




模型精度和模型量化
一、数据的存储方式
- 符号位 S(Sign):0 代表正数,1 代表负数。
- 指数位 E(Exponent):用于存储科学计数法中的指数部分,决定了数据的范围。
- 尾数位 M(Mantissa):用于存储尾数(小数)部分,决定了数据的精度。
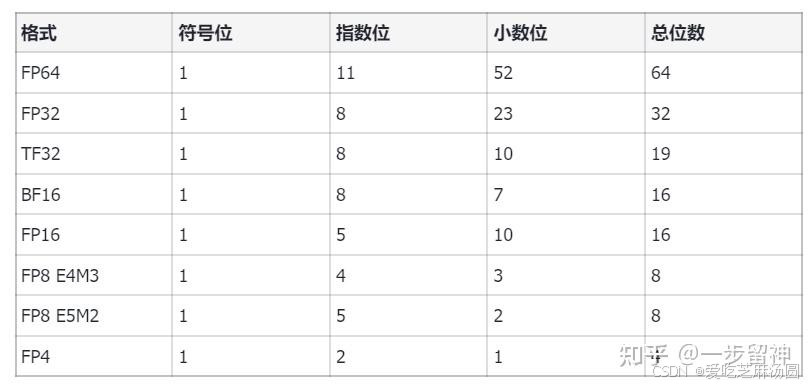
二、模型常用参数精度
- INT4:量化精度。
- INT8:量化精度。
- FP8 E4M3:八位精度,四位指数位,3 位小数位。
- FP8 E5M2:八位精度,五位指数位,2 位小数位,精度高于 E4M3。
- FP16:半精度,一位符号,五位指数,十位小数位。
- BF16:半精度一位符号,八位指数,七位小数位,精度高于 FP16。
- FP32:单精度。
- TF32:单精度。
- FP64:双精度。
图片来源:知乎@一步留神
三、不同数据类型的使用场景
- 不同任务使用不同的数据类型
- 例 1:相比于目标检测,分类任务对于数据类型就没有那么敏感了,可能使用 FP16 和 Int8 获得的精度并没有差多少,但使用 Int8 能够显著提升训练和推理性能。
- 例 2:由于图像往往是 Int8 格式,因此在 CV 的推理任务中以 Int8 为主;但在 NLP 任务中应以 FP16 为主。
- 训练和推理的不同
- FP32 往往只是作为精度基线 (baseline),比如要求使用 FP16 获得的精度达到 FP32 baseline 的 99% 以上。但通常不会使用 FP32 进行训练,尤其对于大模型来说。
- 训练往往使用 FP16, BF16 和 TF32,以降低内存占用,缩写训练时间,降低训练资源(较少耗电)。
- 推理 CV 任务以 Int8 为主,NLP 任务以 FP16 为主,大模型可以使用 Int8/FP16 混合推理。
四、数据转换工具
在实际应用中,经常需要使用一些工具或库来实现浮点数和定点数之间的转换。以下是一些常用的工具和库:
- QTools:是一个用于定点数运算的工具,提供了定点数与浮点数之间的转换功能。它支持多种定点数格式,如 Q15、Q16、Q31 等。
- Matlab:是一个强大的数学计算工具,支持定点数和浮点数之间的转换。通过 Matlab 的定点数工具箱(Fixed-Point Toolbox),可以方便地进行定点数与浮点数之间的转换。
- Python:在 Python 中,可以使用一些库如 numpy 和 scipy 来进行定点数和浮点数之间的转换。例如,numpy 提供了 int16、int32、float32 等数据类型,可以方便地进行转换。
五、数据转换的注意事项
- 精度损失:在浮点数到定点数的转换过程中,可能会出现精度损失。这是因为定点数的精度有限,无法表示所有浮点数的精度。在转换过程中,需要根据具体需求选择合适的定点数格式,以尽可能减少精度损失。
- 溢出和下溢:在定点数到浮点数的转换过程中,可能会出现溢出或下溢的情况。溢出是指定点数的值超出了浮点数的表示范围,导致结果不正确。下溢是指定点数的值太小,无法被浮点数正确表示,导致结果为零。
- 四舍五入和截断:在浮点数到定点数的转换过程中,通常需要进行四舍五入或截断操作。四舍五入可以减少精度损失,但可能会增加计算复杂度。截断操作简单,但可能会导致更大的精度损失。
六、模型量化的应用
- 模型训练加速:在模型训练过程中,使用低精度数据类型如 FP16 或 FP8 可以显著加快训练速度。例如,NVIDIA 的 Hopper 架构 GPU 支持 FP8 精度的 Tensor Core 计算,与传统的 FP32 训练相比,FP8 训练速度可以提升 2-3 倍。这种加速对于大规模模型的训练尤为重要,因为它可以大幅减少训练时间和计算资源的消耗。以大模型训练为例,Inflection AI 的 Inflection2 模型采用了 FP8 混合精度在 5000 个 NVIDIA Hopper 架构 GPU 上进行训练,累计浮点运算次数高达约 1025 FLOPs。与同属训练计算类别的 Google 旗舰模型 PaLM 2 相比,在多项标准人工智能性能基准测试中,Inflection-2 展现出了卓越的性能。
- 模型推理优化:在模型推理阶段,量化可以显著降低模型的存储需求和计算复杂度。例如,将 FP32 模型量化为 INT8,存储需求可以减少 75%,推理速度可以提升数倍。这对于在边缘设备或移动设备上部署模型尤为重要,因为这些设备的计算资源和存储空间通常有限。例如,Google 与 NVIDIA 团队合作,将 TensorRT-LLM 应用于 Gemma 模型,并结合 FP8 技术进行了推理加速。使用 Hopper GPU 进行推理时,FP8 对比 FP16 在吞吐量上能够带来 3 倍以上的收益。
- 模型压缩与部署:量化还可以用于模型的压缩和部署。通过将高精度模型量化为低精度模型,可以减少模型的大小,从而更容易将模型部署到资源受限的环境中。例如,零一万物基于 NVIDIA 软硬结合的技术栈,完成了在大模型的 FP8 训练和验证。其大模型的训练吞吐相对 BF16 得到了 1.3 倍的性能提升。量化后的模型不仅在存储和计算上具有优势,还可以通过特定的硬件加速来进一步提升性能。例如,NVIDIA 的 Transformer Engine 已经集成到 PyTorch、JAX、PaddlePaddle 等基础深度学习框架中,为量化模型的推理提供了高效的硬件支持。



















 4334
4334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









