






论文地址:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
论文翻译:原生稀疏注意力机制(NSA):硬件对齐且可原生训练的稀疏注意力机制-论文阅读
论文的背景与动机
近年来,我们见证了长文本建模在 AI 领域的重要性日益凸显。无论是深度推理、代码库生成、还是多轮对话,都离不开模型对长序列信息的有效处理能力。像 OpenAI 的 o-series 模型、DeepSeek-R1、以及 Google Gemini 1.5 Pro 等,都展现了处理超长文本的强大潜力。
然而,传统 Attention 机制的计算复杂度随着序列长度的增加而呈平方级增长,这成为了制约 LLM 发展的关键瓶颈。计算成本高昂,延迟成为问题, 如何在保证模型性能的同时,提升长文本处理的效率,成为了亟待解决的难题。以解码64k长度上下文为例,softmax注意力计算的延迟占总延迟的70 - 80%,这凸显了寻求高效注意力机制的紧迫性。
为提升效率,利用softmax注意力的固有稀疏性是一种可行途径,即选择性计算关键查询 - 键对,在保持性能的同时降低计算开销。现有方法虽各有探索,但在实际应用中存在诸多局限:
- 推理效率假象:许多稀疏注意力方法在推理时未能实现预期的加速效果。一方面,部分方法存在阶段受限的稀疏性,如H2O在解码阶段应用稀疏性,但预填充阶段计算量大;MInference则只关注预填充阶段稀疏性,导致至少一个阶段计算成本与全注意力相当,无法在不同推理负载下有效加速。另一方面,一些方法与先进注意力架构不兼容,如Quest在基于GQA的模型中,虽能减少计算操作,但KV缓存内存访问量仍较高,无法充分利用先进架构的优势。
- 可训练稀疏性的误区:仅在推理阶段应用稀疏性会导致模型性能下降,且现有稀疏注意力方法大多未有效解决训练阶段的计算挑战。例如,基于聚类的方法(如ClusterKV)存在动态聚类计算开销大、算子优化困难、实现受限等问题;一些方法的离散操作(如MagicPIG中的SimHash选择)使计算图不连续,阻碍梯度传播;HashAttention等方法的非连续内存访问模式,无法有效利用快速注意力技术(如FlashAttention),降低了训练效率。
针对这些问题,本文提出了原生可训练的稀疏注意力机制(Native Sparse Attention,NSA),旨在通过算法创新与硬件对齐优化,实现高效的长上下文建模,平衡模型性能与计算效率。
NSA 的核心亮点
DeepSeek 提出的 NSA (Native Sparse Attention,原生稀疏注意力) 机制,巧妙地将算法创新与硬件优化相结合,旨在实现高效的长文本建模。
NSA 的核心亮点可以概括为以下两点:
1.动态分层稀疏策略: NSA 采用了一种动态分层的稀疏策略,结合了粗粒度的 Token 压缩 和 细粒度的 Token 选择。这种策略既能保证模型对全局上下文的感知,又能兼顾局部信息的精确性
2.两大关键创新:
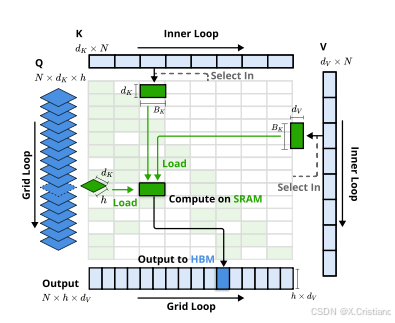
算术强度平衡的算法设计与硬件优化: NSA 通过精巧的算法设计,并针对现代硬件进行了实现优化,显著提升了计算速度
端到端可训练: NSA 支持端到端训练,这意味着它不仅在推理阶段高效,还能减少预训练的计算量,同时不牺牲模型性能!
实验效果惊艳:性能不降反升,速度大幅提升!
实验结果令人振奋!如图 所示,在通用基准测试、长文本任务和指令推理方面,使用 NSA 预训练的模型性能不仅没有下降,反而超越了 Full Attention 模型!
更重要的是,在处理 64k 长度的序列时,NSA 在解码、前向传播和反向传播等各个阶段都实现了显著的速度提升,最高可达 11.6 倍! 这充分证明了 NSA 在模型生命周期各个阶段的效率优势

现有稀疏注意力方法的局限性
论文也深入分析了现有稀疏注意力方法的局限性,主要体现在两个方面:
1.推理效率的“假象”: 很多方法虽然在理论上实现了稀疏计算,但在实际推理延迟方面提升有限。这主要是因为:
• 阶段限制的稀疏性: 例如,有些方法只在自回归解码时应用稀疏性,但在预填充阶段仍然需要大量计算
• 与先进 Attention 架构的不兼容性: 一些稀疏注意力方法难以适配像 MQA 和 GQA 这样的现代高效解码架构,导致内存访问瓶颈依然存在
2.可训练稀疏性的“神话”: 许多方法主要关注推理阶段的稀疏性,而忽略了训练阶段。这导致:
• 性能退化: 后验应用稀疏性可能导致模型偏离预训练的优化轨迹。
• 训练效率需求: 长序列训练对于提升模型能力至关重要,但现有方法在训练效率方面存在不足。
• 不可训练的组件: 一些方法引入了不可微的离散操作,阻碍了梯度传播,限制了模型学习最佳稀疏模式的能力。
• 反向传播效率低下: 一些理论上可训练的方法,在实际训练中效率低下,例如 Token 粒度的选择策略可能导致非连续的内存访问,影响硬件利用率。
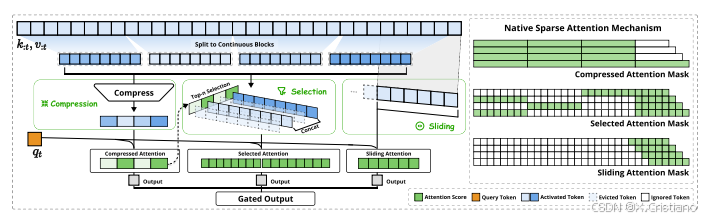
NSA 的核心组件:分层稀疏,逐层优化
为了克服上述局限性,NSA 架构采用了分层 Token 建模,并通过三个并行的注意力分支处理输入序列:
-
压缩注意力 (Compressed Attention): 处理粗粒度的模式,通过压缩 Token 块来捕获全局信息。
-
选择注意力 (Selected Attention): 处理重要的 Token 块,选择性地保留细粒度的信息。
-
滑动窗口注意力 (Sliding Window Attention): 处理局部上下文信息。
这三个分支的输出通过一个门控机制进行聚合。为了最大化效率,NSA 还专门设计了硬件优化的 Kernel。
总结
本文提出的NSA是一种硬件对齐的稀疏注意力架构,用于高效的长上下文建模。通过在可训练架构中集成分层令牌压缩和块级令牌选择,NSA在保持全注意力性能的同时,实现了训练和推理的加速。实验结果表明,NSA在一般基准测试中的性能与全注意力基线相当,在长上下文评估中超越了其他模型的建模能力,在推理能力上也有显著提升,同时显著降低了计算延迟,实现了可观的速度提升。
NSA 的 硬件友好设计 和 训推一体化特性,使其在实际应用中更具优势,有望加速下一代 LLM 在长文本处理领域的应用落地。
这项研究无疑为稀疏注意力领域带来了新的思路和方向。未来,我们期待看到更多基于 NSA 技术的创新应用,共同推动 AI 技术的进步!


















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









