 AI芯片所需特性全解析
AI芯片所需特性全解析







文章目录
AI芯片需要的特性(内附大量知识点)
一、神经网络基础
对一个神经网络来说,主要包含如下几个知识点,这些是构成一个神经网络模型的基础组件。
- 神经元(Neuron):神经网络的基本组成单元,模拟生物神经元的功能,接收输入信号并产生输出,这些神经元在一个神经网络中称为模型权重。
- 激活函数(Activation Function):用于神经元输出非线性化的函数,常见的激活函数包括Sigmoid、ReLU等。
- 模型层数(Layer):神经网络由多个层次组成,包括输入层、隐藏层和输出层。隐藏层可以有多层,用于提取数据的不同特征。
- 前向传播(Forward Propagation):输入数据通过神经网络从输入层传递到最后输出层的过程,用于生成预测结果。
- 反向传播(Backpropagation):通过计算损失函数对网络参数进行调整的过程,以使网络的输出更接近预期输出。
- 损失函数(Loss Function):衡量模型预测结果与实际结果之间差异的函数,常见的损失函数包括均方误差和交叉熵。
- 优化算法(Optimization Algorithm):用于调整神经网络参数以最小化损失函数的算法,常见的优化算法包括梯度下降,自适应评估算法(Adaptive Moment Estimation)等,不同的优化算法会影响模型训练的收敛速度和能达到的性能。
AI芯片需要支持的特性
为了应对各种各样的类型的AI任务,AI芯片设计需要支持以下特性:
- 适配神经网络计算逻辑:要能支持神经网络模型特有的计算逻辑。一方面,得支持不同神经元间权重共享的逻辑。另一方面,除了卷积、全连接这类计算量极大的算子,还得支持像softmax、layernorm等访存密集型的Vector类型算子,确保各种运算在芯片上都能顺利开展。
- 实现高维张量存储与计算:在卷积等运算里,每一层都存在大量输入和输出通道。尤其在遥感等特定场景,Feature Map形状很大。这就要求芯片在有限面积内,最大程度提升计算与访存的比例。所以,设计出高效的内存管理方案至关重要,以此保障高维张量能在芯片上高效存储和计算。
- 具备灵活软件配置接口:不同领域,如计算机视觉、语音、自然语言处理,其AI模型设计形式各不相同。作为AI芯片,需要尽可能广泛地支持各个应用领域的模型,同时还要为未来可能出现的新模型结构预留支持空间。
二、模型量化和模型剪枝
模型量化
模型量化基本概念

量化相关研究热点
模型量化本质上就是将神经网络模型中权重和激活值从高比特精度(FP32)转换为低比特精度(如INT4/INT8等)的技术,用来加速模型的部署和集成,降低硬件成本,为实际应用带来更多可能性,所以模型量化依旧是未来AI落地应用的一个重要的研究方向。围绕着模型量化的研究热点可以分为如下几个方面:
- 量化方法:根据要量化的原始数据分布范围,可以将量化方法分为线性量化(如MinMax)和非线性量化(如KL散度,Log - Net算法)。
- 量化方式:量化感知训练(QAT)是一种在训练期间考虑量化的技术,旨在减少量化后模型的性能损失。
- 模型设计:二值化网络模型,也称为二值神经网络(Binary Neural Networks,BNNs),是一种将神经网络中的权重和激活值二值化为−1,+1或0,1的模型。这种二值化可以极大地减少模型的存储需求和计算成本,从而使得在资源受限的设备上进行高效的推断成为可能。
模型剪枝
模型剪枝是一种有效的模型压缩方法,通过对模型中的权重进行剔除,降低模型的复杂度,从而达到减少存储空间、计算资源和加速模型推理的目的。模型剪枝的原理是通过剔除模型中“不重要”的权重,使得模型减少参数量和计算量,同时尽量保证模型的精度不降低。具体而言,剪枝算法会评估每个权重的贡献度,根据一定的剪枝策略将较小的权重剔除,从而缩小模型体积。在剪枝过程中,需要同时考虑模型精度的损失和剪枝带来的计算效率提升,以实现最佳的模型压缩效果。
剪枝的基本概念
卷积算法定义可以分为两种,一种是对全连接层神经元之间的连接线进行剪枝,另一种是对神经元的剪枝。
根据剪枝的时机和方式,可以将模型剪枝分为以下几种类型:
- 静态剪枝:在训练结束后对模型进行剪枝,这种方法的优点是简单易行,但无法充分利用训练过程中的信息。
- 动态剪枝:在训练过程中进行剪枝,根据训练过程中的数据和误差信息动态地调整网络结构。这种方法的优点是能够在训练过程中自适应地优化模型结构,但实现起来较为复杂。
- 知识蒸馏剪枝:通过将大模型的“知识”蒸馏到小模型中,实现小模型的剪枝。这种方法需要额外的训练步骤,但可以获得较好的压缩效果。
对神经网络模型的剪枝可以描述为如下三个步骤: - 训练 Training:训练过参数化模型,得到最佳网络性能,以此为基准;
- 剪枝 Pruning:根据算法对模型剪枝,调整网络结构中通道或层数,得到剪枝后的网络结构;
- 微调 Finetune:在原数据集上进行微调,用于重新弥补因为剪枝后的稀疏模型丢失的精度性能。
AI芯片需要支持的特性
为了应对模型量化和模型剪枝,AI芯片设计需要支持以下特性:
- 配备不同位宽计算单元:为提升芯片性能,契合低比特量化研究需求,在芯片设计时,可考虑集成多种不同位宽的计算单元与存储格式。比如尝试实现fp8、int8、int4等不同精度的计算单元,用来适配不同精度要求的应用场景。比如一些对精度要求不高的图像识别场景,就可以用低精度计算单元,在保证效果的同时提升计算速度。
- 合理选择存储格式:在数据存储上,要在M - bits(像FP32)和E - bits(像TF32)格式间,以及FP16与BF16等不同精度存储格式间做出恰当选择。通过权衡,达到存储效率和计算精度的平衡。比如对于一些对存储空间要求高、对精度要求相对没那么高的应用,就可以选用存储效率高的低精度格式。
- 优化稀疏结构计算的硬件逻辑:为了更好处理稀疏结构的计算,可在硬件层面设置专门的优化逻辑,这能提升稀疏数据处理效率。同时,支持多种稀疏算法逻辑,并对硬件计算取数模块进行优化设计,进一步增强对稀疏数据的处理能力。就像NVIDIA A100在这方面就有很好的支持。例如在处理一些稀疏神经网络模型时,这种优化能让计算更快。
- 设计量化压缩算法的硬件电路:通过增加数据压缩模块设计,可以有效减轻内存带宽压力,进而提升整个系统性能。
三、轻量化网络模型

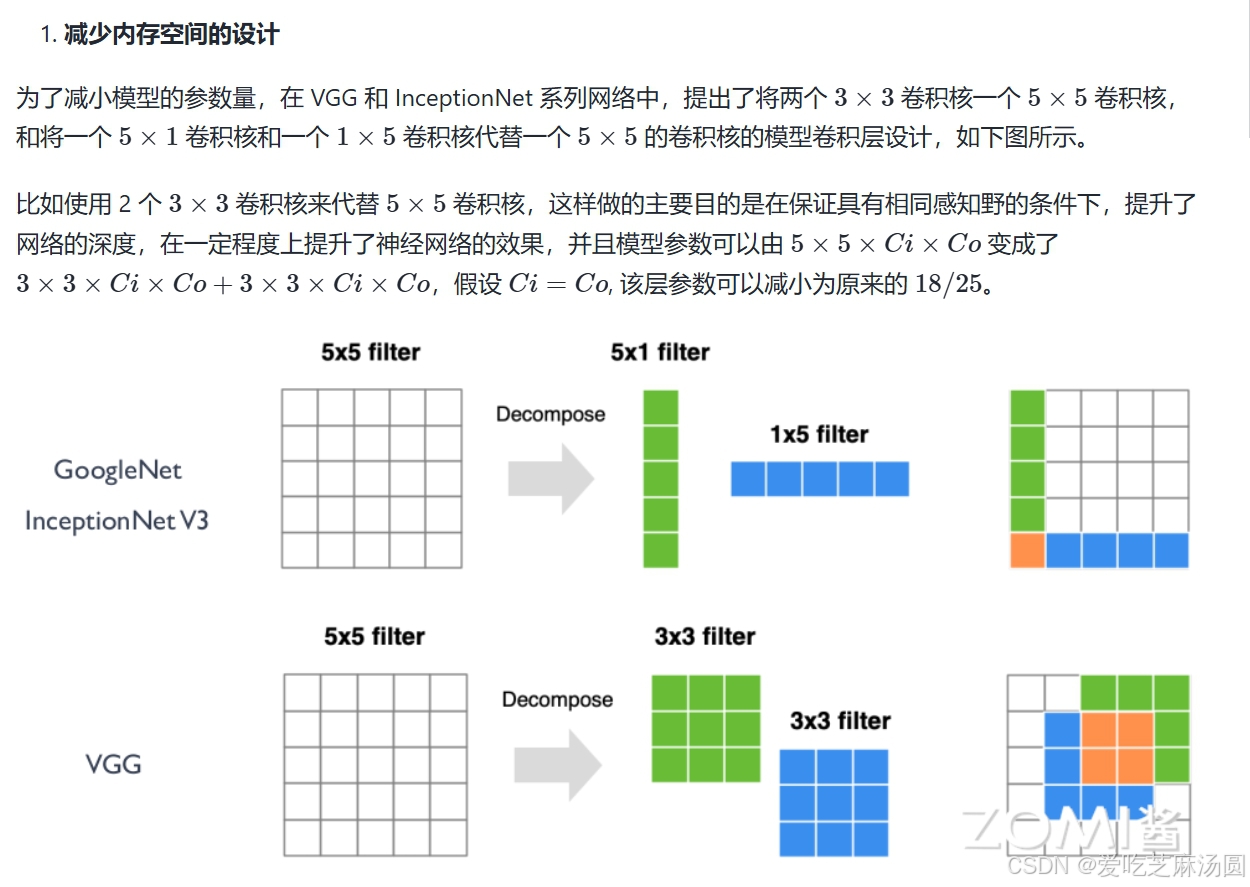
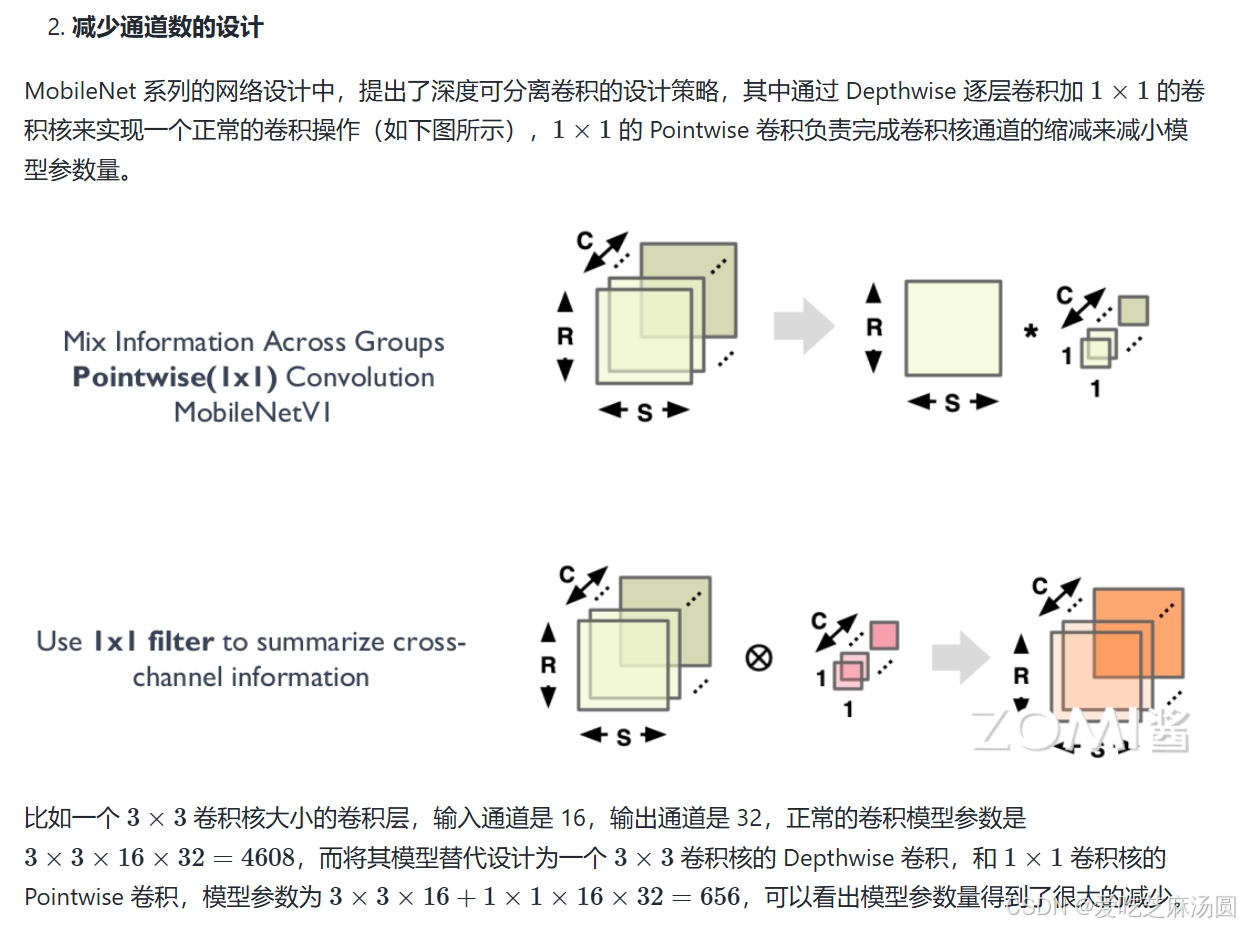
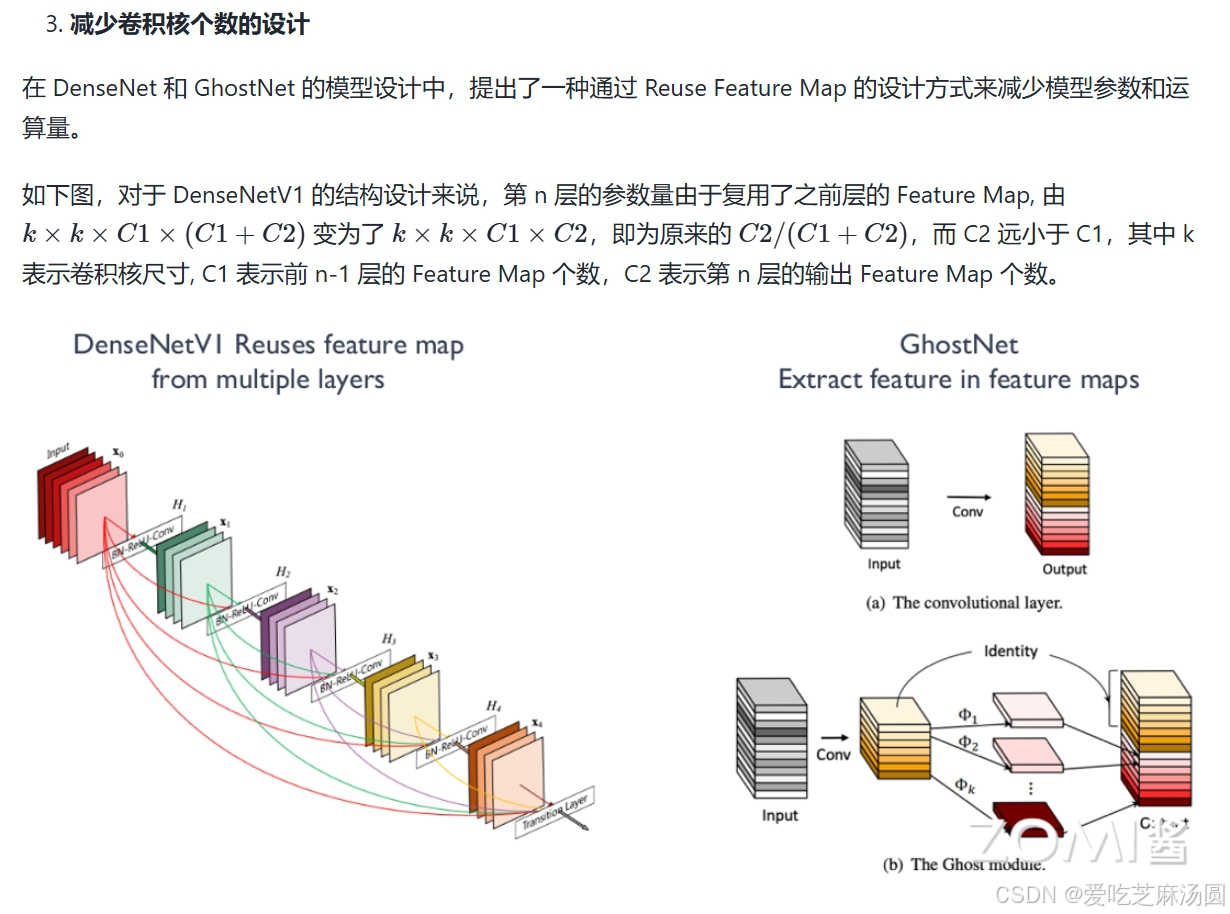
AI芯片需要支持的特性
通过上面模型网络轻量化的分类,可以看到AI模型网络中对卷积层的不同设计方法,这些都是芯片设计时候需要考虑支持的AI计算模式特性。
- 卷积核尺寸
- 小卷积核替代:用多个小卷积核代替单个大卷积核,以降低计算成本。
- 多尺寸卷积核:采用不同尺寸的卷积核来捕捉多尺度特征。
- 可变形卷积核:从固定形状转向可变形卷积核,以适应不同输入特征。
- 1×1卷积核:使用1×1卷积核构建bottleneck结构,有效减少参数和计算量。
- 卷积层运算
- Depthwise卷积:用Depthwise卷积代替标准卷积,减少参数,保持特征表达。
- Group卷积:应用分组卷积,提高计算效率,降低模型复杂度。
- Channel Shuffle:通过通道混洗(Channel Shuffle)增强特征融合,提升模型性能。
- 通道加权:实施通道加权计算,动态调整通道贡献,优化特征表示。
- 卷积层连接
- Skip Connection:采用跳跃连接(Skip Connection),使网络能够更深,同时避免梯度消失问题。
- Dense Connection:利用密集连接(Densely Connection),整合不同层的特征,增强特征融合和信息流。
四、大模型分布式
如何在AI芯片上高效的支持大模型算法是芯片设计公式必须要考虑的问题。在单芯片或者加速卡上无法提供所需的算力和内存需求的情况下,考虑大模型分布式并行技术是一个重要的研究方向。
分布式并行分为数据并行、模型并行,模型并行又分为张量并行和流水线并行。下面先介绍并行计算时候经常用到的集合通信原语,然后分别对数据并行和模型并行做一个简单的回顾。
集合通信原语
在并行计算中,通信原语是指用于在不同计算节点或设备之间进行数据传输和同步的基本操作。这些通信原语在并行计算中起着重要作用,能够实现节点间的数据传输和同步,从而实现复杂的并行算法和应用。一些常见的通信原语包括:
- All - reduce:所有节点上的数据都会被收集起来,然后进行某种操作(通常是求和或求平均),然后将结果广播回每个节点。这个操作在并行计算中常用于全局梯度更新。
- All - gather:每个节点上的数据都被广播到其他所有节点上。每个节点最终都会收到来自所有其他节点的数据集合。这个操作在并行计算中用于收集各个节点的局部数据,以进行全局聚合或分析。
- Broadcast:一台节点上的数据被广播到其他所有节点上。通常用于将模型参数或其他全局数据分发到所有节点。
- Reduce:将所有节点上的数据进行某种操作(如求和、求平均、取最大值等)后,将结果发送回指定节点。这个操作常用于在并行计算中进行局部聚合。
- Scatter:从一个节点的数据集合中将数据分发到其他节点上。通常用于将一个较大的数据集合分割成多个部分,然后分发到不同节点上进行并行处理。
- Gather:将各个节点上的数据收集到一个节点上。通常用于将多个节点上的局部数据收集到一个节点上进行汇总或分析。
数据并行技术
根据模型在设备之间的通信程度,数据并行技术可以分为DP, DDP, FSDP三种。
- Data parallelism, DP数据并行:数据并行是最简单的一种分布式并行技术,具体实施是将大规模数据集分割成多个小批量,每个批量被发送到不同的计算设备(如NPU)上并行处理。每个计算设备拥有完整的模型副本,并单独计算梯度,然后通过all_reduce通信机制在计算设备上更新模型参数,以保持模型的一致性。
- Distribution Data Parallel, DDP分布式数据并行:DDP是一种分布式训练方法,它允许模型在多个计算节点上进行并行训练,每个节点都有自己的本地模型副本和本地数据。DDP通常用于大规模的数据并行任务,其中模型参数在所有节点之间同步,但每个节点独立处理不同的数据批次。在DDP中,每个节点上的模型副本执行前向和后向传播计算,并计算梯度。然后,这些梯度在不同的节点之间进行通信和平均,以便所有节点都可以使用全局梯度来更新其本地模型参数。这种方法的优点是可以扩展到大量的节点,并且可以显著减少每个节点的内存需求,因为每个节点只需要存储整个模型的一个副本。DDP通常与AI框架(如PyTorch)一起使用,这些框架提供了对DDP的内置支持。例如,在PyTorch中,torch.nn.parallel.DistributedDataParallel模块提供了DDP实现,它可以自动处理模型和梯度的同步,以及分布式训练的通信。
- Fully Sharded Data Parallel, FSDP全分片数据并行:Fully Sharded Data Parallelism (FSDP)技术是DP和DDP技术的结合版本,可以实现更高效的模型训练和更好的横向扩展性。这种技术的核心思想是将神经网络的权重参数以及梯度信息进行分片(shard),并将这些分片分配到不同的设备或者计算节点上进行并行处理。FSDP分享所有的模型参数,梯度,和优化状态。所以在计算的相应节点需要进行参数、梯度和优化状态数据的同步通信操作。
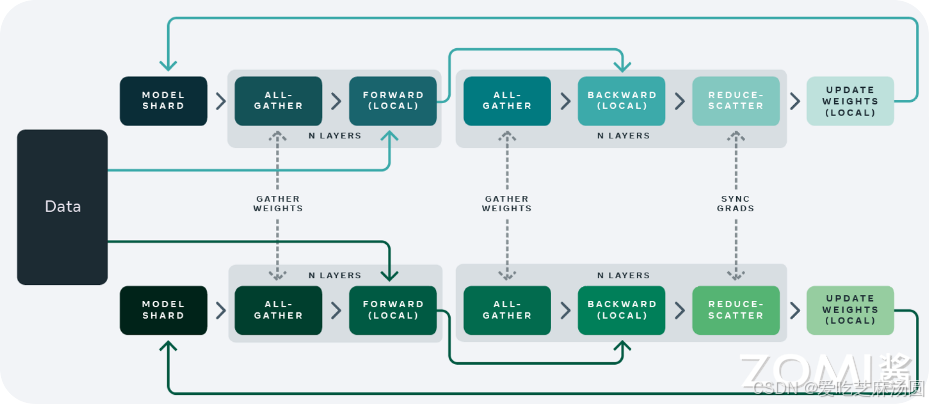
如上图是FSDP并行技术的示意图,可以看到不同的计算节点多了一些虚线链接的通信操作。
模型并行技术

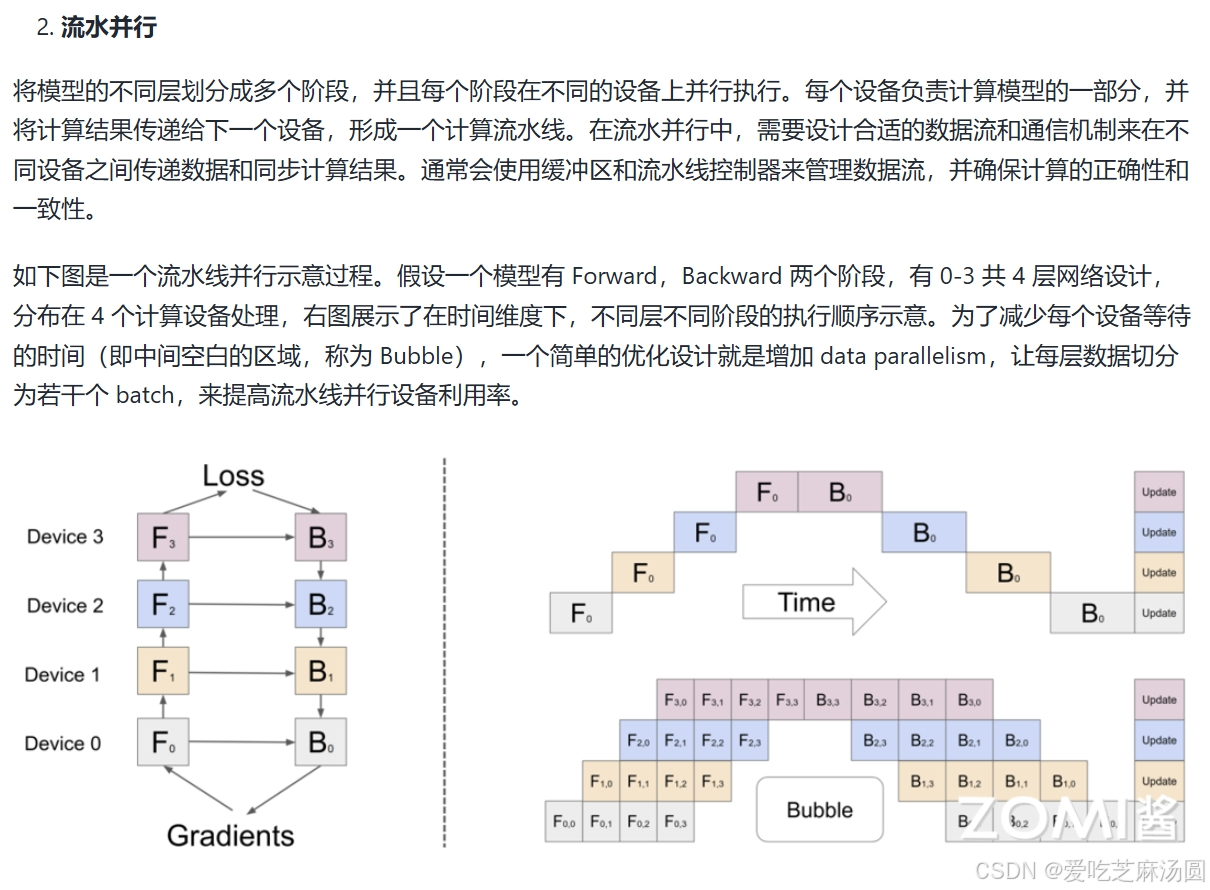
AI芯片需要支持的特性
根据上面对大模型并行技术的了解,不同的并行策略其实展示了AI计算模式是如何体现在硬件设计技术上。在芯片架构设计中可以从如下几个方面进行考虑。
- 模型并行与数据并行支持:AI芯片需要能够同时支持模型并行和数据并行两种并行策略。对于模型并行,芯片需要具备灵活的计算资源分配和通信机制,以支持模型的不同部分在多个设备上进行计算。对于数据并行,芯片需要提供高带宽、低延迟的通信和同步机制,以支持多个设备之间的数据交换和同步。
- 异构计算资源管理:AI芯片通常会包含多种计算资源,如CPU、GPU、TPU等。对于分布式并行计算,芯片需要提供统一的异构计算资源管理机制,以实现不同计算资源之间的协同工作和资源调度。
- 高效的通信与同步机制:分布式并行计算通常会涉及到大量的数据交换和同步操作。因此,AI芯片需要提供高效的通信和同步机制,以降低通信延迟和提高通信带宽,从而实现高效的分布式计算。
- 端到端的优化:AI芯片需要支持端到端的优化,包括模型设计、算法优化、系统设计等方面。通过综合考虑各个环节的优化策略,可以实现高效的大模型分布式并行计算。比如Transformer是很多大模型结构的基础组件,可以提供专用高速Transformer引擎设计。
五、总结
- AI芯片需具备对多样神经网络模型架构的灵活支持和高效执行特有计算逻辑的能力,以适应不同的应用需求。
- AI芯片应支持模型压缩算法,如量化和剪枝,以提高模型在终端部署时的推理性能,并实现软件算法与硬件执行的高效协同。
- AI芯片设计应考虑轻量化网络结构,支持更复杂的卷积运算和数据逻辑,以适应算力和带宽受限的场景。
- AI芯片需支持大模型的分布式并行策略,包括高效的片上网络接口和总线设计,以及大内存容量和高速互联带宽,以应对多芯片堆叠提高性能的需求。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









