"session_id":"123"}})
print(response)
response = agent_with_chat_history.invoke({"input":"his 我的名字叫什么"},
config={"configurable":{"session_id":"456"}})
print(response)


















 4973
4973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









