




一、知识准备
逻辑回归:又称Logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘、疾病自动诊断、经济预测等领域。逻辑回归从本质来说属于二分类问题。二分类问题是指预测的y值只有两个取值(0或1)。
二、数据集描述
数据集文件:credit-overdue.csv
数据集特征:
debt:欠款金额(单位:万元)
income:月收入(单位:万元)
overdue:是否逾期(0=未逾期,1=逾期)
共150条记录,其中逾期(1)的记录约占25%,数据分布基本平衡。
三、实验目的
前进银行搜集了贷款用户的数据,包括欠款额(百元)、月收入(元)和是否逾期的信息。使用五个用户的数据建立一个逻辑回归模型。通过6号用户的个人信息,判断用户贷款20万元后是否会逾期。
主要完成以下三个目的:
1)构建逻辑回归模型预测用户贷款后是否逾期
2)评估模型在预测逾期风险方面的有效性
3)使用模型预测新用户贷款后的逾期风险
四、实验步骤及结果展示
4.1 导入必要库包
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
4.2 加载数据集并查看前五行
df = pd.read_csv("credit-overdue.csv", header=0) # 加载数据集
df.head() #查看前5行数据
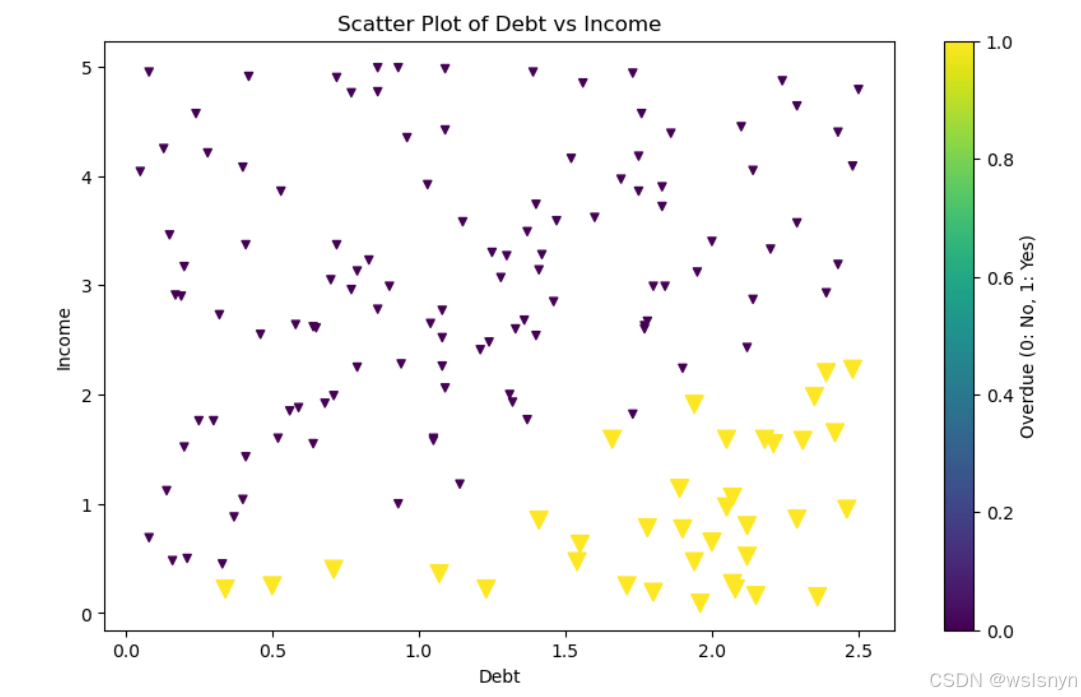
4.3 绘制债务与收入散点图
plt.figure(figsize=(10, 6)) #图形初始化
map_size = {0: 20, 1: 100} #设置点的大小映射
size = list(map(lambda x: map_size[x], df['overdue'])) #将overdue列的每个值通过字典映射为对应大小
scatter = plt.scatter(df['debt'], df['income'], s=size, c=df['overdue'], marker='v', cmap='viridis') #创建散点图
plt.xlabel('Debt')
plt.ylabel('Income')
plt.title('Scatter Plot of Debt vs Income')
plt.colorbar(scatter, label='Overdue (0: No, 1: Yes)') # 正确关联到scatter对象
plt.show()
4.4 定义Sigmoid函数
#定义sigmoid函数
def sigmoid(z):
sigmoid = 1 / (1 + np.exp(-z))
return sigmoid
4.5 定义对数损失函数
#定义对数损失函数
def loss(h, y):
loss = (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
return loss
4.6 定义梯度下降函数
#定义梯度下降函数
def gradient(X, h, y):
gradient = np.dot(X.T, (h - y)) / y.shape[0]
return gradient
4.7 定义逻辑回归函数
# 定义逻辑回归函数
def Logistic_Regression(x, y, lr, num_iter):
intercept = np.ones((x.shape[0], 1)) # 初始化截距为 1
x = np.concatenate((intercept, x), axis=1) # 添加截距项
w = np.zeros(x.shape[1]) # 初始化参数为 0
l_list = [] # 保存损失函数值
for i in range(num_iter): # 梯度下降迭代
z = np.dot(x, w) # 线性函数
h = sigmoid(z) # sigmoid 函数
g = gradient(x, h, y) # 计算梯度
w -= lr * g # 通过学习率 lr 计算步长并执行梯度下降
l = loss(h, y) # 计算损失函数值
l_list.append(l) # 保存损失函数值
return w, l_list # 返回训练后的参数 w 和损失函数值列表
4.8 逻辑回归模型训练
#数据准备
x = df[['debt','income']].values #提取特征列('debt'和'income')并转换为NumPy数组
y = df['overdue'].values #提取目标变量('overdue')并转换为NumPy数组
#超参数设置
lr = 0.001 # 学习率
num_iter = 10000 # 迭代次数
# 模型训练
w, l_list = Logistic_Regression(x, y, lr, num_iter)
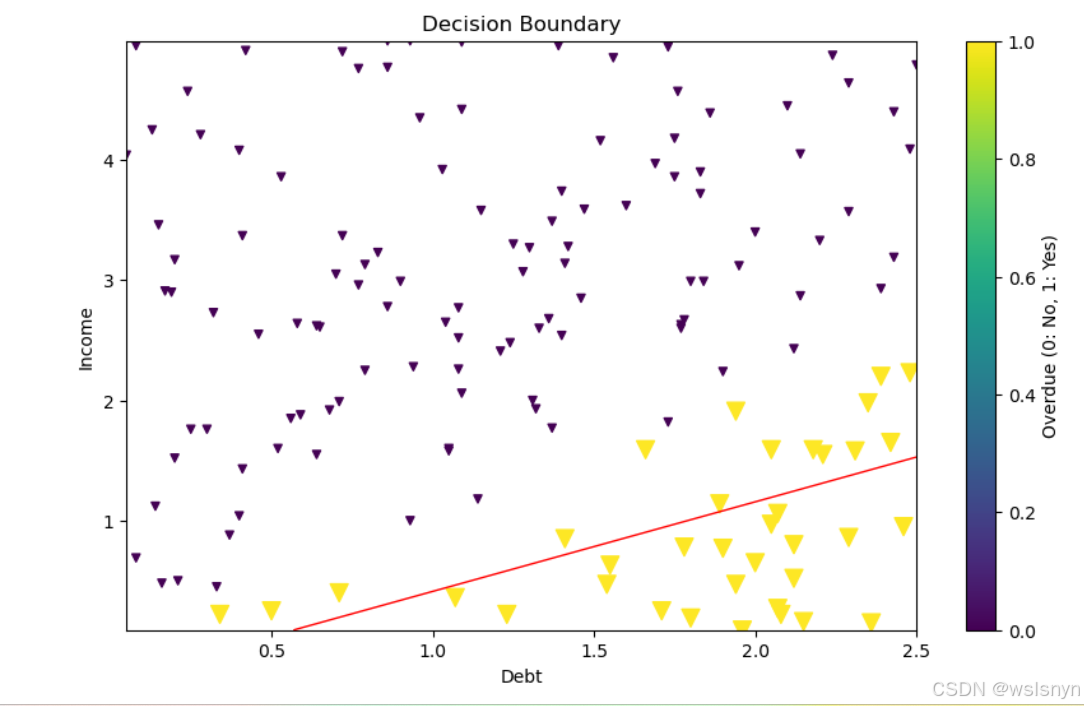
4.9 绘制决策边界
plt.figure(figsize=(10, 6)) #初始化图形
scatter = plt.scatter(df['debt'], df['income'], s=size, c=df['overdue'], marker='v', cmap='viridis') #绘制原始数据散点图
#确定坐标范围
x1_min, x1_max = df['debt'].min(), df['debt'].max() #获取debt最小最大值
x2_min, x2_max = df['income'].min(), df['income'].max() #获取income最小最大值
#创建预测网格
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max)) #生成覆盖整个数据范围的网格点
grid = np.c_[xx1.ravel(), xx2.ravel()] #将两个特征列合并为网格坐标矩阵
probs = (np.dot(grid, w[1:]) + w[0]).reshape(xx1.shape) #计算网格点预测值
plt.contour(xx1, xx2, probs, levels=[0.5], linewidths=1, colors='red') #绘制决策边界
#添加图形元素
plt.xlabel('Debt')
plt.ylabel('Income')
plt.title('Decision Boundary')
plt.colorbar(scatter, label='Overdue (0: No, 1: Yes)') # 正确关联到scatter对象
plt.show()
4.10 使用梯度下降法优化模型参数
def Logistic_Regression(x, y, lr, num_iter):
intercept = np.ones((x.shape[0], 1)) # 初始化截距为 1
x = np.concatenate((intercept, x), axis=1)
w = np.zeros(x.shape[1]) # 初始化参数为 1
l_list = [] # 保存损失函数值
for i in range(num_iter): # 梯度下降迭代
z = np.dot(x, w) # 线性函数
h = sigmoid(z) # sigmoid 函数
g = gradient(x, h, y) # 计算梯度
w -= lr * g # 通过学习率 lr 计算步长并执行梯度下降
z = np.dot(x, w) # 更新参数到原线性函数中
h = sigmoid(z) # 计算 sigmoid 函数值
l = loss(h, y) # 计算损失函数值
l_list.append(l)
return l_list
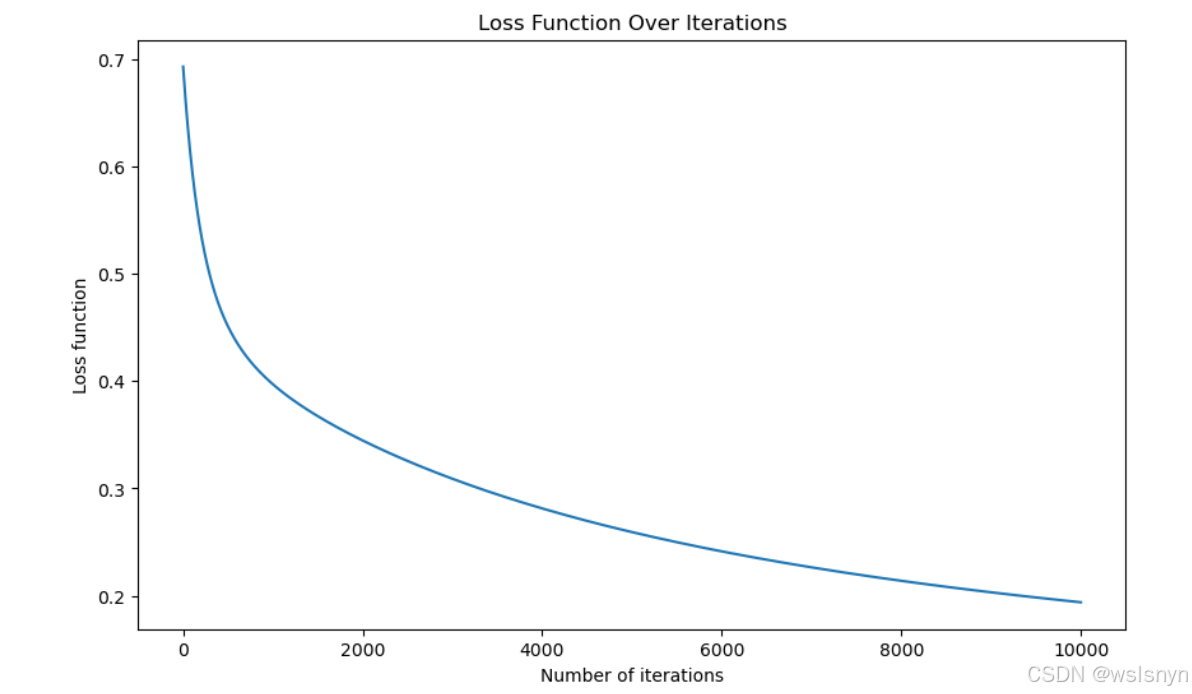
4.11 绘制损失曲线
# 绘图
plt.figure(figsize=(10, 6))
plt.plot(range(len(l_list)), l_list)
plt.xlabel("Number of iterations")
plt.ylabel("Loss function")
plt.title("Loss Function Over Iterations")
plt.show()
ps:如果有需要的话可以添加更多模型评价指标,如分类报告、混淆矩阵、AUC-ROC曲线......
五、结论
通过损失曲线得到以下几个结论
1)损失下降趋势
a.损失从0.7开始,经过10,000次迭代后降至约0.2
b.下降曲线显示模型在学习,但仍有改进空间
2)收敛情况
a.损失仍在持续下降,未完全收敛
b.可能需要更多迭代或调整学习率
3)潜在问题
a.最终损失值0.2相对较高(二元分类理想值应接近0)
b.曲线下降速度可能偏慢(10,000次迭代才降到0.2)
六、其他
因个人需求不同,本文所进行的步骤仅供参考,有其他问题欢迎大家提出,感谢观看!

















 5752
5752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









