 AI系统架构详细解析
AI系统架构详细解析







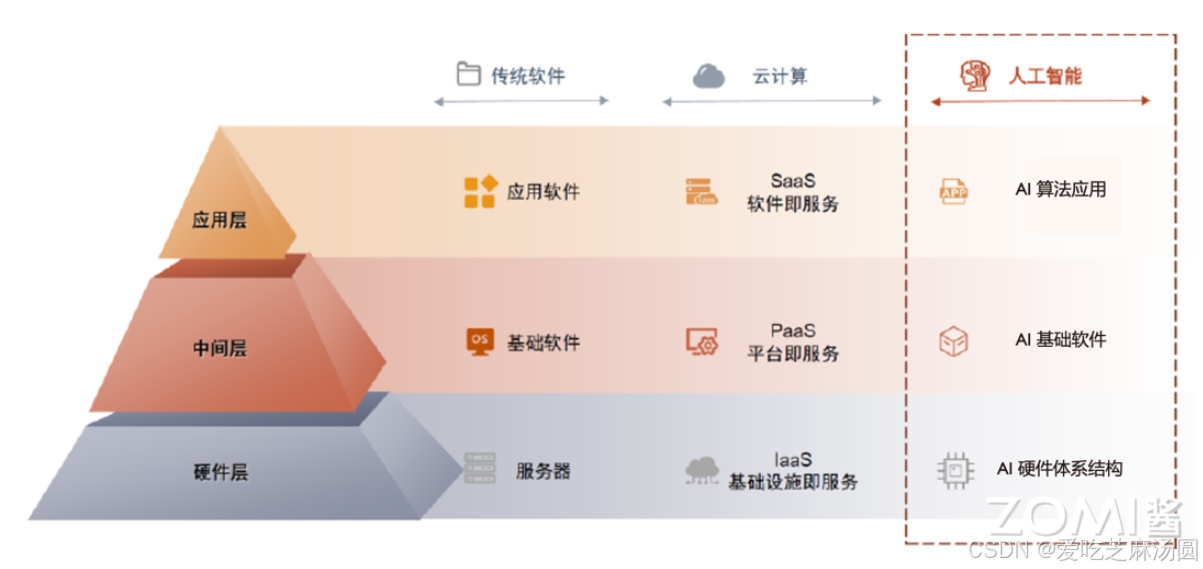
一、AI系统架构图
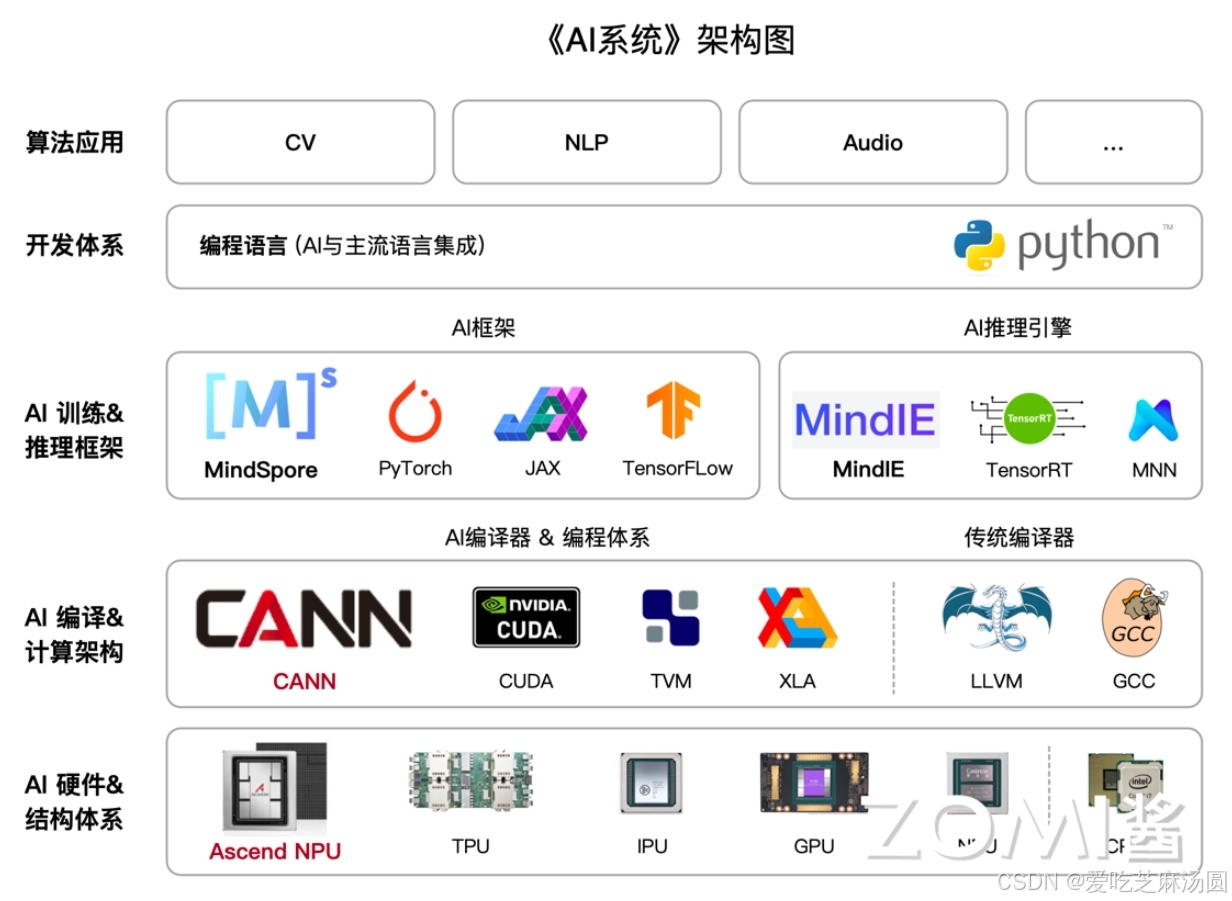

AI架构详解
应用与开发层
这一层给用户提供AI编程要用的语言、接口和工具。目标是让用户能轻松表达任务和算法,不用操心底层实现。但抽象过度会没灵活性,尤其模型迭代快时,还得兼顾灵活和可调试。这层调用底层框架接口,让开发更简单,涵盖:
- 网络模型构建:像CNN、RNN、Transformer这些网络的搭建,还有控制流、基本算子实现的API。现在常用Python调用AI框架开发模型,但控制流在语言和模型间有时会脱节。
- 模型算法实现:算法一般封装在AI框架里供用户选,有的框架也留接口让用户定制。它和网络模型构建不同,网络模型构建只管模型搭建,算法实现还包括训练、推理,以及强化学习、监督学习这些算法流程,只是算法里模型结构搭建属于网络模型部分。
- 流水线和工作流支持:这是实现模块复用、可视化编程的基础。复用和可视化能降低开发门槛,比如高性能数据加载器。
- 工具链:包括模型在不同硬件、框架间迁移,模型转换、调试、可视化、类型系统等工具。就像传统软件工程里的工具,能让AI开发跨平台,高效诊断问题、验证缺陷。
- 生命周期管理:管理数据读取、训练、推理等流程,是MLOps的基础支持。能复用模块,让底层工具精准调度,各环节解耦,更快发展。
AI框架层
AI框架不只是训练框架(如PyTorch),还包括推理框架。它负责静态程序分析、计算图构建、编译优化等。通过API获取用户模型、数据读取等想法,静态分析时自动构建前向计算图、补全反向传播图,优化计算图和算子内循环,涉及:
- 计算图构建:有静态和动态计算图构建。静态图利于全图优化,动态图利于调试,现在两者有融合趋势,比如PyTorch 2.X后的Dynamo特性支持原生静态图。
- 自动求导:高效为网络模型自动求导。因为很多算子通用,框架提前封装好求导函数,训练时自动为全模型求导,满足梯度下降等算法对权重梯度数据的需求。
- 中间表达构建:构建网络模型多层次中间表达,方便下层AI编译器生成高效后端代码。
- 如果没有 AI 框架,只将算子 for 循环抽象提供算子库(例如,cuDNN)的调用,算法工程师只能通过 NPU/GPU 厂商提供的底层 API 编写神经网络模型。例如,通过 CUDA + cuDNN 库书写卷积神经网络,需要~1000 行实现模型结构和内存管理等逻辑。同样实现 LeNet5,使用 AI 框架只需要 9 行代码,而通过 cuDNN 需要上千行代码,而且还需要精心的管理内存分配释放,拼接模型计算图,效率十分低下。
- 因此 AI 框架对算法工程师开发神经网络模型、训练模型等流程非常重要。从而可知 AI 框架一般会提供以下功能:
- 以 Python API 供读者编写网络模型计算图结构;
- 提供调用基本算子实现,大幅降低开发代码量;
- 自动化内存管理、不暴露指针和内存管理给用户;
- 实现自动微分功能,自动构建反向传播计算图;
- 调用或生成运行时优化代码,调度算子在指定设备的执行;
- 并在运行期应用并行算子,提升设备利用率等优化(动态优化)。
- AI 框架帮助开发者解决了很多 AI System 底层问题,隐藏了很多工程的实现细节,但是这些细节和底层实现又是 AI System 工程师比较关注的点。
编译与运行时
这部分负责AI模型运行前编译,以及系统运行时动态调度优化。当模型计算图部署在单卡、多卡或分布式集群,运行框架要按顺序调度算子和任务,合理分配和释放内存等资源,包括:
- 编译优化:比如算子融合,编译器按算子语义或IR定义,合并能融合的算子,降低内核启动和访存成本。还支持循环优化等传统和深度学习专属的优化策略。
- 优化器:运行时根据硬件、软件栈、数据分布等实时信息进一步优化模型,像即时优化、内省优化。
- 调度与执行:调度算子并行,执行有单线程和多线程。根据设备软硬件调度策略和模型并行机会进行调度,还能设计算子内线程调度策略。
- 硬件接口抽象:对GPU、NPU等硬件接口抽象,统一接口可复用编译优化策略,让优化方案和底层硬件解耦。
- 算子层、AI 编译器、AI 框架之间的关系如下:
- AI 框架:为用户提供编程接口,负责获取用户表达的模型、数据读取等意图,完成静态程序分析、计算图构建等工作,如自动前向计算图构建、自动求导补全反向传播计算图等,并将构建好的计算图传递给 AI 编译器。例如 PyTorch 等框架,用户通过其 API 来定义和训练神经网络模型。
- AI 编译器:以 AI 框架输出的计算图为输入,对其进行编译优化,如算子融合、循环优化等,将 AI 计算任务通过一层或多层中间表达 IR 进行翻译和优化,最后生成目标硬件上可执行的代码,使模型能在不同硬件上高效运行。
- 算子层:是 AI 框架和 AI 编译器中的基础组成部分。AI 框架中提前封装好算子的自动求导函数等,以支持模型训练等操作。AI 编译器会根据算子的语义等对适合的算子进行融合等优化,算子层的性能优化对于整个 AI 系统的性能提升至关重要。
- 三者相互协作,AI 框架为用户提供开发接口和模型构建能力,AI 编译器将框架构建的模型优化并转化为硬件可执行代码,而算子层作为基础单元,在框架和编译器中都发挥着关键作用,共同推动 AI 模型的开发、优化和在硬件上的高效执行。
与传统编译器相比,AI编译器是针对特定领域的编译器,有以下四个显著特征:
- 以Python作为主要前端语言:传统编译器一般需要Lexer/Parser来处理代码。但AI编译器不同,它常基于Python这类高级前端编程语言的AST(抽象语法树),把神经网络模型解析并构建成计算图IR。重点是保留像shape、layout这样的张量计算特征信息,有些编译器还能留存控制流信息。Python多通过动态解释器来执行。
- 采用多层IR设计:这样设计是为同时满足易用性和高性能的需求。一方面,为方便开发者,AI框架会把张量计算抽象封装成API或函数,算法开发者只需关注神经网络模型定义的逻辑及算子。另一方面,在底层优化算子性能时,可突破算子界限,从更细致的循环调度等方面,结合不同硬件特性来优化。
- 针对神经网络进行优化:AI领域把网络模型层的具体计算抽象为张量计算,所以AI编译器主要处理的数据类型就是张量。深度学习中,反向传播是重要特性,基于计算图构建的网络模型需具备自动微分功能,这也是AI编译器面向神经网络优化的体现。
- 支持DSA芯片架构:AI训练和推理对性能和时延要求极高,因此大量采用专用的AI加速芯片。AI编译器是以DSA架构的AI加速芯片为核心的编译器,这是它区别于通用编译器的一大特点 。
算子
- 算子对于神经网络模型而言,算子是网络模型中涉及到的计算函数。在 PyTorch 中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)中的卷积算法,是一个算子;全连接层(Fully-connected Layer,FC layer)中的权值求和过程,也是一个算子。
- 在神经网络中所描述的层(Layer),在 AI 框架中称为算子,或者叫做操作符(Operator);底层算子的具体实现,在 AI 编译器或者在 AI 芯片时称为 Kernel,对应具体 Kernel 执行的时候会先将其映射或转换为对应的矩阵运算(例如,通用矩阵乘 GEMM),再由其对应的矩阵运算翻译为对应的循环 Loop 指令。
- 在实际 Kernel 的计算过程中有很多有趣的问题:
- 硬件加速: 通用矩阵乘是计算机视觉和自然语言处理模型中的主要的计算方式,同时 NPU/GPU,如 TPU 脉动阵列的矩阵乘单元等其他专用人工智能芯片 ASIC 是否会针对矩阵乘作为底层支持?
- 片上内存:其中参与计算的输入、权重和输出张量能否完全放入 NPU/GPU 缓存(L1、L2、Cache)?如果不能放入则需要通过循环块(Loop Tile)编译优化进行切片。
- 局部性:循环执行的主要计算语句是否有局部性可以利用?空间局部性(缓存线内相邻的空间是否会被连续访问)以及时间局部性(同一块内存多久后还会被继续访问),这样我们可以通过预估后,尽可能的通过编译调度循环执行。
- 内存管理与扩展(Scale Out):AI 系统工程师或者 AI 编译器会提前计算每一层的输出(Output)、输入(Input)和内核(Kernel)张量大小,进而评估需要多少计算资源、内存管理策略设计,以及换入换出策略等。
- 运行时调度:当算子与算子在运行时按一定调度次序执行,框架如何进行运行时管理?
算法变换:从算法来说,当前多层循环的执行效率无疑是很低的,是否可以转换为更加易于优化和高效的矩阵计算? - 编程方式:通过哪种编程方式可以让神经网络模型的程序开发更快?如何才能减少或者降低算法工程师的开发难度,让其更加聚焦 AI 算法的创新?
# 卷积算子
# 批尺寸维度 batch_size
for n in range(batch_size):
# 输出张量通道维度 output_channel
for oc in range(output_channel):
# 输入张量通道维度 input_channel
for ic in range(input_channel):
# 输出张量高度维度 out_height
for h in range(out_height):
# 输出张量宽度维度 out_width
for w in range(out_width):
# 卷积核高度维度 filter_height
for fh in range(filter_height):
# 卷积核宽度维度 filter_width
for fw in range(filter_width):
# 乘加(Multiply Add)运算
output[h, w, oc] += input[h + fw, w + fh, ic]\
* kernel[fw, fh, c, oc]
硬件体系结构与AI芯片
这部分负责程序真正执行、互联和加速。更广泛来说,平台要给作业间提供调度、资源分配和环境隔离,包括:
- 资源池化管理与调度:把服务器资源池化,通过调度器结合深度学习作业和异构硬件拓扑高效调度,对云资源管理很重要。
- 可扩展的网络栈:像RDMA、InifiBand、NVLink等,提供高效加速器间互联,更高网络带宽、灵活通信原语和高效通信聚合算法(如AllReduce算法)。

















 4050
4050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









