




 本文探讨了卷积神经网络(CNN)在序列建模任务上对比循环神经网络(如LSTM)的优势。研究发现,时间卷积网络(TCN)在多个任务上表现出色,不仅精度更高,而且结构更简洁,有效内存更长。TCN通过因果卷积和扩张卷积实现长序列历史记录,同时具备可变长度输入、较低内存需求和更好的并行化能力。然而,它在评估时需要存储原始序列,且在迁移学习时可能需要调整超参数以适应不同长度的历史记录需求。
本文探讨了卷积神经网络(CNN)在序列建模任务上对比循环神经网络(如LSTM)的优势。研究发现,时间卷积网络(TCN)在多个任务上表现出色,不仅精度更高,而且结构更简洁,有效内存更长。TCN通过因果卷积和扩张卷积实现长序列历史记录,同时具备可变长度输入、较低内存需求和更好的并行化能力。然而,它在评估时需要存储原始序列,且在迁移学习时可能需要调整超参数以适应不同长度的历史记录需求。
论文
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
摘要
最近的一些研究表明卷积神经网络在像语音合成以及机器翻译的任务上超过了循环神经网络。给定一个新的序列建模任务或者数据集,应该选用哪种架构,简单的卷积体系结构在各种任务和数据集上的表现优于常规递归网络(如LSTM),同时表现出更长的有效内存。我们得出结论,应该重新考虑序列建模与递归网络之间的常见关联,并且应将卷积网络视为序列建模任务的自然起点。
引言
最近的研究表明,某些卷积架构可以在音频合成,词级语言建模和机器翻译方面达到最先进的准确性。这就提出了一个问题,即卷积序列建模的这些成功是否仅限于特定的应用领域,还是必须对序列处理和循环网络之间的关联进行更广泛的重新考虑。为了表示卷积网络,我们描述了适用于所有任务的通用时间卷积网络(TCN)体系结构。该架构是根据最近的研究得出的,但是故意结合了现代卷积架构的一些最佳实践,使其保持简单。将其与规范的递归体系结构(例如LSTM和GRU)进行了比较。结果表明,在广泛的序列建模任务中,TCN令人信服地胜过基线循环架构。
TCN体系结构不仅比标准的递归网络(如LSTM和GRU)更准确,而且更简单明了。
TCN
我们将提出的体系结构称为时间卷积网络(TCN),强调我们采用此术语不是作为真正新体系结构的标签,而是作为一系列体系结构的简单描述性术语。
TCN的显着特征是:1)体系结构中的卷积是因果关系的,这意味着从将来到过去都没有信息“泄漏”;
2)架构可以采用任意长度的序列并将其映射到相同长度的输出序列
通过如何结合非常深的网络(使用残差层增强),以及扩张卷积(dilated convolutions)来构建非常长的有效历史信息记录。
序列模型 Sequence Modeling
给出一段输入序列x0 ... xT,预测一些相关输出y0...yT。
因果卷积
TCN基于两个原则:网络产生的输出长度与输入长度相同,以及从将来到过去不会泄漏的事实。TCN使用一维全卷积网络(FCN)[1]其中每个隐藏层的长度与输入层的长度相同,并且填充长度为0(内核大小--1)被添加以使后续层的长度与先前的层相同。为了达到第二点,TCN使用因果卷积,即在卷积中时间t的输出仅与时间t或更早的上一层中的元素卷积。
TCN = 1D FCN +causal convolutions
此基本设计的主要缺点在于,为了获得较长的有效历史记录大小,我们需要一个非常深的网络或非常大的过滤器,这两种方法在首次引入时都不是特别可行。因此,在以下各节中,我们描述如何将现代卷积体系结构中的技术集成到TCN中,以允许非常深的网络和非常长的有效历史。
Dilated Convolution
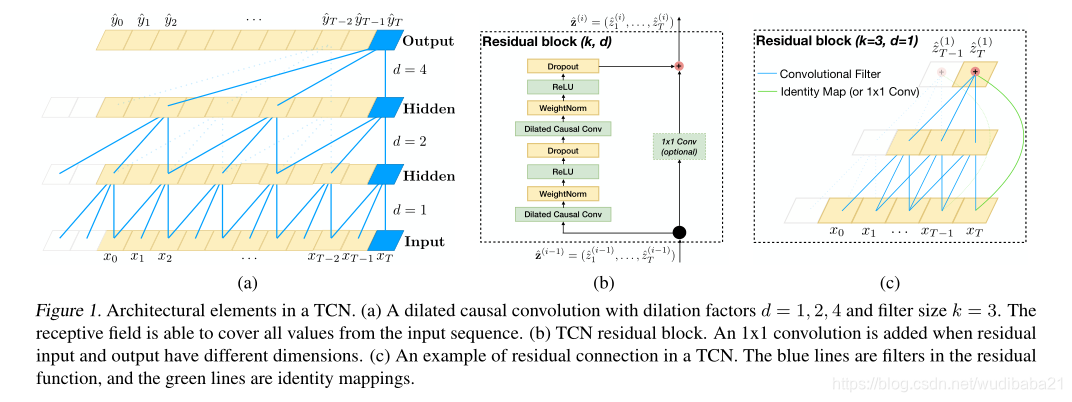
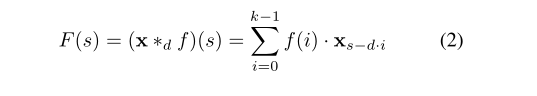
其中d是扩张因子,k是滤波器大小,s-d·i表示过去的方向。因此,膨胀等效于在每两个相邻的滤波器抽头之间引入一个固定的阶跃。当d = 1时,膨胀卷积减小为规则卷积。使用较大的膨胀可使顶层的输出代表更大范围的输入,从而有效地扩展了ConvNet的接收范围。
优势
可变长度输入。就像RNN以循环方式对可变长度的输入进行建模一样,TCN也可以通过滑动一维卷积内核来接受任意长度的输入。这意味着,对于任意长度的顺序数据,可以将TCN用作RNN的直接替代。
更低的内存需要(模型更小)
更稳定的梯度
灵活的接受域大小
更好的并行化
缺点
评估期间的数据存储:在评估/测试中,RNN仅需保持隐藏状态并采用当前输入xt即可生成预测。换句话说,通过固定长度的向量ht提供整个历史的“摘要”,并且可以丢弃实际观察到的序列。相反,TCN需要采用原始序列,直到有效的历史记录长度为止,因此在评估期间可能需要更多的存储空间。
迁移学习时超参数更改:不同领域对模型进行预测所需的历史记录数量可能有不同的要求。因此,当将模型从仅需要很少内存(即,较小的k和d)的域转移至需要更长内存(即,较大的k和d)的域时,TCN可能会因为没有足够大的接收场。
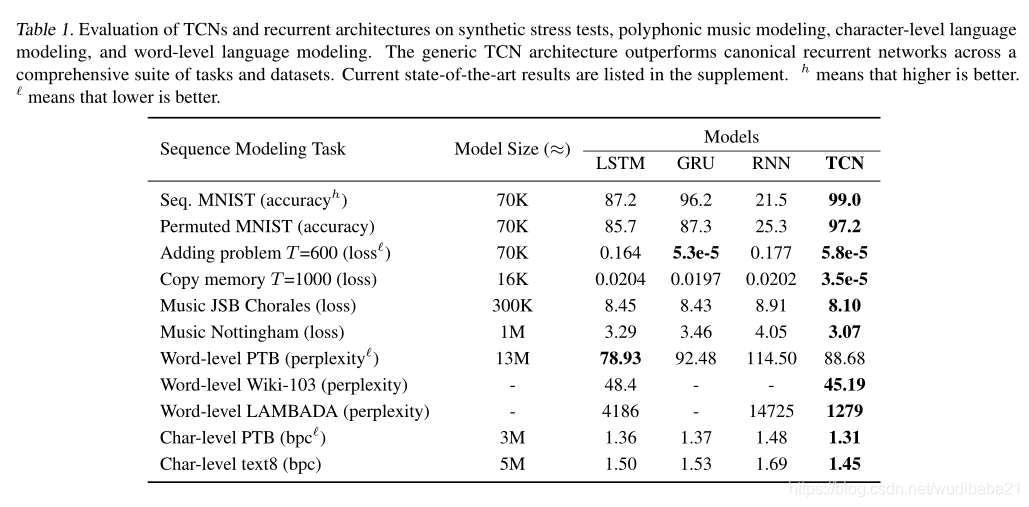
实验
参考文献
- Long, Jonathan, Shelhamer, Evan, and Darrell, Trevor. Fully convolutional networks for semantic segmentation. In CVPR,2015.


















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









