







一、知识准备
评分系统是一种常见的推荐系统。可以使用Python等语言基于协同过滤算法来构建一个电影评分预测模型。学习协同过滤算法、UBCF和IBCF。
二、数据来源
数据集来源:
明尼苏达州大学的社会化计算研究中心官网,网站链接为https://grouplens.org/datasets/movielens/
共有四个csv数据集,分别为:links.csv,movies.csv,ratiings.csv,tags.csv
links.csv数据集特征说明:
movieId:MovieLens 使用的电影标识符。
imdbId:IMDb 使用的电影标识符。
tmdbId:The Movie Database 使用的电影标识符。
movies.csv数据集特征说明:
movieId:电影 ID。
title:电影标题,包括发布年份(括号内)。
genres:电影类型,以竖线(|)分隔。
ratiings.csv数据集特征说明:
userId:用户 ID。
movieId:电影 ID。
rating:评分,采用 5 星制,以 0.5 星为增量(0.5 星 - 5.0 星)。
timestamp:时间戳,表示自 1970 年 1 月 1 日午夜(UTC)以来的秒数。
tags.csv数据集特征说明:
userId:用户 ID。
movieId:电影 ID。
tag:用户生成的关于电影的元数据,通常是单个单词或短语,其含义、价值和目的由用户自行决定。
timestamp:时间戳,表示自 1970 年 1 月 1 日午夜(UTC)以来的秒数。
以上四个数据集:
一共包含 100,836 条用户对电影的评分记录;包含 3,683 条用户对电影的标签(tag)记录;涵盖 9,742 部电影。
数据由 610 名用户在 1996 年 3 月 29 日至 2018 年 9 月 24 日之间创建。
数据集生成时间:2018 年 9 月 26 日。
三、业务目标
利用用户对电影的评分和对电影的标签记录,了解用户看电影的喜好,并结合电影的类型,使用基于用户的协同过滤推荐算法制作电影推荐系统,为每位用户推荐他们喜欢的电影。
四、具体步骤及结果
4.1 载入库
#载入库
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import pairwise_distances
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.model_selection import train_test_split4.2 分别载入ratings、movies、tags数据集并展示前五行
#加载ratings数据集,并展示出前五行
ratings_df = pd.read_csv('ratings.csv')
print("前五行数据:")
print(ratings_df.head())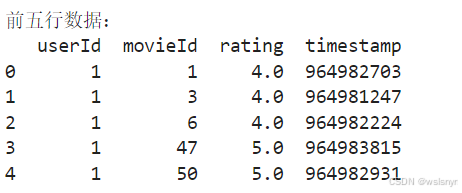
#加载movies数据集,并展示出前五行
movies_df = pd.read_csv('movies.csv')
print("前五行数据:")
print(movies_df.head())
#加载tags数据集,并展示出前五行
tags_df = pd.read_csv('tags.csv')
print("前五行数据:")
print(tags_df.head())
4.3 数据准备和清理
4.3.1 检查是否包含缺失值
# 检查缺失值
print(ratings_df.isnull().sum())
print(movies_df.isnull().sum())
print(tags_df.isnull().sum())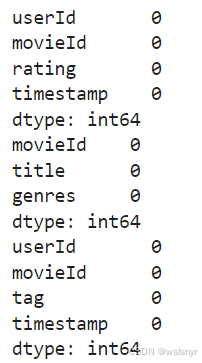 由结果得知数据集没有缺失值,不需要进行缺失值处理
由结果得知数据集没有缺失值,不需要进行缺失值处理
4.3.2 删除重复项
# 删除重复值
ratings_df.drop_duplicates(inplace=True)
movies_df.drop_duplicates(inplace=True)
tags_df.drop_duplicates(inplace=True)4.3.3 将ratings和movies数据通过movieid合并
#将ratings和movies数据通过movieid合并
data = pd.merge(ratings_df, movies_df, on='movieId')该步骤便于后续实验
4.4 探索性数据分析
4.4.1 绘制评分分布直方图
# 评分分布
plt.hist(data['rating'], bins=5, edgecolor='black', alpha=0.7)
plt.title('Rating Distribution')
plt.xlabel('Rating')
plt.ylabel('Frequency')
plt.show()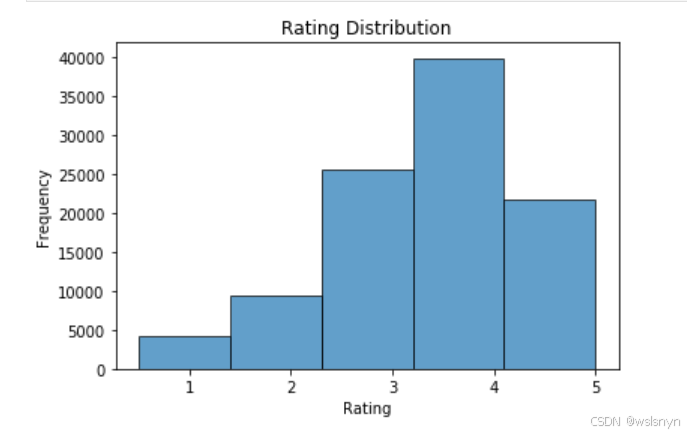
从上图可以看出评分为1分和2分的用户较少,4分的用户最多,大多数用户倾向于给较高分。
4.4.2 绘制电影评分次数直方图
# 电影的评分次数
movie_ratings_count = data['movieId'].value_counts()
plt.hist(movie_ratings_count, bins=10, edgecolor='black', alpha=1)
plt.title('Number of Ratings per Movie')
plt.xlabel('Number of Ratings')
plt.ylabel('Frequency')
plt.show()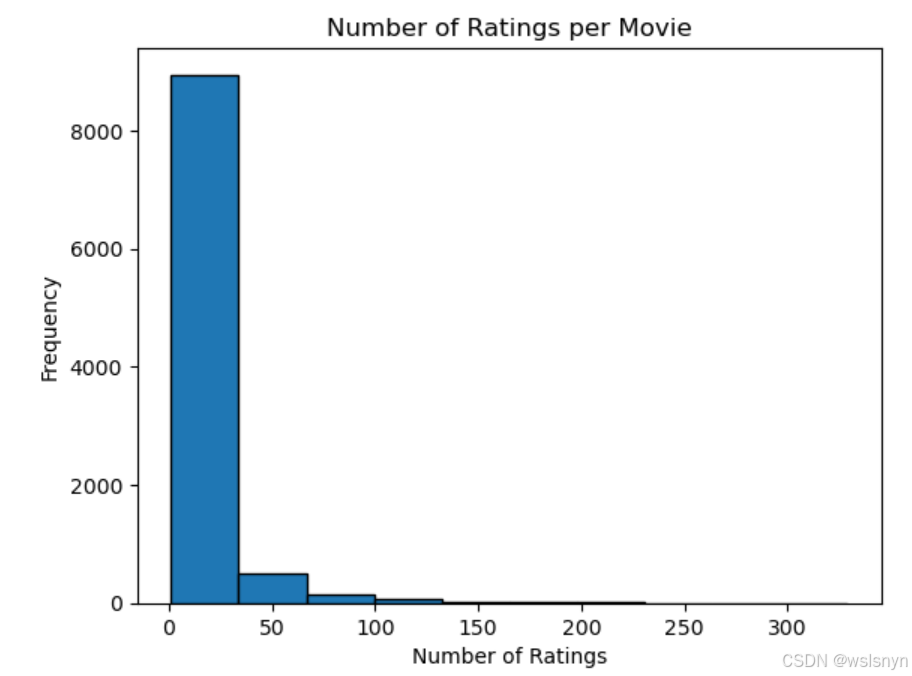
从上图可以看出大部分电影被评分的次数不高,基本集中在50次以内,数据不平衡。
4.5 构建用户—电影评分矩阵
该步骤将评分数据从长格式转换为宽格式,便于后续计算相似度,便于预测评分。
# 构建用户-电影评分矩阵
user_movie_matrix = data.pivot(index='userId', columns='movieId', values='rating').fillna(0)4.6 计算用户之间的相似度
# 计算用户之间的相似度(余弦相似度)
user_similarity = cosine_similarity(user_movie_matrix)
user_similarity_df = pd.DataFrame(user_similarity, index=user_movie_matrix.index, columns=user_movie_matrix.index)4.7 模型训练
4.7.1 划分测试集和训练集
训练集占80%,测试集占20%,随机种子为42。
# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)4.7.2 使用基于用户的协同过滤推荐算法建立推荐模型
def user_based_recommendation(user_id, user_similarity_df, user_movie_matrix, num_neighbors=5):
# 找到与目标用户最相似的用户
similar_users = user_similarity_df[user_id].sort_values(ascending=False).index[1:num_neighbors+1]
# 获取这些相似用户的评分数据
similar_users_ratings = user_movie_matrix.loc[similar_users]
# 计算推荐分数
user_ratings = user_movie_matrix.loc[user_id]
# 计算每个电影的加权平均评分
weighted_sum = similar_users_ratings.T.dot(user_similarity_df.loc[user_id, similar_users])
sum_of_weights = user_similarity_df.loc[user_id, similar_users].sum()
# 避免除以零
if sum_of_weights == 0:
sum_of_weights = 1e-9
recommendations = weighted_sum / sum_of_weights
# 将推荐分数转换为 Series
recommendations = pd.Series(recommendations, index=user_movie_matrix.columns)
# 排除用户已经评分过的电影
recommendations = recommendations[user_ratings == 0]
# 返回推荐分数最高的前 10 部电影
return recommendations.nlargest(10)4.8 评估推荐系统
# 评估推荐系统
def evaluate_recommendation(user_id, recommendations, test_data):
# 获取测试集中目标用户的评分数据
user_test_data = test_data[test_data['userId'] == user_id]
user_test_movies = user_test_data['movieId'].unique()
# 计算推荐系统的准确率
recommended_movies = recommendations.index # 这里 recommendations 是一个 Series
hit_count = len(set(recommended_movies) & set(user_test_movies))
precision = hit_count / len(recommended_movies)
return precision4.9 运行推荐系统
# 获取用户输入的用户 ID
user_id_input = input("Please enter your user ID: ")
# 确保输入的用户 ID 是整数
try:
user_id = int(user_id_input)
except ValueError:
print("Invalid input! Please enter a numeric user ID.")
else:
# 运行推荐系统
recommendations = user_based_recommendation(user_id, user_similarity_df, user_movie_matrix)
print(f'Recommendations for user {user_id}:')
print(recommendations)使用id为1和77的用户进行了运行查看,结果如下
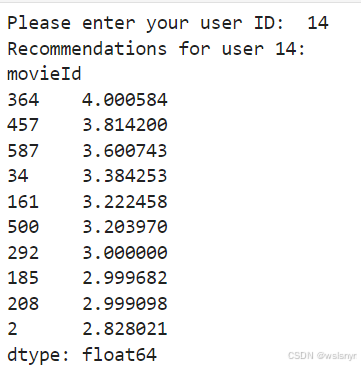
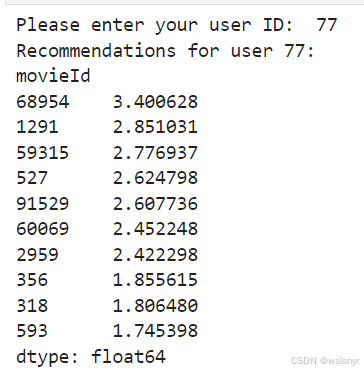

















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









