








摘要
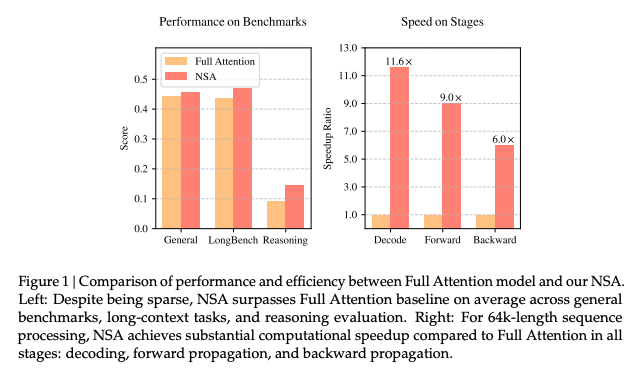
长文本建模对于下一代语言模型至关重要,然而标准注意力机制的高计算成本带来了显著的计算挑战。稀疏注意力为提高效率的同时保持模型能力提供了一个有前景的方向。我们提出了 NSA(Native Sparse Attention),这是一种可原生训练的稀疏注意力机制,通过将算法创新与硬件对齐优化相结合,实现了高效的长文本建模。NSA 采用动态层次化的稀疏策略,将粗粒度的标记压缩与细粒度的标记选择相结合,既保留了全局上下文感知能力,又保持了局部精度。我们的方法在稀疏注意力设计上提出了两项关键创新:(1)通过算术强度平衡的算法设计实现显著加速,并针对现代硬件进行了实现优化。(2)支持端到端训练,减少预训练计算量,同时不牺牲模型性能。如图 1 所示,实验表明使用 NSA 预训练的模型在通用基准测试、长文本任务和基于指令的推理中均保持或超过了全注意力模型的性能。同时,NSA 在处理 64k 长度的序列时,在解码、前向传播和反向传播方面均实现了显著的加速,验证了其在整个模型生命周期中的效率。
1. 引言
研究界越来越认识到长文本建模对于下一代大型语言模型是一项关键能力,这由多种现实世界应用推动,包括深入推理(DeepSeek-AI, 2025; Zelikman et al., 2022)、仓库级代码生成(Zhang et al., 2023a; Zhang et al.)和多轮自主代理系统(Park et al., 2023)。最近的突破,包括 OpenAI 的 o 系列模型、DeepSeek-R1(DeepSeek-AI, 2025)和 Gemini 1.5 Pro(Google et al., 2024),使模型能够处理整个代码库、长篇文档、在数千个标记上保持连贯的多轮对话以及执行长距离依赖的复杂推理。然而,随着序列长度的增加,标准注意力(Vaswani et al., 2017)机制的高复杂性(Zaheer et al., 2020)成为一个关键的延迟瓶颈。理论估计表明,在解码 64k 长度上下文时,注意力计算占总延迟的 70-80%,凸显了对更高效注意力机制的迫切需求。
利用 softmax 注意力的固有稀疏性(Ge et al., 2023; Jiang et al., 2023)是一种自然的高效长文本建模方法,通过选择性计算关键的查询-键对,可以在保留性能的同时显著减少计算开销。最近的进展通过多种策略展示了这种潜力:KV 缓存驱逐方法(Li et al., 2024; Zhang et al., 2023b; Zhou et al., 2024)、块状 KV 缓存选择方法(Tang et al., 2024; Xiao et al., 2024)以及基于采样、聚类或哈希的选择方法(Chen et al., 2024; Desai et al., 2024; Liu et al., 2024)。尽管这些方法很有前景,但现有的稀疏注意力方法在实际部署中往往不尽如人意。许多方法未能实现与其理论增益相当的加速;此外,大多数方法主要关注推理阶段,缺乏有效的训练时支持以充分利用注意力的稀疏模式。
为了克服这些局限性,部署有效的稀疏注意力必须解决两个关键挑战:(1)硬件对齐的推理加速:将理论计算减少转化为实际速度提升,需要在预填充和解码阶段进行硬件友好的算法设计,以缓解内存访问和硬件调度瓶颈;(2)训练感知的算法设计:通过可训练的操作符实现端到端计算,以减少训练成本,同时保持模型性能。这些要求对于实际应用实现快速长文本推理或训练至关重要。在考虑这两个方面时,现有方法仍存在明显差距。
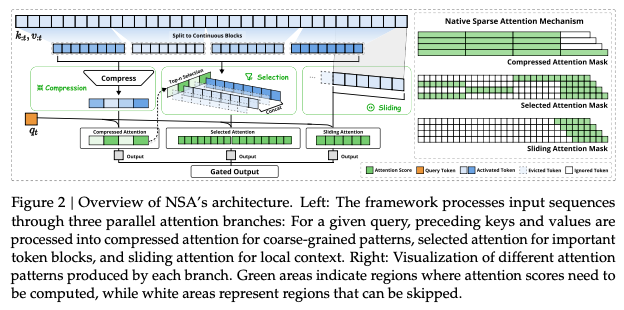
为了实现更有效和高效的稀疏注意力,我们提出了 NSA,这是一种具有层次化标记建模的可原生训练的稀疏注意力架构。如图 2 所示,NSA 通过将键和值组织成时间块,并通过三个注意力路径进行处理,从而减少了每个查询的计算量:压缩的粗粒度标记、选择性保留的细粒度标记以及用于局部上下文信息的滑动窗口。然后我们实现了专用内核以最大化其实际效率。NSA 引入了两个核心创新,分别对应上述关键要求:(1)硬件对齐系统:针对 Tensor Core 利用率和内存访问优化块状稀疏注意力,确保算术强度平衡。(2)训练感知设计:通过高效算法和反向操作符实现稳定的端到端训练。这种优化使 NSA 能够支持高效的部署和端到端训练。
我们通过在真实世界语言语料库上的全面实验来评估 NSA。在 27B 参数的 Transformer 骨干网络上进行预训练,使用 260B 个标记,我们在通用语言评估、长文本评估和链式推理评估中评估了 NSA 的性能。我们进一步在 A100 GPU 上与优化的 Triton(Tillet et al., 2019)实现进行了内核速度比较。实验结果表明,NSA 实现了与全注意力基线相当或更优的性能,同时优于现有的稀疏注意力方法。此外,与全注意力相比,NSA 在解码、前向和反向阶段均实现了显著的加速,随着序列长度的增加,加速比也随之增加。这些结果验证了我们的层次化稀疏注意力设计在平衡模型能力和计算效率方面的有效性。
2. 重新思考稀疏注意力方法
现代稀疏注意力方法在减少 Transformer 模型的理论计算复杂性方面取得了显著进展。然而,大多数方法主要在推理阶段应用稀疏性,同时保留预训练的全注意力骨干网络,可能会引入架构偏差,限制其充分利用稀疏注意力优势的能力。在介绍我们的原生稀疏架构之前,我们通过两个关键视角系统地分析了这些局限性。
2.1. 高效推理的幻象
尽管在注意力计算中实现了稀疏性,但许多方法未能实现相应的推理延迟减少,主要由于两个挑战:
-
阶段限制的稀疏性:例如 H2O(Zhang et al., 2023b)的方法在自回归解码时应用稀疏性,但在预填充阶段需要进行计算密集型的预处理(例如注意力图计算、索引构建)。相比之下,MInference(Jiang et al., 2024)的方法仅关注预填充阶段的稀疏性。这些方法未能在所有推理阶段实现加速,因为至少有一个阶段的计算成本与全注意力相当。这种阶段专业化降低了这些方法在预填充主导的工作负载(如书籍摘要和代码补全)或解码主导的工作负载(如长链式推理(Wei et al., 2022))中的加速能力。
-
与先进注意力架构的不兼容性:一些稀疏注意力方法未能适应现代解码高效架构,如多查询注意力(MQA)(Shazeer, 2019)和分组查询注意力(GQA)(Ainslie et al., 2023),这些架构通过在多个查询头之间共享 KV 来显著减少解码过程中的内存访问瓶颈。例如,在 Quest(Tang et al., 2024)等方法中,每个注意力头独立选择其 KV 缓存子集。尽管它在多头注意力(MHA)模型中展示了一致的计算稀疏性和内存访问稀疏性,但在基于 GQA 等架构的模型中,KV 缓存的内存访问量对应于同一 GQA 组内所有查询头的选择的并集。这种架构特性意味着,尽管这些方法可以减少计算操作,但所需的 KV 缓存内存访问量仍然相对较高。这一限制迫使人们在稀疏注意力方法中做出关键选择:虽然一些稀疏注意力方法减少了计算量,但其分散的内存访问模式与先进架构的高效内存访问设计相冲突。
这些局限性源于许多现有的稀疏注意力方法专注于 KV 缓存减少或理论计算减少,但在先进的框架或后端中难以实现显著的延迟减少。这促使我们开发结合先进架构和硬件高效实现的算法,以充分利用稀疏性来提高模型效率。
2.2. 可训练稀疏性的神话
我们对原生可训练稀疏注意力的追求是基于对仅推理方法的两个关键见解:性能退化:在后处理中应用稀疏性迫使模型偏离其预训练的优化轨迹。正如 Chen et al.(2024)所展示的那样,前 20% 的注意力只能覆盖 70% 的总注意力分数,使得预训练模型中的检索头等结构在推理过程中容易被剪枝。训练效率需求:高效处理长序列训练对于现代大语言模型开发至关重要。这包括在更长的文档上进行预训练以增强模型容量,以及后续的适应阶段,如长文本微调和强化学习。然而,现有的稀疏注意力方法主要针对推理,对训练中的计算挑战关注较少。这一局限性阻碍了通过高效训练开发更具能力的长文本模型。此外,将现有的稀疏注意力适应训练的尝试也暴露了挑战:
-
不可训练组件:像 ClusterKV(Liu et al., 2024)(包括 k-means 聚类)和 MagicPIG(Chen et al., 2024)(包括基于 SimHash 的选择)等方法中的离散操作在计算图中造成了不连续性。这些不可训练的组件阻止了梯度通过标记选择过程流动,限制了模型学习最优稀疏模式的能力。
-
低效的反向传播:一些理论上可训练的稀疏注意力方法在实际训练中存在效率问题。例如,HashAttention(Desai et al., 2024)中使用的基于标记粒度的选择策略导致在注意力计算过程中需要从 KV 缓存中加载大量单独的标记。这种非连续的内存访问阻止了像 FlashAttention 这样的快速注意力技术的高效适应,这些技术依赖于连续的内存访问和块状计算以实现高吞吐量。因此,实现被迫退回到低硬件利用率,显著降低了训练效率。
2.3. 原生稀疏性作为必然选择
推理效率和训练可行性的这些局限性促使我们对稀疏注意力机制进行根本性的重新设计。我们提出了 NSA,这是一个原生稀疏注意力框架,同时解决了计算效率和训练需求。在接下来的部分中,我们将详细介绍 NSA 的算法设计和操作符实现。
3. 方法论
我们的技术方法涵盖了算法设计和内核优化。在接下来的小节中,我们首先介绍方法论的背景。然后,我们介绍 NSA 的整体框架,接着是其关键算法组件。最后,我们详细介绍了我们针对硬件优化的内核设计,以最大化实际效率。
3.1. 背景
注意力机制在语言建模中被广泛使用,其中每个查询标记计算与所有前面的键
的相关性分数,以生成值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3732
3732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











