










实验二、环境大数据(必须基于实验一验证通过的环境)
一、实验目的
- 学会分析环境数据文件;
- 学会编写解析环境数据文件并进行统计的代码;
- 学会进行递归MapReduce。
二、实验要求
在服务器上运行从北京2016年1月到6月这半年间的历史天气和空气质量数据文件中分析出的环境统计结果,包含月平均气温、空气质量分布情况等。
三、实验原理
近年来,由于雾霾问题的持续发酵,越来越多的人开始关注城市相关的环境数据,包括空气质量数据、天气数据等等。
如果每小时记录一次城市的天气实况和空气质量实况信息,则每个城市每天都会产生24条环境数据,全国所有2500多个城市如果均如此进行记录,那每天产生的数据量将达到6万多条,每年则会产生2190万条记录,已经可以称得上环境大数据。
对于这些原始监测数据,我们可以根据时间的维度来进行统计,从而得出与该城市相关的日度及月度平均气温、空气质量优良及污染天数等等,从而为研究空气污染物扩散条件提供有力的数据支持。
本实验中选取了北京2016年1月到6月这半年间的每小时天气和空气质量数据(未取到数据的字段填充“N/A”),利用MapReduce来统计月度平均气温和半年内空气质量为优、良、轻度污染、中度污染、重度污染和严重污染的天数。
四、实验步骤
1、 分析数据文件
打开terminal,在家目录下,下载并查看环境数据文件beijing.txt
wget http://i9000.net:8888/sgn/HUP/HadoopDeployPro/beijing.txt
查看前20行数据
head -20 beijing.txt
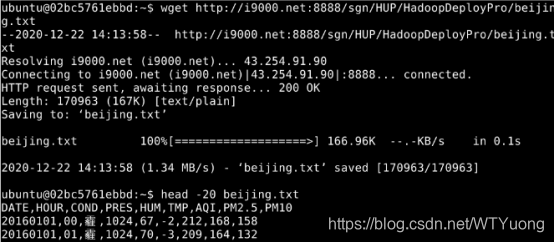
图1环境数据文件格式可以看到,我们需要关心的数据有第一列DATE、第二列HOUR、第六列TMP和第七列AQI。
2、 将数据文件上传至HDFS
将家目录下数据beijing.txt上传到HDFS的/input目录上。
hadoop fs -mkdir /input
hadoop fs -put ~/beijing.txt /input
3 、编写月平均气温统计程序
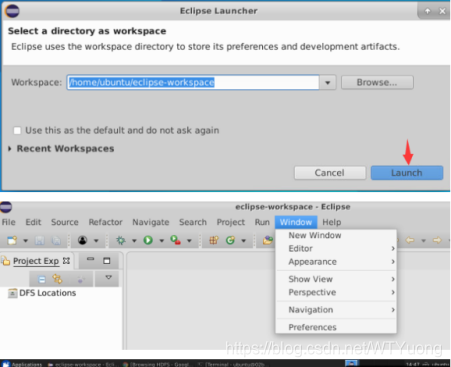
打开eclipse——Window——preferences,选择Hadoop的安装目录如下图,点击apply and close
在Eclipse上新建MapReduce项目,命名为TmpStat,在src目录下新建文件 TmpStat.java,并键入如下代码。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class TmpStat
{
public static class StatMapper extends Mapper<Object, Text, Text, IntWritable>
{
private IntWritable intValue = new IntWritable();
private Text dateKey = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
String[] items = value.toString().split(",");
String date = items[0];
String tmp = items[5];
if(!"DATE".equals(date) && !"N/A".equals(tmp))
{//排除第一行说明以及未取到数据的行
dateKey.set(date.substring(0, 6));
intValue.set(Integer.parseInt(tmp));
context.write(dateKey, intValue);
}
}
}
public static class StatReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
{
int tmp_sum = 0;
int count = 0;
for(IntWritable val : values)
{
tmp_sum += val.get();
count++;
}
int tmp_avg = tmp_sum/count;
result.set(tmp_avg);
context.write(key, result);
}
}
public static void main(String args[])
throws IOException, ClassNotFoundException, InterruptedException
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "MonthlyAvgTmpStat");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, args[0]);
job.setJarByClass(TmpStat.class);
job.setMapperClass(StatMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(StatReducer.class);
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
使用Eclipse软件将TmpStat项目导出成Jar文件,指定主类为TmpStat,命名为tmpstat.jar,并保存至家目录下
4 、查看月平均气温统计结果
在client上执行tmpstat.jar,指定输出目录为/monthlyavgtmp,reducer数量为1。如图2所示:
cd ~
hadoop jar tmpstat.jar TmpStat /input /monthlyavgtmp 1
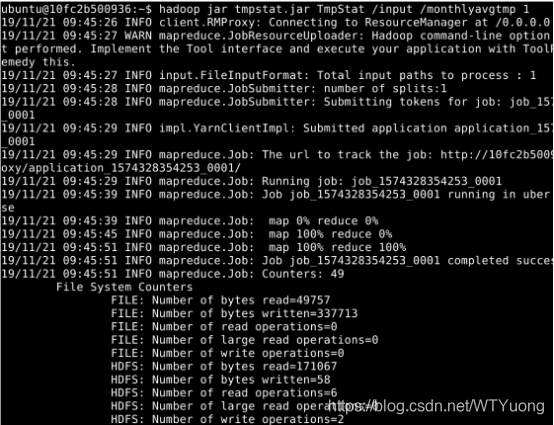
图2 运行tmpstat.jar
查看统计结果。如图3所示:
hadoop fs -ls /monthlyavgtmp
hadoop fs -cat /monthlyavgtmp/part-r-00000
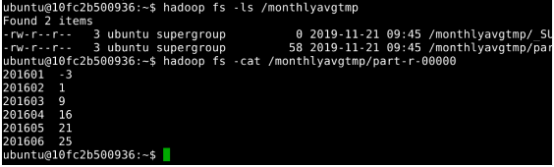
图3 查看月平均气温统计结果
5、 编写每日空气质量统计程序
在Eclipse上新建MapReduce项目,命名为AqiStatDaily,在src目录下新建文件 AqiStatDaily.java,并键入如下代码。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class AqiStatDaily
{
public static class StatMapper extends Mapper<Object, Text, Text, IntWritable>
{
private IntWritable intValue = new IntWritable();
private Text dateKey = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
String[] items = value.toString().split(",");
String date = items[0];
String aqi = items[6];
if(!"DATE".equals(date) && !"N/A".equals(aqi))
{
dateKey.set(date);
intValue.set(Integer.parseInt(aqi));
context.write(dateKey, intValue);
}
}
}
public static class StatReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
{
int aqi_sum = 0;
int count = 0;
for(IntWritable val : values)
{
aqi_sum += val.get();
count++;
}
int aqi_avg = aqi_sum/count;
result.set(aqi_avg);
context.write(key, result);
}
}
public static void main(String args[])
throws IOException, ClassNotFoundException, InterruptedException
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "AqiStatDaily");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, args[0]);
job.setJarByClass(AqiStatDaily.class);
job.setMapperClass(StatMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(StatReducer.class);
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

使用Eclipse软件将AqiStatDaily项目导出成Jar文件,指定主类为AqiStatDaily,命名为aqistatdaily.jar,并保存在家目录下。
6、 查看每日空气质量统计结果
在家目录下执行aqistatdaily.jar,指定输出目录为/aqidaily,reducer数量为3。如图4所示:
cd ~
hadoop jar aqistatdaily.jar AqiStatDaily /input /aqidaily 3
图4 运行aqistatdaily.jar
查看统计结果文件。如图5所示:
hadoop fs -ls /aqidaily

图5 查看aqistatdaily.jar运行结果文件
可以看到,结果文件被分成了3个部分,依次查看这3个文件的内容,即可看到每天的空气质量统计结果数据。如图6所示:
hadoop fs -cat /aqidaily/p*
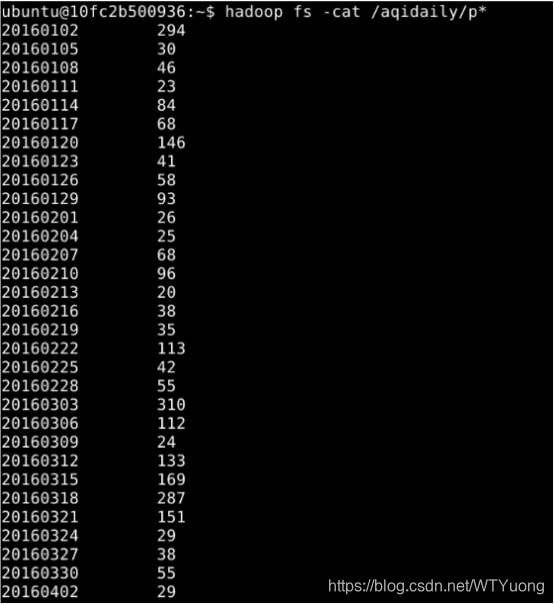
图6 查看每日空气质量统计结果
7 、将每日空气质量统计文件进行整合
将每日空气质量统计结果保存到aqidaily.txt。
hadoop fs -cat /aqidaily/part-r-00000 > aqidaily.txt
hadoop fs -cat /aqidaily/part-r-00001 >> aqidaily.txt
hadoop fs -cat /aqidaily/part-r-00002 >> aqidaily.txt
cat aqidaily.txt |wc -l
在HDFS上创建/aqiinput目录,并将aqidaily.txt上传至该目录下
hadoop fs -mkdir /aqiinput
hadoop fs -put aqidaily.txt /aqiinput
8、 编写各空气质量天数统计程序
在Eclipse上新建MapReduce项目,命名为AqiStat,在src目录下新建文件 AqiStat.java,并键入如下代码。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class AqiStat
{
public static final String GOOD = "优";
public static final String MODERATE = "良";
public static final String LIGHTLY_POLLUTED = "轻度污染";
public static final String MODERATELY_POLLUTED = "中度污染";
public static final String HEAVILY_POLLUTED = "重度污染";
public static final String SEVERELY_POLLUTED = "严重污染";
public static class StatMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text cond = new Text();
// map方法,根据AQI值,将对应空气质量的天数加1
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
String[] items = value.toString().split("\t");
int aqi = Integer.parseInt(items[1]);
if(aqi <= 50)
{
// 优
cond.set(GOOD);
}
else if(aqi <= 100)
{
// 良
cond.set(MODERATE);
}
else if(aqi <= 150)
{
// 轻度污染
cond.set(LIGHTLY_POLLUTED);
}
else if(aqi <= 200)
{
// 中度污染
cond.set(MODERATELY_POLLUTED);
}
else if(aqi <= 300)
{
// 重度污染
cond.set(HEAVILY_POLLUTED);
}
else
{
// 严重污染
cond.set(SEVERELY_POLLUTED);
}
context.write(cond, one);
}
}
// 定义reduce类,对相同的空气质量状况,把它们<K,VList>中VList值全部相加
public static class StatReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String args[])
throws IOException, ClassNotFoundException, InterruptedException
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "AqiStat");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, args[0]);
job.setJarByClass(AqiStat.class);
job.setMapperClass(StatMapper.class);
job.setCombinerClass(StatReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(StatReducer.class);
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
使用Eclipse软件将AqiStat项目导出成Jar文件,指定主类为AqiStat,命名为aqistat.jar,并保存至家目录下。
9 、查看各空气质量天数统计结果
在家目录下执行aqistat.jar,指定输出目录为/aqioutput,reducer数量为1。如图7所示:
hadoop jar aqistat.jar AqiStat /aqiinput /aqioutput 1
图7 运行aqistat.jar
查看统计结果。如图8所示:
hadoop fs -ls /aqioutput
hadoop fs -cat /aqioutput/part-r-00000
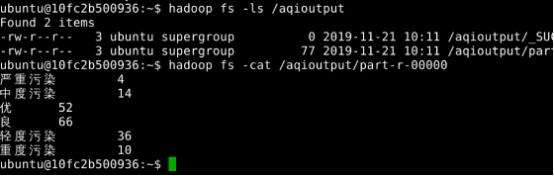
图8 查看各空气质量状况天数统计结果
五、其他
1.复制到虚拟机时不能有中文
2.文件名前面有*时,按Ctrl+S保存,星号就没有了
3.删除无数据的文件。Hadoop dfs -rm -r /monthlyavgtmp



















 4069
4069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











