




 本文介绍利用已写好的模型实现鸢尾花数据集实战。步骤包括获取数据集、处理得到测试和训练集、用KNeighborsClassifier实现KNN算法、训练模型、预测及模型优化。重点讲述K值交叉验证优化方法,介绍了cross_val_score模块参数设置,还提及运行代码可能出现的可忽略报错。
本文介绍利用已写好的模型实现鸢尾花数据集实战。步骤包括获取数据集、处理得到测试和训练集、用KNeighborsClassifier实现KNN算法、训练模型、预测及模型优化。重点讲述K值交叉验证优化方法,介绍了cross_val_score模块参数设置,还提及运行代码可能出现的可忽略报错。
目录
第三:使用模型KNeighborsClassifier用于knn算法的实现,并自定k的值
第三:使用模型KNeighborsClassifier用于knn算法的实现,并自定k的值
我们在之前的博客中已经将KNN的底层代码完成,详情请点击关于KNN算法的基础及其底层代码实现
接下来我们要做的是利用已经写好的模型,来实现鸢尾花数据集的实战。
步骤如下:
第一:获取数据集
第二:对数据集进行处理,得到测试数据集和训练数据集
第三:使用模型KNeighborsClassifier用于knn算法的实现,并自定k的值
第四:训练模型,得到准确度
第五:预测
第六:模型的优化
步骤实施:
准备工作
在进行代码的书写之前,我们先讲述一下我们要使用的关键库sklearn,sklearn库里面有许多关键的包,对于他,后面会单独进行介绍,我们首先需要导入sklearn里面的datasets包,用于获取里面的鸢尾花数据集,以及sklearn里面的neighbors包 用于获取 KNeighborsClassifier模型。
我们还用到了一个很关键的数据分离操作模块:
train_test_split
它的一般形式为:
X_train,X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle)
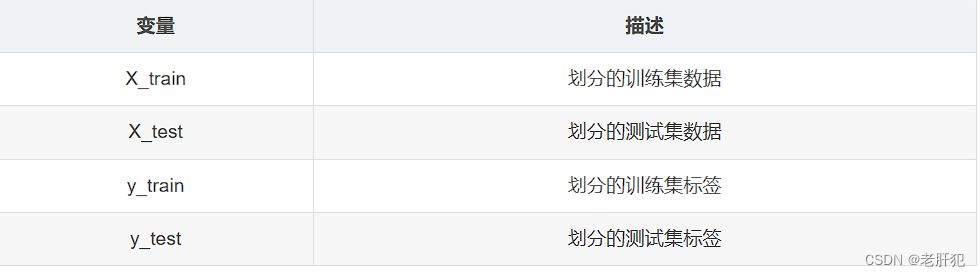
当然X_train这些都只是定义的变量名字而已,这些都可以自己去自定义的,这里就是想让大家知道它们对应的位置所对应的获取。
第一获取数据集
from sklearn import datasets #导入数据集
from sklearn.neighbors import KNeighborsClassifier as KNN #导入KNN模型
from sklearn.model_selection import train_test_split #导入数据分离包 用法:X_train,X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle)
import numpy
data=datasets.load_iris()
#print(data)
key=data.keys()
#print(key) #dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
sample=data['data']
#print(sample)
#print(sample.shape)#(150, 4) 一共150行 每行数据都有四个特征
# print(data['target'])
# [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
# 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
# 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
# 2 2]
target=data['target']
#print(data['target_names'])#['setosa' 'versicolor' 'virginica']三种类型分别对应:0,1,2
b={0:'setosa',1:'versicolor',2:'virginica'}#简单构造一个类型和标签对应的字典,为了后面使用的方便上面的大家应该都能看明白吧,定义了一个data变量用于获取鸢尾花数据集,将其输出的话是这样的:
D:\Anaconda3\python.exe D:\pythonProject\机器学习\KNN模型使用.py
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5.4, 3.7, 1.5, 0.2],
[4.8, 3.4, 1.6, 0.2],
[4.8, 3. , 1.4, 0.1],
[4.3, 3. , 1.1, 0.1],
[5.8, 4. , 1.2, 0.2],
[5.7, 4.4, 1.5, 0.4],
[5.4, 3.9, 1.3, 0.4],
[5.1, 3.5, 1.4, 0.3],
[5.7, 3.8, 1.7, 0.3],
[5.1, 3.8, 1.5, 0.3],
[5.4, 3.4, 1.7, 0.2],
[5.1, 3.7, 1.5, 0.4],
[4.6, 3.6, 1. , 0.2],
[5.1, 3.3, 1.7, 0.5],
[4.8, 3.4, 1.9, 0.2],
[5. , 3. , 1.6, 0.2],
[5. , 3.4, 1.6, 0.4],
[5.2, 3.5, 1.5, 0.2],
[5.2, 3.4, 1.4, 0.2],
[4.7, 3.2, 1.6, 0.2],
[4.8, 3.1, 1.6, 0.2],
[5.4, 3.4, 1.5, 0.4],
[5.2, 4.1, 1.5, 0.1],
[5.5, 4.2, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.2],
[5. , 3.2, 1.2, 0.2],
[5.5, 3.5, 1.3, 0.2],
[4.9, 3.6, 1.4, 0.1],
[4.4, 3. , 1.3, 0.2],
[5.1, 3.4, 1.5, 0.2],
[5. , 3.5, 1.3, 0.3],
[4.5, 2.3, 1.3, 0.3],
[4.4, 3.2, 1.3, 0.2],
[5. , 3.5, 1.6, 0.6],
[5.1, 3.8, 1.9, 0.4],
[4.8, 3. , 1.4, 0.3],
[5.1, 3.8, 1.6, 0.2],
[4.6, 3.2, 1.4, 0.2],
[5.3, 3.7, 1.5, 0.2],
[5. , 3.3, 1.4, 0.2],
[7. , 3.2, 4.7, 1.4],
[6.4, 3.2, 4.5, 1.5],
[6.9, 3.1, 4.9, 1.5],
[5.5, 2.3, 4. , 1.3],
[6.5, 2.8, 4.6, 1.5],
[5.7, 2.8, 4.5, 1.3],
[6.3, 3.3, 4.7, 1.6],
[4.9, 2.4, 3.3, 1. ],
[6.6, 2. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















&spm=1001.2101.3001.5002&articleId=136462912&d=1&t=3&u=036c7978c3de4936936e62fa50ca8723)
 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









