




OV-DINO:Unified Open-Vocabulary Detection with Language-Aware Selective Fusion
王浩,任鹏珍,杰则群,董晓,冯承建,钱银龙,马琳,蒋冬梅,王耀伟,兰祥源*,梁小丹*,IEEE高级会员
- 名称:基于语言感知选择性融合的统一开放词汇检测
- paper: https://arxiv.org/pdf/2407.07844v2
- github: https://github.com/wanghao9610/OV-DINO
OV-DINO:主要问题与解决方案
阅读指南
本文是对论文《OV-DINO:Unified Open-Vocabulary Detection with Language-Aware Selective Fusion》的翻译和理解。为了帮助初读者更好地理解,我们添加了以下说明:
关键概念解释:
Open-vocabulary detection:开放词汇检测,指能够检测训练集中未出现过的类别的目标检测任务zero-shot:零样本学习,指模型在训练时未见过某些类别,但在测试时能够识别这些类别grounding:指将文本描述与图像中的区域进行对齐的任务论文创新点:
- 从两阶段训练(预训练+伪标签)改进为单阶段端到端训练
- 通过统一数据格式和语言感知融合,提高模型性能
阅读建议:
- 先阅读"主要问题与解决方案"部分,了解论文核心贡献
- 再阅读"摘要"部分,了解具体实现方法
- 最后阅读详细内容,深入理解技术细节
主要问题
开放词汇检测(Open-vocabulary detection)面临两个核心挑战:
- 数据噪声问题:现有方法通过预训练和伪标记来增强
zero-shot检测能力,但伪标记过程会引入数据噪声,影响模型性能。
理解说明:
传统方法需要先生成伪标签,这个过程容易引入错误,比如将"猫"错误地标记为"狗"。这些错误会随着训练过程传播,影响最终性能。
- 跨模态对齐问题:如何有效利用语言感知能力进行区域级跨模态融合和对齐,特别是在处理多个相同类别对象时的特征混淆问题。
理解说明:
当图像中有多个相同类别的物体时(如多只猫),传统方法难以将文本描述与具体物体对应起来,容易造成混淆。
解决方案
OV-DINO提出了一种统一的开放词汇检测方法,通过以下创新点解决上述问题:
- 统一数据集成(
UniDI)管道:- 将不同数据源(检测数据、
grounding数据和图像-文本数据)统一转换为以检测为中心的数据格式 - 实现端到端训练,消除伪标签生成的噪声
- 通过统一提示和标题框机制,协调不同数据源
- 将不同数据源(检测数据、
理解说明:
传统方法需要分别处理不同类型的数据,而UniDI将所有数据转换为统一的格式,简化了训练过程,减少了错误传播。
- 语言感知选择性融合(
LASF)模块:- 动态选择与文本相关的对象嵌入
- 通过语言感知查询选择和融合过程增强跨模态对齐
- 提供三种变体(
Later-LASF、Middle-LASF和Early-LASF)以适应不同场景
理解说明:
LASF模块能够智能地选择与文本描述最相关的图像区域,避免特征混淆。比如在描述"一只黑猫"时,能够准确选择图像中的黑猫区域。
- 以检测为中心的预训练框架:
- 采用单阶段端到端预训练范式
- 保持与
DINO类似的训练目标,确保框架简单性 - 通过分类损失、盒损失和
GIoU损失优化模型性能
理解说明:
通过简化训练过程,减少中间步骤,提高了模型的稳定性和性能。
摘要
开放词汇检测(Open-vocabulary detection)是一项具有挑战性的任务,因为它需要基于类名来检测对象,包括那些在训练中没有遇到的对象。现有方法是:通过对各种大规模数据集的预训练和伪标记,显示出强大的zero-shot检测能力。然而,这些方法遇到了两个主要挑战:
(i) 如何有效地消除伪标记带来的数据噪声;
(ii) 如何有效地利用语言感知能力进行区域级跨模态融合和对齐。
为了解决这些问题,我们提出了一种新的统一的开放词汇检测方法OV-DINO,该方法在统一的框架内对不同的大规模数据集进行语言感知选择性融合的预训练。具体来说,
- 我们引入了一个统一数据集成(
UniDI)管道,通过将不同的数据源统一为以检测为中心的数据格式,实现端到端训练并消除伪标签生成的噪声。 - 此外,我们提出了一个语言感知选择融合(
LASF)模块,通过语言感知查询选择和融合过程来增强跨模态对齐。 - 我们在流行的开放词汇检测基准上评估了所提出的
OV-DINO的性能,在COCO基准上获得了最先进的结果,在zero-shot的方式下,在LVIS基准上获得了40.1%的AP,证明了其强大的泛化能力。 - 此外,经过微调的
OV-DINO在COCO上实现了58.4%的AP,优于许多具有相同主干的现有方法。
OV-DINO的代码可在https://github.com/wanghao9610/OV-DINO获得。
索引术语:对象检测,开放词汇表,检测变压器。
OV-DINO的创新点
传统方法(两阶段):
- Stage1: 在检测/定位数据上预训练。
- Stage2: 在图像-文本数据上生成伪标-签(如通过名词提取+区域建议),但伪标签可能含噪声(如错误匹配)。
OV-DINO(单阶段):
- 统一管道:将所有数据(
Image-Text,Grounding,Detection)转换为统一的检测格式。- 端到端对齐:通过区域-文本对齐直接训练,避免两阶段噪声传播(如红色圆圈标注的伪标签噪声问题)。
1.介绍
背景知识:
传统目标检测方法:
- 如Fast RCNN、Faster R-CNN等,只能在预定义类别上进行检测
- 无法识别训练集中未出现的新类别
- 需要大量人工标注数据
开放词汇检测(OVD):
- 能够检测任何类别的对象,包括训练时未见过的类别
- 通过语言描述来指导检测过程
- 减少对人工标注的依赖
传统的目标检测方法,如Fast RCNN [4], Faster R-CNN [5], Mask R-CNN [6], DETR[7]和DINO[8],通常是在具有闭集类别的数据集上训练的,这限制了它们检测预定义类别之外的对象的能力,这对现实世界的应用是一个重要的约束。为了解决这一限制,人们提出了一个名为开放词汇检测(Open-Vocabulary Detection, OVD)的新任务,引起了学术界和工业界的极大关注。开放词汇表检测要求能够使用类名检测任何对象,甚至包括在训练期间从未遇到过的对象。OVD的发展可以追溯到Bansal等人引入的Zero-Shot Detection (ZSD),其中模型在有限的类别集上进行训练,并在新类别上进行评估。Zareian等人在ZSD的基础上,进一步将概念扩展到OVD。利用图像-文本数据衍生的视觉语义空间,从而增强了类别泛化的能力。
现有方法的问题:
数据噪声问题:
- 传统方法需要先生成伪标签,这个过程容易引入错误
- 错误会随着训练过程传播,影响最终性能
跨模态对齐问题:
- 当图像中有多个相同类别的物体时,难以将文本描述与具体物体对应
- 现有方法(如GLIP、G-DINO)在处理多物体场景时效果不佳
最近的研究[11]-[13]促进了开放世界视觉方法[1],[3],[14]-[16]的发展,使检测预定义类别之外的物体成为可能。他们通常在大规模检测和grounding数据集上预训练模型,然后为图像-文本数据生成伪标签。这带来了两个截然不同的挑战:
(i) 图像-文本数据伪标注产生的数据噪声。这是由于检测数据的词汇概念有限,使用这些数据训练的模型泛化能力较差,导致对图像-文本数据进行伪标注时预测不准确,如图1(a)所示。目前的方法如GLIP[1]、GLIPv2[2]和G-DINO[3]将检测作为grounding任务。这些方法可以在大规模检测和grounding数据集上对模型进行预训练,然后为图像-文本数据生成伪标签。然而,这两种类型的数据集所涉及的类别仍然有限。在处理图像-文本数据中的新类别时,预训练模型生成的伪标签不可避免地引入了噪声。
(ii)目标特征与类别描述之间的对齐。OVD方法的目的是根据特定的类别描述来检测相应的对象。图像中的物体往往表现出不同的特征,这对检测/对齐特定的类别描述提出了挑战。
例如,给定类别描述"一张猫的照片",该模型期望将类别描述与不同品种、大小、颜色等的猫对齐。
为了应对这一挑战,GLIP[1]引入了复杂的深度融合,将视觉特征整合到文本特征中。G-DINO[3]提出了一种基于双向交叉注意的轻量级特征增强器来改进文本嵌入表示。这些方法利用图像特征动态增强文本嵌入,以获得更好的模态对齐。然而,当图像包含多个相同类别的对象时,这些对象的视觉特征在单个文本嵌入中会被混淆,使得难以将文本嵌入与每个对象对齐。
PAGE 2

OV-DINO的创新点:
统一数据格式:
- 将所有数据源转换为统一的检测格式
- 消除伪标签生成的需求
- 简化训练过程
语言感知融合:
- 动态选择与文本相关的对象
- 提高跨模态对齐的准确性
- 解决多物体场景的混淆问题
为了解决这两个关键挑战,我们引入了一种称为OV-DINO的开放词汇检测新方法。
-
对于第一个挑战,我们提出了一个统一数据集成( Unified data integration, UniDI)管道,将不同的数据源集成到统一的以检测为中心的数据格式中,并以端到端的方式在大规模数据集上预训练模型,如图1(b)所示。为了实现这一点,我们将图像大小的边界框视为image-text data 的注释框。检测名词(detection nouns)、grounding短语(grounding phrases)和图像标题( grounding phrases)作为以检测为中心的统一的类别。这样一来,UniDI不仅消除了对图像-文本数据生成伪标签的需求,而且在预训练阶段增强了词汇概念。
-
对于第二个挑战,我们提出了一个语言感知选择性融合(LASF)模块,用于区域级跨模态融合和对齐。如图2(b)所示,LASF模块通过选择与文本相关的对象嵌入来增强嵌入表示。然后,它将与文本相关的对象嵌入注入查询中,以改进模态对齐。LASF允许模型动态地将类别描述与图像中的不同对象对齐,从而实现更准确的预测。
-
此外,我们提出了一个简单的适应DINO[8]中使用的监督训练过程,以促进开放词汇检测的单阶段端到端训练,只需要对现有框架进行最小的修改。
- image-text data数据集,将图像大小的边界框bbox视为image-text data 文本对应的注释框;(如图中橘红色框,对应着 t1)
- Grounding data数据集,标注信息中包含着text,可以被区分为各个类别。标注框数量与类别数量是不等的;(如图中橙色框,对应着 t2、t3)
- Detection data数据集,每个类都一一对应着bbox。(如图中绿色框,对应着 t4、t5…)
补充Grounding Data数据集构成的特殊性,和损失计算方式:
Grounding Data 的特殊性:
- 文本示例:“A little girl in a pink shirt holding a blue umbrella.”
- 模型处理:
- 文本拆分:通过自然语言处理提取名词(如 “girl”, “shirt”, “umbrella”)作为类别。
- 区域匹配:每个类别可能对应多个bbox(如 “umbrella” 可能对应多个部件或实例),或共享一个bbox(如 “shirt” 和 “girl” 可能共享同一区域)。
- 结果:类别数量与bbox数量不一定对齐,这与Detection Data(检测数据集)的严格一一对应不同。
Grounding Data的损失计算是一个端到端的区域-文本对齐过程,核心是通过**对比学习(Contrastive Learning)和检测任务损失(Detection Loss)**的联合优化,最大化正确区域-文本对的相似度,同时抑制错误匹配。以下是具体步骤:
- 文本编码:将文本中的名词提取并编码为词向量。
- 区域提议:生成候选区域的特征。
- 匹配:计算每个区域与文本词向量的相似度,确定正负样本。
- 损失计算:使用对比损失优化相似度,同时结合检测的回归和分类损失。
区域-文本对齐的对比损失(核心):
Grounding Data的损失核心是最大化正确区域-文本对的相似度,同时抑制错误匹配。这通过对比损失实现:
相似度计算:每个区域特征 ( v_i ) 和文本词向量 ( t_k ) 的余弦相似度 :
sik=vi⋅tk∥vi∥∥tk∥ s_{ik} = \frac{v_i \cdot t_k}{\|v_i\| \|t_k\|} sik=∥vi∥∥tk∥vi⋅tk正样本匹配:若区域 ( v_i ) 与文本中的名词 ( t_k ) 对应(通过标注或语义匹配),视为正样本对。
对比损失(InfoNCE Loss):
检测任务损失(辅助):
对于有明确标注框的Grounding Data(部分数据可能含真实bbox标注),同时优化检测任务的损失:
- 分类损失(预测类别与文本名词是否匹配)CrossEntropy
- 回归损失(预测框与真实框的位置对齐)GIoU
整体损失函数=a x 对比损失 + b x 检测损失:
为了验证该方法的有效性,在流行的开放词汇检测数据集COCO[19]和LVIS[20]上进行了zero-shot和微调设置下的大量实验。结果表明,OV-DINO在数据集和设置上都达到了最先进的性能。为了突出我们模型的特点,我们在表1中将OV-DINO与最近的方法在方法类型(type)、模态融合(modality fusion)和伪标签生成(pseudo label)方面进行了比较。

综上所述,我们的主要贡献如下:
- 我们提出了
OV-DINO,一种新颖的统一开放词汇检测方法,为实际应用提供了卓越的性能和有效性。 - 我们提出了一个统一的数据集成管道,集成了不同的数据源进行端到端预训练,以及一个语言感知选择性融合模块,以提高模型的视觉语言一致性。
- 与以前的方法相比,提出的
OV-DINO在COCO和LVIS基准上表现出显着的性能改进,在zero-shot评估中,与G-DINO相比,在COCO和LVIS上实现了+2.5% AP和+12.7% AP的相对改进。预训练的模型和代码将是开源的,以支持开放式视觉开发。

图2:语言感知选择性融合( Language-Aware Selective Fusion, LASF)的插图。我们举例说明了GDINO[3]中典型的跨情态融合和语言感知选择性融合的过程。LASF包括查询选择和查询融合,其中包括对象的选择 嵌入与文本输入相关的,并将其与 可学习的内容查询,提高预测精度。相反,G-DINO直接将查询与文本嵌入融合在一起。与G-IDNO相比,使用LASF的OVDINO实现了更高的准确率(例如,"人"为87%比63%,"网球拍"为93%比55%),突出了LASF在提高预测精度方面的有效性。
2. 相关工作
研究进展概述:
视觉语言预训练:
- 从依赖人工标注到利用大规模图像-文本对
- 从图像级理解到区域级理解
- 从简单对齐到复杂融合
开放词汇检测:
- 从闭集检测到开放词汇检测
- 从单一数据源到多数据源融合
- 从两阶段训练到端到端训练
模态信息融合:
- 从简单对齐到选择性融合
- 从全局融合到局部融合
- 从静态融合到动态融合
PAGE 3
Vision-Language Pre-Training.视觉语言训练。传统的监督视觉方法[21]-[25]往往依赖于人工标注,从而限制了模型的泛化能力。此外,定义一个全面的类别列表并为罕见的类别[14]、[26]、[27]收集足够的样本数据也是一项挑战。昂贵的标注成本限制了视觉模型在开放世界场景下的广泛应用。为了克服数据标注的局限性,视觉-语言预训练被提出,它是对自然语言处理(NLP)[28]、[29]和计算机视觉[30]领域成功的预训练-再微调方案的自然扩展和发展。
- 双流((dual-stream)方法CLIP[11]和ALIGN[12]通过跨模态对比学习对大规模图像-文本对数据(如CC12M[31]、YFCC100M[32]、Laion5B[33])进行预训练,显示了良好的
zero shot分类能力。 - 单流方法[34]-[36]通过两个独立的基于变压器的编码器直接建模视觉和文本嵌入的关系,在图像-文本[37]-[39]和VQA[40] -[42]等任务中表现良好。
- 最近,VLMo[43]、BLIP[44]和BLIPv2[45]进一步探索了一种结合单流和双流架构的混合架构,以促进更有凝聚力的视觉语言理解和生成方式。
然而,这些模型主要集中在学习整个图像的视觉表示,不能直接应用于更复杂的核心计算机视觉任务,如分割和检测,这需要细粒度的语义理解。
Open-Vocabulary检测。传统的目标检测方法[4]-[6]在监督场景中取得了成功,但在适应具有大量类的开放世界场景时面临挑战。探索获取更多语义概念的方法是开放词汇检测(OVD)任务的挑战。最近的方法,如RegionCLIP[46]、Baron[46]和ViLD[47],集中在提取复杂的语义对应和信息,以提高新类别的包容性。然而,这些方法基于预训练的CLIP模型,这限制了它们的泛化能力。此外,最近的GLIP[1]、GDINO[3]和GLIPv2[2]等方法旨在集成多个数据源以丰富模型的概念库。这些方法将对象检测作为基础任务,并为图像-文本数据生成伪标签。然而,基于grounding的统一会限制文本的输入长度,并且伪标签的生成会给模型带来噪声。同时,DetCLIP[17]提出了一种富字典的视觉概念并行预训练方案,以并行方式对模型进行预训练。DetCLIPv2[48]通过对各种数据源使用不同的损失,牺牲架构的效率,进一步努力以可扩展的预训练方法统一所有数据源。 因此,本文提出了一个统一的框架,将所有数据类型集成到目标检测数据格式中。该方法旨在为模型提供更准确的监督信息,同时克服文本长度限制和伪标签生成的必要性。该统一框架旨在增强模型的泛化性,提高开放词汇检测的性能。
Modality Information Fusion and Alignment.模态信息融合与对齐。视觉语言模型(VLM)具有两种不同的视觉和语言模态,有效地融合和对齐VLM的模态信息至关重要。在图像级VLMs中,CLIP[11]和ALIGN[12]直接将视觉和语言模态与对比损失[49]对齐,FILIP[13]进一步在细粒度尺度上对模态信息进行对齐。为了有效地对齐和融合跨模态信息,ALBEF[50]提出先对齐后融合,利用多模态编码器通过跨模态注意融合图像特征和文本特征,并以中间的图像-文本对比损失对模态进行对齐。Flamingo[51]通过GATED XATTN-DENSE层架起了纯视觉模型和纯语言模型的桥梁,在许多基准测试中取得了惊人的结果。对于细粒度的跨模态理解,图像级的模态融合和对齐不足以实现细粒度的视觉语言理解。在区域级VLMs中,RegionCLIP[46]通过区域文本预训练直接将区域表示与区域描述对齐,VLDet[52]将区域文本对齐视为一个二部匹配问题。DetCLIP[17]和DetCLIPv2[48]通过大规模预训练进一步扩展了区域-文本对齐方案,实现了出色的开放词汇检测性能。然而,这些方法主要集中在情态信息的对齐上,而忽略了区域-文本的情态融合。为了将语言信息与区域表示融合,GLIP[1]首先在编码器阶段使用交叉注意模块集成跨模态信息,然后使用区域-词对齐损失进行对齐。G-DINO[3]在解码器阶段进一步集成了模态。虽然以往的方法已经考虑了跨模态信息交互的融合与对齐,但并没有有效地平衡融合与对齐之间的关系。本文旨在平衡情态信息的融合和对齐,以增强模型在语言输入引导下准确捕获图像细节的能力。
3. 方法
本文旨在开发一个统一的预训练框架,将不同的数据源集成为适合开放词汇检测任务的标准化格式。为了实现这一目标,我们提出了一种称为OV-DINO的新模型,该模型利用不同的数据源在统一的预训练框架内提高开放词汇检测器的性能(第3.1节)。
- 为了促进跨各种数据源的统一预训练,我们开发了适用于各种数据源的统一数据集成(UniDI)管道(第3.2节)。
- 为了融合和对齐文本嵌入和特定区域视觉嵌入之间的细粒度语义,我们引入了语言感知选择性融合(LASF)模块来动态选择和融合区域级视觉语言信息(第3.3节)。
- 为了实现以检测为中心的预训练,我们还开发了一个简单的预训练框架,该框架具有简单的设计,并与闭集检测器DINO[3](第3.4节)共享类似的训练目标。
3.1 概述
PAGE 4

OV-DINO的总体框架如图3所示,其中包括一个文本编码器、一个图像编码器和一个检测解码器(a text encoder, an image encoder, and a detection decoder)。给定带有提示的图像,使用特定模板将检测类别名词或基础短语提示为标题,以创建通用文本嵌入的统一表示。随后,使用专用的图像和文本编码器提取原始图像和文本嵌入。在进行嵌入提取后,将普通图像嵌入与位置嵌入一起馈送到transformer encoder layers中,以生成精细图像嵌入。为了提高图像嵌入与文本嵌入的相关性,检测解码器采用语言感知查询选择模块来选择与文本嵌入相关联的对象嵌入。所选对象嵌入作为动态上下文嵌入,并使用语言感知查询融合模块将其与解码器中的静态可学习内容查询合并。然后将最终解码器层的输出查询用于分类投影和盒回归,以预测相应的分类分数并回归对象盒。
该模型在不同的数据源(如detection, grounding and image-text data)上进行预训练,以端到端方式将特定区域的图像嵌入与相关文本嵌入对齐。使用分类(对齐)损失和盒回归损失对其进行优化。
3.2 Unified Data Integration统一数据集成
在OV-DINO的预训练阶段,我们利用多个数据源来丰富语义概念,包detection, grounding, and image-text data。这些数据以不同的格式注释。例如,
- detection数据:类+框坐标
grounding数据:带有说明文字token positive indices+框坐标- image-text data数据:图像+文本描述
通常,不同类型的数据需要不同的处理方法,例如,为不同的数据源设计不同的损失函数,和为image-text data生成伪标签。这增加了模型优化的复杂性,使模型无法达到最佳性能。为了解决这个问题,**我们提出了统一数据集成(Unified Data Integration)在数据准备过程中将所有数据源转换为统一的以检测为中心的数据(d detection-centric data format)格式,从而能够无缝整合不同类型的数据,并协调来自不同来源的数据,以便进行端到端培训。将detection和grounding data 整合起来相对简单,因为grounding数据可以看作是一种特定类型的检测数据,每个图像都有多个grounding短语。挑战在于将大规模image-text data无缝地转换为检测数据格式。从Detic[53]中获得灵感,我们认为图像的标题描述可以被视为图像的唯一类别。此外,图像的注释框可以用作图像大小的边界框。**这种称为标题框的创新方法可以将这三种类型的数据合并为以检测为中心的数据格式。
PAGE 5
为了处理各种数据源,我们建立了一种标准格式,将数据三元组表示为(x, {bi} i =1到n, y), 其中:
- x∈RH ×W × 3表示图像输入,
- {b i∈R 4} n i = 1 表示边界框,
- y∈RC表示语言文本输入。
这里,H代表图像高度,W代表图像宽度,n代表对象实例的数量。
- 边界框b i作为detection和
grounding data的标注框, - 对于
image-text data,它们表示图像大小的边界框。
语言文本输入y根据数据类型不同而不同。
- 对于
detection data,它由预定义的类别名称组成, - 对于
grounding data,它表示实体的基础名词或短语, - 对于
image-text data,它是整个标题。
为了确保 language text embedding的一致表示,我们使用简单的模板来提示detection和grounding data的文本(e.g. , a photo of {category}.),同时保持image-text data的文本输入不变,因为它已经用作标题。这种方法被称为统一提示(Unified Prompt),它允许将所有文本输入表示为标题。
通过 unified data integration pipeline(标题框和统一提示),我们可以将来自不同数据源的训练数据结合起来,包括detection, grounding, and image-text data,对模型进行预训练。因此,它消除了在图像-文本数据上生成伪标签的需要,并在预训练阶段增强了词汇表概念。
3.3 Language-Aware Selective Fusion语言感知选择性融合

开放词汇检测模型旨在通过在区域级别将给定的文本输入与图像的语义上下文对齐来识别图像中的对象。然而,图像中的对象往往表现出不同的语义上下文,这给文本输入与这些不同的语义上下文的对齐带来了挑战。为了克服这一挑战,我们提出了一种语言感知选择性融合(Language-Aware Selective Fusion,LASF)模块。该模块动态地选择与文本相关的对象嵌入,并将它们注入查询中,以改进模态对齐。LASF的详细架构如图4(a)所示。它包括两个基本组件:语言感知查询选择language-aware query fusion,和语言感知查询融合language-aware query fusion.
language-aware query fusion语言感知查询选择组件,通过评估图像嵌入和文本嵌入之间的相似度来选择对象嵌入。通过计算多尺度图像嵌入算法和文本嵌入算法的相似度,选择最相关的proposal嵌入和object嵌入。选择的提议嵌入被用来初始化引用锚,选择的对象嵌入被转发用于后续的查询融合。语言感知的查询选择可以表述如下:
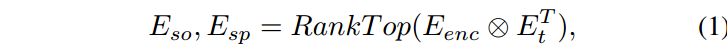
Ett表示E t的转置,⊗表示Kronecker积[54],RankTop 是一个无参数的操作,将元素按降序排列,然后选择最前面的Q个元素,Q为查询次数。
语言感知查询融合组件在保留内容查询的原始语义的同时,逐步融合语言感知对象嵌入。该组件是解码器层的重要组成部分,重复M次。每个解码器层由几个子层组成,包括自注意层、交叉注意层、门控交叉注意层、门控前馈层和前馈层。该算法首先以多尺度图像嵌入E - c、选定对象嵌入E - c和可学习内容查询Q - lc作为输入,然后动态更新内容查询Q - lc。语言感知查询融合可以表述如下:

其中上索引i表示模块索引,Φ Attn表示注意层,ΦF fw表示前馈层,α a和α b为初始化为零的可学习参数。这种初始化确保训练与原始解码器框架一致,同时逐渐将语言感知上下文合并到内容查询中。
为了便于理解,我们提出了算法1中语言感知选择性融合(LASF)的伪代码。我们根据对象嵌入的位置研究了三种LASF变体:Later-LASF、Middle-LASF和Early-LASF,如图4所示。此外,还考虑了G-DINO[3]中提出的典型跨模态融合(Typical- cmf)进行比较。
3.4 以检测为中心的预训练
PAGE 6
在本节中,我们提出了一个集成了各种数据源的单阶段端到端预训练范例。具体来说,我们利用提出的UniDI管道将不同类型的数据转换为以检测为中心的数据格式。该管道集成了来自多个来源的数据,包括detection data 、grounding data和image-text data,便于对具有广泛语义理解的检测模型进行预训练。所有数据源都遵循一致的模型前向过程和优化损失,从而以端到端方式实现以检测为中心的单阶段预训练模型 。
Model Forward。OV-DINO获取三元组数据(x, {b i} n) i= 1, Y)作为输入。图像编码器ΦI是一个图像骨干,从输入图像x∈RH ×W × 3中提取图像嵌入E i∈RP × D,其中P表示平坦化图像嵌入的空间大小,D表示嵌入的维数。文本编码器ΦT以语言文本y∈RC作为输入,得到嵌入的文本E t∈RC ×D。OV-DINO的检测头包括一个变压器编码器、一个语言感知查询选择模块和一个带语言感知查询融合模块的变压器解码器。变压器编码器Φ Enc以编码后的图像嵌入E i作为输入,输出细化后的多尺度图像嵌入E E c。语言感知查询选择模块根据文本嵌入E t选择最相关的图像嵌入作为对象嵌入E so∈RQ ×D。变压器解码器以可学习内容查询Q lc∈RQ ×D为输入,与精细化图像嵌入6交互Eenc和所选对象嵌入Eso,从而实现按照语言文本内容进行查询分类。在解码器之后,分类项目层Fc将查询嵌入投影到分类查询logits O∈RQ ×D,回归层Fr预测边界框坐标B∈RQ ×4。这里,Q和C分别表示查询和提示标题的长度。通过计算0与E t t的相似度得到分类对齐评分矩阵S∈RQ ×C。模型正演的整体过程可表述如下:

式中,E tt表示E t的转置,⊗表示克罗内克积[54],为简洁起见,省略Esp。
PAGE 7
Model Optimization模型优化。分类真值GT cls∈{0,1}Q ×C是表示预测区域与提示文本之间匹配关系的矩阵。边界框ground-truth GT box∈RQ ×4是包含相应框坐标的矩阵,它们使用[7],[8]中描述的二部匹配算法构造。使用预测的对齐分数S和ground-truth分类ground-truth GT cls计算分类损失L cls。利用回归的边界框B和边界框地面真值GT框计算回归损失L regg。回归损失既包括盒损失L box,也包括广义交联损失L GIoU。除了分类和回归损失外,还引入了去噪损失L dn[55]来增强训练过程的稳定性。该损失函数有助于提高模型在训练过程中的鲁棒性。为了保持以检测为中心的框架的简单性,预训练阶段的优化目标与DINO[8]保持一致。将整个优化目标L表示为不同损失分量的组合,可表示为:

其中,α、β和γ分别代表Lcls、Lbox和Lgiou的权重因子。Lcls is implemented by a sigmoid focal loss . Lbox is implemented by an L1 loss. Lgiou is implemented by a GIoU loss [57]. Ldn represents the sum of the denoising losses of the label and box.。
4. 实验
在本节中,我们通过在两个广泛使用的开放词汇检测基准(COCO[19]和LVIS[20])上进行大量实验来证明所提出的OV-DINO的有效性。我们在4.1节中概述了预训练数据集和评估指标,并在4.2节中深入研究了实现的细节。我们在大规模不同的数据集上预训练OV-DINO,并在COCO和LVIS基准上执行zero-shot评估。在此之后,我们在COCO数据集上微调预训练模型,并根据近集检测评估其性能,如第4.3节所述。为了证明模型设计的有效性,我们在第4.4节中进行了消融实验。此外,我们提出了定性结果与其他方法进行比较,展示了4.5节中检测结果的清晰表示。
4.1 预训练数据和评价指标

Pre-Training Data。在我们的实验中,我们使用了[1],[3],[59]中引用的几个数据集。这些数据集包括Objects365检测数据集[58]、GoldG grounding数据集[59]和Conceptual Captions图像-文本数据集[31],详见表2。我们的模型是根据GLIP[1]中概述的方法使用检测和grounding数据集进行训练的。然而,图像-文本数据集包含大量低质量的图像-文本对,如图5所示。

左侧样本的标题有效地描述了图像内容,而右样本的标题与图像内容不对齐。为了减轻图像-文本数据集中的噪声,我们使用CLIP-Large[11]从原始CC3M数据集中过滤100万图像-文本对。过滤过程首先计算300万对图像的相似度,然后根据图像-文本相似度对前100万对进行排序。数据滤波器的有效性在第4.4节的烧蚀研究中得到证实。
Evaluation Metric.评价指标。在预训练后,我们在COCO[19]和LVIS[20]基准上评估了zero-shot设置下OV-DINO的性能。此外,我们通过在COCO数据集上对预训练模型进行微调来进一步分析,以探索持续微调的有效性。根据之前的方法[1],[3],我们使用标准的平均精度(AP)指标来评估COCO的性能,并在LVIS上使用固定AP[62]指标进行公平比较。
4.2 实现细节
PAGE 8
Model Architecture.模型架构。受模型训练成本高的限制,我们专门使用Swin-T[21]作为图像编码器对模型进行预训练,与其他方法相比,该方法表现出了优越的性能。为了确保公平的比较,我们使用HuggingFace[63]的BERT-base作为文本编码器,与GLIP[1]和G-DINO[3]使用的方法一致。为了在图像-文本数据预训练过程中整合检测中的类别名称和基础数据中的名词短语,我们采用了统一的数据集成管道,在CLIP[11]中使用特定模板提示所有类别名称或名词短语。在DINO[8]之后,我们提取了8 ~ 64倍4个尺度的多尺度特征。此外,我们将提示文本的最大数量设置为150,包括图像中存在的 positive categories或短语,以及从所有其他数据源中随机选择的negative texts。对于文本嵌入提取,我们采用最大长度填充模式,并利用均值池对文本嵌入沿长度维度进行聚合。我们集成了一个线性投影层,将文本嵌入投影到与查询嵌入相同的嵌入空间中。默认情况下,我们将查询的数量设置为900,在编码器和解码器层中有6个转换层。
Model Training模型的训练。为了保持模型的简单性,我们坚持使用与原始DINO设置[8]类似的训练过程。我们采用权重衰减为1e-4的AdamW[61]优化器。总批大小为128,除文本编码器以外的所有模型参数的基本学习率为2e-4,其学习率为基础学习率的0.1倍(具体设置为1e-5)。在COCO的微调阶段,基本学习率调整为1e-5,其余超参数保持与预训练阶段相同。预训练和微调都进行了24个epoch (2x调度),使用步进学习率调度,在第16和22个epoch,学习率分别降低到基础学习率的0.1和0.01。分类损耗、盒损和GIoU损耗分配的权重分别为2.0、5.0和2.0。匹配成本组成部分的权重与损失相同,但分类成本的权重为1.0。OV-DINO预训练和微调阶段使用的超参数详见表3。

4.3 主要结果

LVIS Benchmark。在表4中,我们将我们提出的OV-DINO与LVIS基准上最新的最先进方法进行了全面比较。LVIS数据集是专门为处理长尾对象而设计的,包含1000多个类别用于评估。我们对OV-DINO的评估是在zero-shot评估设置下对LVIS MiniVal和LVIS Val数据集进行的。OV-DINO超越了以前最先进的方法,跨越各种预训练数据设置。OV-DINO在Objects365 (O365)数据集上进行了预训练 [58]获得了更好的结果,与GLIP相比,AP为+5.9%。结合grounding数据,OV-DINO表现出性能的改进,优于之前最先进的方法,与G-DINO和DetCLIP相比,AP分别为+13.8%和+5.0%。此外,当与图像-文本数据集成时,OV-DINO在公平的预训练设置下使用Swin-T图像编码器获得了最高的AP结果,在LVIS MiniVal上创造了40.1% AP的新记录,在LVIS Val上创造了32.9% AP的新记录。值得注意的是,OV-DINO仅使用图像-文本注释获得了+0.7%的AP增益,而其他方法需要伪标记才能进行实例级注释。OV-DINO以较少的参数实现了优异的性能,展示了其在检测多种类别方面的有效性和能力。
COCO Benchmark。在表5中,我们将提出的OV-DINO与COCO基准上最新的最先进方法在zero-shot和微调设置上进行了比较。在zero-shot设置中,我们的模型在各种大规模数据集上进行预训练,并直接在COCO数据集上进行评估。首先,我们在O365数据集上对模型进行预训练,并使用zero-shot方式对其进行评估,其中OV-DINO在zero-shot评估设置中优于所有先前的模型,与GLIP和G-DINO相比,AP分别为+4.6%和+2.8%。

值得注意的是,OV-DINO在与GoldG [59]数据结合时获得了最好的结果,在zero-shot转移设置下获得了50.6%的AP,优于YOLO-World +7.8%的AP和GDINO +2.5%的AP。此外,我们进一步对COCO数据集上的预训练模型进行了微调,在COCO2017验证集上仅使用Swin-T[21]作为图像编码器,获得了58.4%的AP。值得注意的是,OV-DINO只进行了24个epoch的预训练,这比其他方法的预训练时间要短。尽管如此,OV-DINO在zero shot和微调设置中都实现了最先进的性能。在COCO数据集上取得的优异性能表明OV-DINO具有巨大的实际应用潜力。有趣的是,图像-文本数据的添加给COCO带来了负面的改进,这可能是由于COCO数据集中的类别名称有限。然而,我们发现图像-文本数据对于发现更多不同的类别是必不可少的,正如在LVIS实验中所证明的那样。
4.4 消融研究
我们进行了广泛的消融研究来分析OV-DINO的有效性。为了降低完整数据的训练成本,我们从原始的O365v1[58]数据集中随机抽取10万张图像,从过滤后的CC3M[31]子集中随机抽取10万张图像,用于所有消融研究。我们将批大小设置为32个,训练计划设置为12个epoch。除非特别说明,我们在采样的O365-100K和CC-100K数据集上预训练OV-DINO,并在LVIS MiniVal数据集上评估zero-shot性能。

Unified Data Integration统一数据集成。在表6中,我们对UniDI进行了消融研究,UniDI通过统一提示和标题框来协调不同的数据源。统一提示使用特定的模板来提示类别名称,而标题框将图像-文本数据转换为以检测为中心的数据格式。对于检测,前者的AP增益为+0.6%(第1行 vs.第0行),对于图像-文本数据,前者的AP增益为+1.4%(第5行 vs.第4行),后者通过集成图像-文本数据,使AP增益为+1.4%(第4行 vs.第2行)。
Language-Aware Selective Fusion.语言感知选择性融合。在表6中,我们还对LASF进行了消融研究,其中涉及文本相关对象嵌入的动态选择和融合,以实现区域级跨模态融合和对齐。LASF的收益+0.9% AP收益(第2行 vs.第0行),证明了LASF的有效性。LASF作为OV-DINO的核心模块,能够与UniDI一起在LVIS MiniVal上不断提升性能。

LASF的变体。在表7中,我们将所提出的LASF的变体与G-DINO[3]中的Typical-CMF进行了比较。图4显示了基于对象嵌入插入位置的LASF的三种变体:Later-LASF、Middle-LASF和Early-LASF。此外,还提供了Typical-CMF的体系结构以供比较。为了验证LASF的有效性,进行了大量的实验。消融中的所有模型都使用 swing -t 作为采样的O365-100K子集上的图像编码器进行预训练。结果表明,与Typical-CMF模块相比,我们的LASF模块在捕获语言感知上下文方面更有效。此外,Later-LASF变体在LVIS MiniVal基准测试上表现出优越的zero-shot转移能力,这是我们的默认架构。

Text Embedding Pooling 文本嵌入池。在表8中,我们评估了不同的文本嵌入池化方法的影响,例如文本嵌入的均值池化和最大池化。均值池化方法计算文本嵌入长度维度上的平均值,而最大池化方法识别文本嵌入中沿标记索引的最大值。我们使用这两种池化方法在O365-100K和CC-100K上预训练模型,并观察到均值池化在应用于组合数据集时表现出优异的性能。均值池方法在捕获提示文本的综合表示方面是有效的,使其适合于UniDI。

Source of Image-Text Data图像文本数据的来源。在表9中,我们比较了不同来源的图像-文本数据的性能。我们根据CLIP的图像-文本相似度选择底部和顶部100K样本,以及随机100K样本进行比较。结果表明,排名靠前的数据源性能最好,排名靠后的数据源性能最差。这突出了图像-文本数据集中不可避免的噪声,并强调了我们的过滤操作的必要性。
4.5 定性结果

可视化的COCO。我们将预训练OV-DINO的可视化结果与其他方法的可视化结果进行了比较。图6展示了COCO数据集上零概率推断的可视化结果,其中只显示置信度得分超过0.5阈值的框预测。并与GLIP[1]和G-DINO[3]的预测结果进行了比较。第一列是真实的图像,第二列和第三列分别是GLIP-T(B)和g- dino - t3的预测,最后一列分别是OV-DINO 2的预测。从可视化中可以明显看出,OV-DINO的预测更精确,置信度更高,并且善于检测足够的对象。这些发现证明了OV-DINO在基于语言文本输入的所有目标检测中具有强大的zero-shot转移能力。

LVIS可视化。我们还展示了来自预训练OV-DINO 3的可视化结果。图7展示了LVIS数据集上的zero-shot推理可视化结果。LVIS数据集是一个拥有超过1000个类别的长尾数据集,这可以在图像中产生大量预测。为了清晰的可视化,我们只显示得分高于0.5的框预测。OV-DINO在检测各种类别方面表现出卓越的性能,从而实现高度准确的预测。
5. 讨论
PAGE 12
结论。本文提出了一种鲁棒统一开放词汇检测器OV-DINO,旨在提高开放词汇检测的性能。我们提出了一个统一的数据集成管道,以有效地集成各种数据源,使端到端训练具有统一的一致性和一致性检测框架。此外,我们还引入了语言感知的选择性融合模块来选择性地融合跨模态信息,从而提高OV-DINO的整体性能。实验结果表明,在具有挑战性的COCO和LVIS基准测试中,OV-DINO优于以前最先进的方法。
局限性。尽管OV-DINO作为一种统一的开放词汇检测方法表现出色,但认识到一些特定的挑战和局限性是至关重要的。一个潜在的限制是通过合并更大的编码器和利用更广泛的数据集来扩展OV-DINO。扩展显示了改进开放词汇表检测模型的性能和适用性的潜在前景。然而,不可避免地要承认,预训练阶段需要大量的计算资源,这可能是可扩展性的障碍。因此,有必要对训练过程进行战略性优化,以促进开放词汇任务的推进。
更广泛的影响。在我们的研究中,我们探索了以检测为中心的开放词汇检测(OVD)预训练,它不同于传统的针对各种数据源定制设计的方法。此外,我们还引入了语言感知跨模态融合和对齐的概念,这标志着传统的简单区域-概念对齐方法的不同。因此,我们的研究为OVD提供了一个创新的视角。我们期望OV-DINO将鼓励进一步探索有效利用语言感知跨情态信息进行开放词汇视觉任务的方法。



















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











