




 本文详细介绍了如何使用Hive进行数据的导入导出操作,包括从HDFS和本地文件系统加载数据到Hive表,以及将Hive表数据导出到本地路径的方法。此外,还讲解了Hive的Export和Import命令,用于完整备份和恢复包括表结构和数据在内的整个Hive表。
本文详细介绍了如何使用Hive进行数据的导入导出操作,包括从HDFS和本地文件系统加载数据到Hive表,以及将Hive表数据导出到本地路径的方法。此外,还讲解了Hive的Export和Import命令,用于完整备份和恢复包括表结构和数据在内的整个Hive表。
加载HDFS文件数据到表:
LOAD DATA INPATH "hdfs_source_path" OVERWRITE INTO TABLE tbl_nm;
加载本地文件数据到表:
LOAD DATA LOACL INPATH "loacl_source_path" OVERWRITE INTO TABLE tbl_nm;
将数据导出至本地路径下:
insert overwrite local directory '/localpath/to/stoage/' select * from tbl_nm;
将数据导出至本地路径下,可以指定存储格式与分隔符等:
insert overwrite local directory '/localpath/to/stoage/' row format delimited fields terminated by ',' select * from tbl_nm;
Export和Import:
hive自带了数据的备份和恢复命令,不止数据,包括表结构也可以一同导出:

这里的path是HDFS的路径,我这里将表导出然后删除之后再恢复:
Export:
export table tab_nm to '/hdfs_path/to/storage';

再看一下这个目录下是什么样子的:
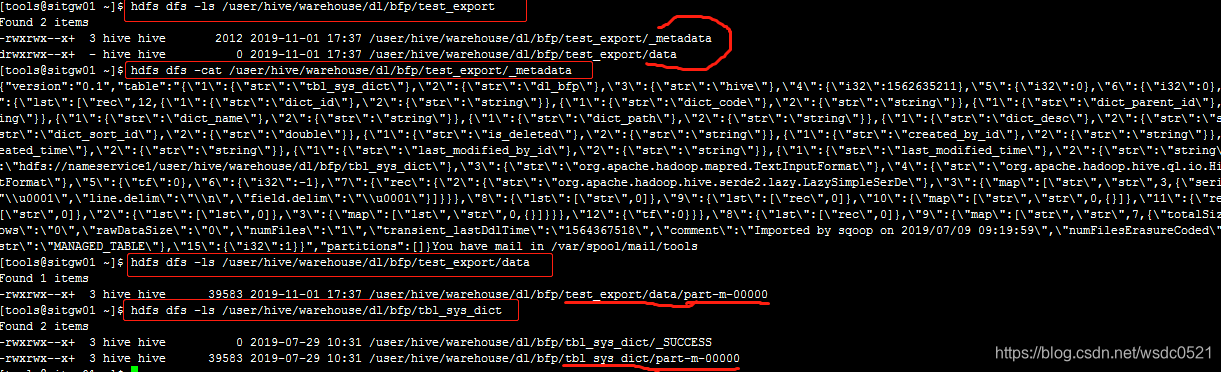
可以看到导出后的目录下,有一个_metadata元数据文件存储hive表的元数据以及一个data目录存储hive表数据。
执行export命令就是将表结构存储在_metadata文件,并且直接将hive数据文件复制到备份目录。
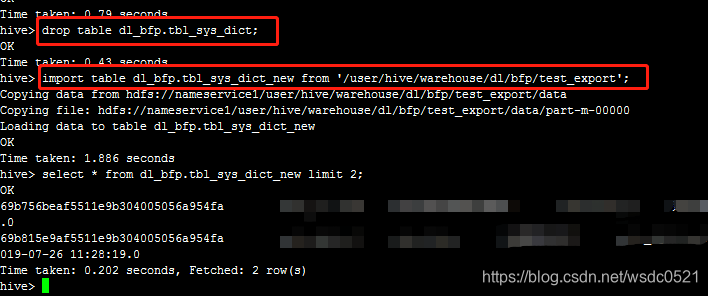
Import:
执行import命令,选择刚才导出的hdfs目录即可,注意这里的新表原来是不存在的,在import的时候会根据_metadata文件里的信息自动建表,方便做hive表的备份恢复或者迁移操作。
import table tab_nm from '/hdfs_path/to/storage';


















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











