



本文是学习过程中,研究和学习别的博主以及相关视频之后,根据自己对整个过程的梳理以及理解
1、什么是量化
模型量化是一种将深度学习模型中的浮点数权重和激活值转为低精度数值(FP32--->FP16、FP32--->int8等)的技术,同时尽可能减少量化后模型推理的误差。量化的好处有以下几点:
(1)减少模型的存储空间和显存的占用
(2)减少显存和TensorCore之间的数据传输量,从而加快模型推理时间
(3)显卡对整数运算速度快于浮点型数据,从而加快模型推理时间
正如上述所说,模型量化会对模型的精度和准确度产生一定的影响,因为量化后的模型可能无法完全保留原始模型中的所有信息和特征。因此,在进行模型量化时需要进行适当的权衡和优化。
像平时的YOLOv5、Vgg默认都是FP32精度

2、前提
量化的两个重要过程:一个是量化(Quantize),另一个是反量化(Dequantize)
- 量化就是将浮点数量化为整型数(FP32--->INT8)
- 反量化就是将整型数转换为浮点数(INT8--->FP32)
3、如何去量化
3.1 量化过程中的计算公式如下
3.2 有一个浮点数组[-0.61,-0.52,1.62],按照上述流程使用int8方式进行描述,过程如下:
第一步:计算数组共同的Scale
Scale = (float_max - float_min) / (quant_max - quant_min)
= (1.62-(-0.61)) / (127 - (-128)) = 0.0087109
int8的取值范围是【-128,127】
第二步:量化
-0.61 / 0.0087109 = -70.0272072
-0.52 / 0.0087109 = -59.6953242 ==> [-70,-59,185] 取整
1.62 / 0.0087109 = 185.9738947
第三步:截断
[-70,-59,185] ==> [-70,-59,127]
第四步:反量化
[-0.609763,-0.5139431,1.1062843]
可以看到截断的数值最后反量化与原数值相差较大(1.62与1.11062843)
3.3 代码实现
import numpy as np
def scale_cal(x, quant):
scale = (x.max() - x.min()) / (quant.max() - quant.min())
return scale
def quant_float_data(x, scale, quant):
xq = saturete(np.round(x/scale), quant.max(), quant.min())
return xq
def saturete(x, int_max, int_min):
return np.clip(x, int_min, int_max)
def dequant_data(xq, scale):
x = ((xq)*scale).astype('float32')
return x
if __name__ == '__main__':
input_data = np.array([-0.61, -0.52, 1.62])
quant_int8 = np.array([-128, 127])
print(f"输入浮点数据为:{input_data}")
scale = scale_cal(input_data, quant_int8)
print(f"量化缩放因子为:{scale}")
quant_input_data = quant_float_data(input_data, scale, quant_int8)
print(f"量化后结果为: {np.round(input_data / scale)}")
print(f"量化截断后的整型数据为: {quant_input_data}")
data_dequant_float = dequant_data(quant_input_data, scale)
print(f"反量化结果为: {data_dequant_float}")
print(f"量化误差为: {data_dequant_float - input_data}")
结果如下
输入浮点数据为:[-0.61 -0.52 1.62]
量化缩放因子为:0.008745098039215686
量化后结果为: [-70. -59. 185.]
量化截断后的整型数据为: [-70. -59. 127.]
反量化结果为: [-0.61215687 -0.5159608 1.1106274 ]
量化误差为: [-0.00215687 0.00403919 -0.50937259]4、解决办法
4.1 非对称量化
通过引入一个偏移量Z可以解决上面的问题,具体公式如下:
代码实现如下:
def scale_z_cal(x, quant):
scale = (x.max() - x.min()) / (quant.max() - quant.min())
z = quant.max() - np.round(x.max() / scale)
return scale, z
def quant_float_data(x, scale, quant):
xq = saturete(np.round(x/scale + z), quant.max(), quant.min())
return xq
def saturete(x, int_max, int_min):
return np.clip(x, int_min, int_max)
def dequant_data(xq, scale, z):
x = ((xq - z)*scale).astype('float32')
return x
if __name__ == '__main__':
input_data = np.array([-0.61, -0.52, 1.62])
quant_int8 = np.array([-128, 127])
print(f"输入浮点数据为:{input_data}")
scale, z = scale_z_cal(input_data, quant_int8)
print(f"量化缩放因子为:{scale}")
print(f"量化偏移量为:{z}")
quant_input_data = quant_float_data(input_data, scale, quant_int8)
print(f"量化后的整型数据为: {quant_input_data}")
data_dequant_float = dequant_data(quant_input_data, scale, z)
print(f"反量化结果为: {data_dequant_float}")
print(f"量化误差为: {data_dequant_float - input_data}")输出结果如下:
输入浮点数据为:[-0.61 -0.52 1.62]
量化缩放因子为:0.008745098039215686
量化偏移量为:-58.0
量化后的整型数据为: [-128. -117. 127.]
反量化结果为: [-0.61215687 -0.5159608 1.6178432 ]
量化误差为: [-0.00215687 0.00403919 -0.00215685]上述方法通过引入一个偏移量Z,使得量化后的数值在更小的范围内,进而减小量化误差。同时,偏移量Z的计算使得量化后的最大值Rmax落在了Qmax上,保证了最大值的精度。
4.2 对称量化
通过在原始数组中虚拟添加一个值,该值的大小为原始数组中绝对值最大的数的相反数,例如上述数组[-0.61,-0.52,1.62],添加的数值为-1.62,同时考虑到对称,将其量化到【-127,127】(实际工程量化用的时候不会考虑-128)
具体公式如下:
代码实现如下:
import numpy as np
def scale_cal(x, quant):
max_val = np.max(np.abs(x))
scale = max_val / quant.max()
return scale
def quant_float_data(x, scale, quant):
xq = saturete(np.round(x/scale), quant.max(), quant.min())
return xq
def saturete(x, int_max, int_min):
return np.clip(x, int_min, int_max)
def dequant_data(xq, scale):
x = (xq * scale).astype('float32')
return x
if __name__ == '__main__':
input_data = np.array([-0.61, -0.52, 1.62])
quant_int8 = np.array([-127, 127])
print(f"输入浮点数据为:{input_data}")
scale = scale_cal(input_data, quant_int8)
print(f"量化缩放因子为:{scale}")
quant_input_data = quant_float_data(input_data, scale, quant_int8)
print(f"量化后的整型数据为: {quant_input_data}")
data_dequant_float = dequant_data(quant_input_data, scale)
print(f"反量化结果为: {data_dequant_float}")
print(f"量化误差为: {data_dequant_float - input_data}")
输出结果如下:
输入浮点数据为:[-0.61 -0.52 1.62]
量化缩放因子为:0.012755905511811024
量化后的整型数据为: [-48. -41. 127.]
反量化结果为: [-0.61228347 -0.52299213 1.62 ]
量化误差为: [-2.28346825e-03 -2.99213409e-03 4.76837148e-09]
理论上,1.62量化误差应该是0,但是代码结果不为0,这是由于浮点数精度问题导致,误差数量级在10e-8量级,可以接受
其实我觉得对称量化是非对称量化的一种特殊情况,即偏移量Z=0
4.3 对称量化 VS 非对称量化
对称量化的优点:
- 没有偏移量,可以降低计算量
- 分布在正负半轴的权值数值均可被充分利用,具有更高的利用率;
- 对于深度学习模型,可以使用int8类型的乘法指令进行计算,加快运算速度;
- 能够有效的缓解权值分布在不同范围内的问题。
对称量化的缺点:
- 对于数据分布在0点附近的情况,量化的位数可能不够;
- 数据分布的范围过于分散,如果缺乏优秀的统计方法和规律,会导致量化效果不佳。
非对称量化的优点:
- 通过偏移量可以保证量化数据分布在非负数范围内,可以使得分辨率更高;
- 适合数据分布范围比较集中的情况。
非对称量化的缺点:
- 对于偏移量的计算需要额外的存储空间,增加了内存占用;
- 偏移量计算需要加减运算,会增加运算的复杂度;
- 对于深度学习模型,要使用int8类型的乘法指令进行计算,需要进行额外的偏置操作,增加了运算量。
现在考虑一个情况,比如有1000个点,其中999个点分布在【-1,1】之间,有个离散点在100位置处,此时进行量化的时候Scale会被调整的很大,从而导致量化误差增大。因此在量化时,要谨慎处理数据中的极端值(噪声点)
5、动态范围的计算
说直白一点,动态范围是指输入数据中数值的范围,计算动态范围就是为了获得最佳的Scale。
对应到上面的量化方式中,在对称量化中,通常采用的是输入数据的绝对值的最大值作为动态范围的计算方法,
;而在非对称量化中,通常采用最小值和最大值的差作为动态范围的计算方法,
常用的动态范围计算方法包括:
- Max方法:在对称量化中直接取输入数据中的绝对值的最大值作为量化的最大值。这种方法简单易用,但容易受到噪声等异常数据的影响,导致动态范围不准确(对应到上面考虑的一个情况)。
- Histogram方法:统计输入数据的直方图,根据先验知识获取某个范围内的数据,从而获得对称量化的最大值。这种方法可以减少噪声对动态范围的影响,但需要对直方图进行统计,计算复杂度较高。
- Entropy方法:将输入数据的概率密度函数近似为一个高斯分布,以最小化熵作为选择动态范围的准则。这种方法也可以在一定程度上减少噪声对动态范围的影响,但需要对概率密度函数进行拟合和计算熵,计算复杂度较高。
对称量化和非对称量化的选择与动态范围的计算方法有一定的关系。对称量化要求量化的最大值和最小值的绝对值相等,可以采用Max方法或Histogram方法进行计算。非对称量化则可以采用Entropy方法进行计算,以最小化量化后的误差。
5.1 Histogram方法
直方图(Histogram)是统计学中常用的一种图形,它将数据按照数值分组并统计每组数据的出现频率,然后将频率用柱状图的方式表示出来。histogram方法为什么能克服Max方法中离散点即噪声干扰问题呢?主要在于直方图统计了数据出现的频率,它可以将数据按照一定的区间进行离散化处理,并计算每个区间中数据点的数量。这种方法相对于Max方法来说,能够更好地反映数据的分布情况,从而更准确地评估数据的动态范围。
假设数据服从正态分布,即离散点在两边,我们可以通过从两边向中间靠拢的方法,去除离散点,类似于双指针的方法,算法具体流程如下:
- 首先,统计输入数据的直方图和范围
- 然后定义左指针和右指针分别指向直方图的左边界和右边界
- 计算当前双指针之间的直方图覆盖率,如果小于等于设定的覆盖率阈值,则返回此刻的左指针指向的直方图值,如果不满足,则需要调整双指针的值,向中间靠拢
- 如果当前左指针所指向的直方图值大于右指针所指向的直方图值,则右指针左移,否则左指针右移
- 循环,直到双指针覆盖的区域满足要求
代码实现如下:
import numpy as np
def scale_cal(x):
max_val = np.max(np.abs(x))
return max_val / 127
def histogram_range(x):
# np.histogram是用于生成直方图的函数
# 第一个参数为a待处理的数据,可以是一维或者多维数组,多维数组将会被展开成一维数组
# 第二个参数bins表示数据分成的区间数
# 第一个返回值为长度为bins的一维数组,表示每个区间中数据点的数量或者归一化后的概率密度值。
# 第二个返回值为长度为bins + 1的一维数组,表示每个区间的边界。
hist, range = np.histogram(x, 100)
total = len(x)
left = 0
right = len(hist) - 1
limit = 0.99
while True:
cover_percent = hist[left:right].sum() / total
if cover_percent <= limit:
break
if hist[left] > hist[right]:
right -= 1
else:
left += 1
left_val = range[left]
right_val = range[right]
dynamic_range = max(abs(left_val), abs(right_val))
return dynamic_range / 127
if __name__ == "__main__":
np.random.seed(1)
data_float32 = np.random.randn(1000).astype('float32')
scale = scale_cal(data_float32)
scale2 = histogram_range(data_float32)
print(f"Max方法的缩放因子 = {scale} 直方图方法的缩放因子 = {scale2}")问题:Histogram方法虽然能够解决Max方法中的离散点噪声问题,但是使用数据直方图进行动态范围的计算,要求数据能够比较均匀地覆盖到整个动态范围内。如果数据服从类似正态分布,则直方图的结果具有参考价值,因为此时的数据覆盖动态范围的概率较高。但如果数据分布极不均匀或出现大量离散群,则直方图计算的结果可能并不准确。
5.2 Entropy方法
Entorpy方法是一种基于概率分布的动态范围计算方法,通过计算概率分布之间的KL散度来选择合适的动态范围
在概论或信息论中,KL散度又称为相对熵,是描述两个概率分布P和Q的一种方法,计算公式如下
KL散度值越小,代表两种分布越相似,量化误差越小;反之,KL散度值越大,代表两种分布差异越大,量化误差越大。
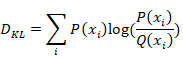
下面通过随机生成两组随机数据,通过使用Entropy方法来估计数据的动态范围,算法流程如下:
- 首先定义一个随机数组x,然后计算其概率分布
- 然后重复随机生成y,计算其概率分布,接着计算与输入x的概率分布之间的KL散度,如果小于阈值kl_threshod,则认为当前的概率分布y最优,
- 否则继续生成一个新的随机概率分布y,重复KL散度计算,直到找到满足条件的最优概率分布
- 最后返回找到的最优概率分布y,并可视化原始数据分布x和最优概率分布y的差异
具体代码如下:
import numpy as np
import matplotlib.pyplot as plt
def cal_kl(p, q):
KL = 0
for i in range(len(p)):
KL += p[i] * np.log(p[i]/q[i])
return KL
def kl_test(x, kl_threshod = 0.01):
yout = []
y_out = []
while True:
y = [np.random.uniform(1, size+1) for i in range(size)]
y_ = y /np.sum(y)
kl_result = cal_kl(x, y_)
if kl_result < kl_threshod:
print(kl_result)
yout = y
y_out = y_
plt.plot(x)
plt.plot(y_)
break
return y_out,yout
if __name__ == "__main__":
np.random.seed(1)
size = 10
xout = [np.random.uniform(1, size+1) for i in range(size)]
x_out = xout/ np.sum(xout)
y_out,yout = kl_test(x_out, kl_threshod = 0.01)
plt.show()
print(f"概率分布情况\nx_out: {x_out}, y_out: {y_out}")
print(f"具体值\nxout: {xout}, yout: {yout}")
最后得到x和y的分布情况如下
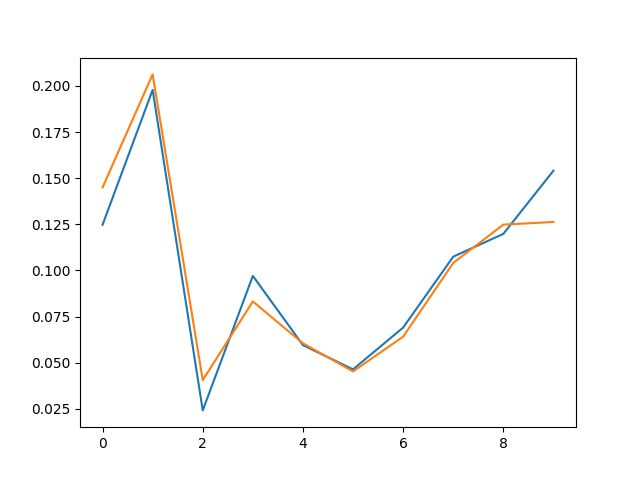
5.3 实际应用
上面在求取KL散度有一个大前提,那就是通过直方图统计的P和Q分布的bin要保持一致,而实际情况又不是这样的。
5.3.1 第一种情况
比如说现实情况下假设P是FP32的概率分布,而Q是INT8的概率分布,由于FP32的数据量大,我们可以划分很细(如2048个bin),而INT8的bin数量固定,二者bin并不一致。
下面是TensorRT的解决方案,通过下面的示例说明:
假设我们的输入为[1,0,2,3,5,3,1,7]为8个bin,但Q只能用4个bin来表达,怎么操作才能让Q拥有和P一样的bin来描述呢?
- 1.数据划分:按照合并后的bin将输入划分为4份即[1,0],[2,3],[5,3],[1,7]
- 2.对划分的数据求和:sum = [1],[5],[8],[8]
- 3.统计划分的数据的非0个数:count = [1],[2],[2],[2]
- 4.求取平均:avg = sum / count = [1],[2.5],[4],[4]
- 5.反映射:非零区域用对应的均值区域填充即[1,0],[1,1],[1,1],[1,1] * [1],[2.5],[4],[4] = [1,0,2.5,2.5,4,4,4,4]
代码实现如下:
import numpy as np
import matplotlib.pyplot as plt
def smooth_data(p, eps = 0.0001):
is_zeros = (p==0).astype(np.float32)
is_nonzeros = (p!=0).astype(np.float32)
n_zeros = is_zeros.sum()
n_nonzeros = p.size - n_zeros
eps1 = eps*n_zeros/n_nonzeros
hist = p.astype(np.float32)
hist += eps*is_zeros + (-eps1)*is_nonzeros
return hist
def cal_kl(p, q):
KL = 0.
for i in range(len(p)):
KL += p[i]* np.log(p[i]/(q[i]))
return KL
def kl_test(x, kl_threshold = 0.01 ,size =10):
y_out = []
while True:
y = [ np.random.uniform(1, size+1) for i in range(size)]
y /= np.sum(y)
kl_result = cal_kl(x, y)
if kl_result < kl_threshold:
print(kl_result)
y_out = y
plt.plot(x)
plt.plot(y)
break
return y_out
def KL_main():
np.random.seed(1)
size = 10
x = [ np.random.uniform(1, size+1) for i in range(size)]
x = x / np.sum(x)
y_out = kl_test(x,kl_threshold = 0.01)
plt.show()
print(x, y_out)
if __name__ == '__main__':
p = [1, 0, 2, 3, 5, 3, 1, 7]
bin = 4
split_p = np.array_split(p, bin)
q = []
for arr in split_p:
avg = np.sum(arr)/ np.count_nonzero(arr)
for item in arr:
if item !=0:
q.append(avg)
continue
q.append(0)
print(q)
p /= np.sum(p)
q /= np.sum(q)
print(p)
print(q)
p = smooth_data(p)
q = smooth_data(q)
print(p)
print(q)
#cal kl
print(cal_kl(p, q))
以下两点需要说明:
- 在计算KL散度时,要保证
,需要加上一个很小的正数eps
- 由于p和q都是直方图统计的概率分布,它们的和始终为1,因此,单纯的在
5.3.2 第二种情况
第一种情况属于P和Q分布的bin虽然不同但是可以被整除,那么不能整除的情况怎么解决?下面通过三个案例来分析
(1)第一个案例(不能整除)
假设input_p=[1,0,2,3,5],dst_bis=4
1、计算stride
- stride = input.size / bin 取整,为1
2、按照stride划分
- [1] [0] [2] [3] [5](多余位)
3、判断每一位是否非零
- [1,0,1,1,1]
4、将多余位累加到最后整除的位置上,在上面多余位是[5],最后整除的位置上是[3],因此[5+3=8]进行替换
- [1] [0] [2] [8]
5、进行位扩展从而得到output_q
- 将4的结果和3的非零位进行一个映射得到最终的结果[1] [0] [2] [4] [4]
第二个案例(不能整除)
假设input_p=[1,0,2,3,5,6],dst_bins=4
1、计算stride
- stride = input.size / bin 取整
2、按照stride划分
- [1] [0] [2] [3] [5] [6](多余位)
3、判断每一位是否非零
- [1,0,1,1,1,1]
4、将多余位累加到最后整除的位置上,在上面多余位是[5]和[6],最后整除的位置上是[3],因此[5+6+3=14]进行替换
- [1] [0] [2] [14]
5、进行位扩展从而得到output_q
- 将4的结果和3的非零位进行一个映射得到最终的结果[1] [0] [2] [4.67] [4.67] [4.67]
第三个示例(能整除):
假设input_p=[1,0,2,3,5,6,7,8] ,dst_bins=4
1、计算stride
- stride = input.size / bin 取整
2、按照stride划分
- [1,0] [2,3] [5,6] [7,8]
3、判断每一位是否非零
- [1,0,1,1,1,1,1,1]
4.、将多余位累加到最后整除的位置上,在上面无多余位,最后整除的位置上是[8],因此[0+8=8]进行替换
- [1,0] [2,3] [5,6] [7,8]
5、进行位扩展从而得到output_q
- 将4的结果和3的非零位进行一个映射得到最终的结果[1,0] [2.5,2.5] [5.5,5.5] [7.5,7.5]
下面使用代码实现上述的一个思想
import random
import numpy as np
import matplotlib.pyplot as plt
def generator_P(size):
walk = []
avg = random.uniform(3.000, 600.999)
std = random.uniform(500.000, 1024.959)
for _ in range(size):
walk.append(random.gauss(avg, std))
return walk
def smooth_distribution(p, eps=0.0001):
is_zeros = (p == 0).astype(np.float32)
is_nonzeros = (p != 0).astype(np.float32)
n_zeros = is_zeros.sum()
n_nonzeros = p.size - n_zeros
if not n_nonzeros:
raise ValueError('The discrete probability distribution is malformed. All entries are 0.')
eps1 = eps * float(n_zeros) / float(n_nonzeros)
assert eps1 < 1.0, 'n_zeros=%d, n_nonzeros=%d, eps1=%f' % (n_zeros, n_nonzeros, eps1)
hist = p.astype(np.float32)
hist += eps * is_zeros + (-eps1) * is_nonzeros
assert (hist <= 0).sum() == 0
return hist
import copy
import scipy.stats as stats
def threshold_distribution(distribution, target_bin=128):
distribution = distribution[1:]
length = distribution.size # 获取概率分布的大小
threshold_sum = sum(distribution[target_bin:]) # 计算概率分布从target_bin位置开始的累加和,即outliers_count
kl_divergence = np.zeros(length - target_bin) # 初始化一个numpy数组,用来存放每个阈值下计算得到的KL散度
for threshold in range(target_bin, length):
sliced_nd_hist = copy.deepcopy(distribution[:threshold])
# generate reference distribution P
p = sliced_nd_hist.copy()
p[threshold - 1] += threshold_sum # 将后面outliers_count加到reference_distribution_P中,得到新的概率分布
threshold_sum = threshold_sum - distribution[threshold] # 更新threshold_sum的值
# is_nonzeros[k] indicates whether hist[k] is nonzero
is_nonzeros = (p != 0).astype(np.int64) # 判断每一位是否非零
quantized_bins = np.zeros(target_bin, dtype=np.int64)
# calculate how many bins should be merged to generate
# quantized distribution q
num_merged_bins = sliced_nd_hist.size // target_bin # 计算stride
# merge hist into num_quantized_bins bins
for j in range(target_bin):
start = j * num_merged_bins
stop = start + num_merged_bins
quantized_bins[j] = sliced_nd_hist[start:stop].sum()
quantized_bins[-1] += sliced_nd_hist[target_bin * num_merged_bins:].sum() # 将多余位累加到最后整除的位置上
# expand quantized_bins into p.size bins
q = np.zeros(sliced_nd_hist.size, dtype=np.float64) # 进行位扩展
for j in range(target_bin):
start = j * num_merged_bins
if j == target_bin - 1:
stop = -1
else:
stop = start + num_merged_bins
norm = is_nonzeros[start:stop].sum()
if norm != 0:
q[start:stop] = float(quantized_bins[j]) / float(norm)
# 平滑处理,保证KLD计算出来不会无限大
p = smooth_distribution(p)
q = smooth_distribution(q)
# calculate kl_divergence between p and q
kl_divergence[threshold - target_bin] = stats.entropy(p, q) # 计算KL散度
min_kl_divergence = np.argmin(kl_divergence) # 选择最小的KL散度
threshold_value = min_kl_divergence + target_bin
return threshold_value
if __name__ == '__main__':
# 获取KL最小阈值
size = 20480
P = generator_P(size)
P = np.array(P)
P = P[P>0]
print("最大的激活值", max(np.absolute(P)))
hist, bins = np.histogram(P, bins=2048)
threshold = threshold_distribution(hist, target_bin=128)
print("threshold 所在组:", threshold)
print("threshold 所在组的区间范围:", bins[threshold])
# 分成split_zie组,density表示是否要normed
plt.title("Relu activation value Histogram")
plt.xlabel("Activation values")
plt.ylabel("Normalized number of Counts")
plt.hist(P, bins=2047)
plt.vlines(bins[threshold], 0, 30, colors='r', linestyles='dashed')
plt.show()
个人对于代码理解如下:
原始数组有2048个bin,目标128个bin,我们的目标是找到一个最佳的“截断点”,把2048个bin用128个bin来表示(量化),同时是的信息损失最小。结合上面的三个案例的逻辑,在2048个bin中,首先前0-127个bin不做改变,128的位置开始,向右遍历所有可能得截断点,直到2048,同时对于每一个截断点,都会计算一次KL散度。
初始状态:
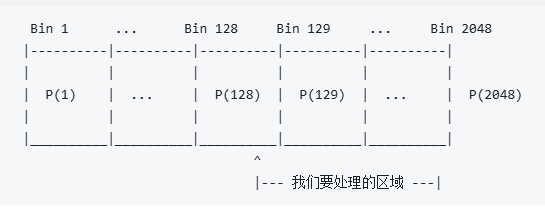
第1步:构建P分布
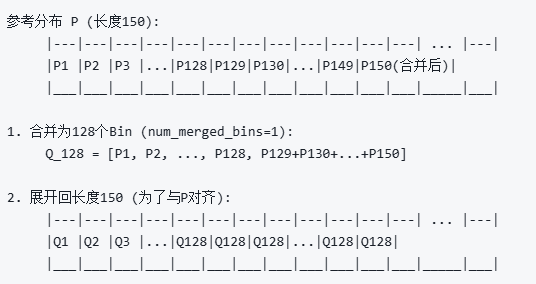
对于每一个候选的 threshold(假设是 threshold = 150),我们做以下操作:
- 截取分布:取原始分布从第1个bin到第
threshold个bin的部分。 - 合并:将所有在
threshold之后的bin(即从threshold+1到 2048)的概率值,全部累加到第threshold个bin上。这样,我们就得到了一个新的、包含了所有原始概率信息的分布P。
此时的P分布为(threshold=150)
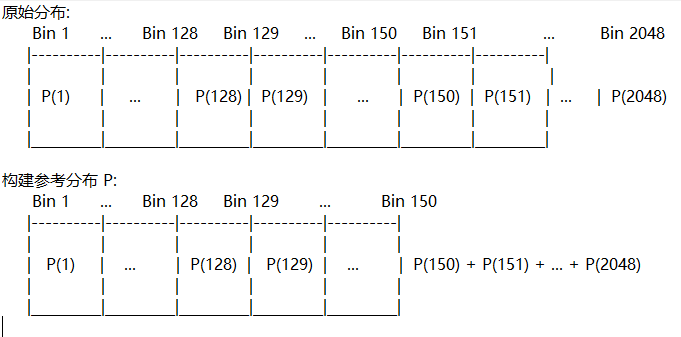
第2步:构建Q分布
需要将上一步得到的长度为 threshold 的分布 P,压缩到 target_bin(128)个bin上。
- 计算步长:
num_merged_bins = threshold // target_bin。例如,如果threshold=150,num_merged_bins = 150 // 128 = 1(不能整除)。 - 合并Bin:将分布
P中的num_merged_bins个连续的bin合并成一个bin,从而得到128个新的bin。 - 展开分布:为了让
P和Q的长度相同以便计算KL散度,我们将这128个新bin的值,再“均匀地”展开回threshold的长度。
此时的分布情况为
第3步:平滑处理并计算KL散度
- 平滑处理:直接计算KL散度时,如果某个bin在
P中有值但在Q中为0,会导致无穷大。smooth_distribution函数通过给0值增加一个极小值eps,给非0值减去一个极小值eps1,来避免这个问题。 - 计算KL散度:使用
stats.entropy(p, q)计算P和Q之间的KL散度。这个值代表了用Q来近似P所造成的信息损失。
第4步:寻找最优阈值
函数会从 threshold=128 遍历到 threshold=2048,为每一个 threshold 都重复上述1-3步,得到一个对应的KL散度值。
基本上就是么个过程
为什么我们量化的是128个bins而不是256个bins?
回答:因为量化中针对的数据是激活函数ReLU后的,即经过ReLU后的值均为正数,所以负数就不用考虑了,而原来INT8的取值范围是在[-128,127]之间,因此[-128,0]就不用考虑了,而原始的分布[0,127]就能够表达,因此for循环就是从[128,2048]

















 4280
4280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









