




一、Kubernetes的三种IP
- Node IP:Node节点的IP地址
- Node IP是Kubernetes集群中节点的物理网卡IP地址,所有属于这个网络的服务器之间都能通过这个网络直接通信。
- Pod IP: Pod的IP地址
- Pod IP是每个Pod的IP地址,他是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。
- Cluster IP:Service的IP地址(Service Virtual IP service vip)
- Service VIP 是一个服务、进程,运行在每个node节点上,是一个独立的网关入口,它的高可用由etcd保证,这个服务用的映射数据是存在etcd上的。
- 实际消费者Pod也并不直接调服务的ClusterIP,而是先调用服务名,因为ClusterIP也会变(例如针对TEST/UAT/PROD等不同环境的发布,ClusterIP会不同),只有服务名一般不变。
- Cluster IP是一个虚拟的IP。
- Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址。
- Cluster IP无法被ping,他没有一个“实体网络对象”来响应。
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。
二、Service
- 一个 Pod 只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的 IP 启动一个新的 Pod,因此不能以确定的 IP 和端口号提供服务。我们需要稳定地提供服务需要服务发现和负载均衡能力。
服务发现完成的工作,是针对客户端访问的服务,找到对应的的后端服务实例。在 K8 集群中,客户端需要访问的服务就是 Service 对象。每个 Service 会对应一个集群内部有效的虚拟 IP,集群内部通过虚拟 IP 访问一个服务。- 在 Kubernetes 集群中微服务的负载均衡是由 Kube-proxy 实现的。Kube-proxy 是 Kubernetes 集群内部的负载均衡器。
它是一个分布式代理服务器,在 Kubernetes 的每个节点上都有一个。这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的 Kube-proxy 就越多,高可用节点也随之增多。与之相比,我们平时在服务器端做个反向代理做负载均衡,还要进一步解决反向代理的负载均衡和高可用问题。 Service是K8S服务的核心,屏蔽了服务细节,统一对外暴露服务接口。举个例子,我们的一个服务A,部署了3个备份,也就是3个Pod;对于用户来说,只需要关注一个Service的入口就可以,而不需要操心究竟应该请求哪一个Pod。优势非常明显:一方面外部用户不需要感知因为Pod上服务的意外崩溃、K8S重新拉起Pod而造成的IP变更,外部用户也不需要感知因升级、变更服务带来的Pod替换而造成的IP变化,另一方面,Service还可以做流量负载均衡。
Service的三种类型
ClusterIP
apiVersion: v1
kind: Service
metadata:
name: etcd
namespace: chogori
spec:
clusterIP: 10.233.50.242 #指定服务类型为ClusterIP
ports: #指定端口(两个)
- name: client
port: 2379 #服务的端口
protocol: TCP
targetPort: 2379 #容器的端口
- name: peer
port: 2380
protocol: TCP
targetPort: 2380
selector: #标签选择器,必须指定pod资源本身的标签
app: etcd
sessionAffinity: None #定义要使用的粘性会话的类型,它仅支持使用“ None” 和“ ClientIP” 两种属性值
type: ClusterIP
- ClusterIP是Service默认的类型/机制。如上面的yaml文件,并没有指定type,那执行
kubectl create -f service-demo.yaml之后就会是一个CluterIP类型的Service。 - CluterIP类型的Service会提供一个’CLUSTER-IP’和’PORT(S)',能够允许k8s内部相同namespace下的任何Pod访问。
[root@k8s-master mainfests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd ClusterIP 10.233.50.242 <none> 2379/TCP,2380/TCP 34d
[root@k8s-master mainfests]# kubectl describe svc -n chogori etcd
Name: etcd
Namespace: chogori
Labels: <none>
Annotations: <none>
Selector: app=etcd
Type: ClusterIP
IP: 10.233.50.242 # service ip
Port: client 2379/TCP # 第一个pod的端口
TargetPort: 2379/TCP
Endpoints: 11.161.70.212:2379 # 此处的ip+端口就是pod的ip+端口
Port: peer 2380/TCP # 第二个pod的端口
TargetPort: 2380/TCP
Endpoints: 11.161.70.212:2380 # 此处的ip+端口就是pod的ip+端口
Session Affinity: None
Events: <none>
ClusterIP服务注册发现流程
- 在服务Pod实例发布时,Kubelet会负责启动Pod实例,启动完成后,Kubelet会把服务的PodIP列表汇报注册到Master节点。
- 使用ClusterIP发布Service,K8s会为服务分配 ClusterIP,同时会在集群中创建出一个同名的Endpoints对象,用于存储该Service下的Pod IP。
- 在服务发现阶段,运行在每个节点的Kube-Proxy会监听Service和Endpoints,并发现服务ClusterIP和PodIP列表映射关系,并在各自的node节点设置相关的iptables或者IPVS转发规则,指示iptables在接收到目标为某个ClusterIP请求时,进行负载均衡并转发到对应的PodIP上。
- 集群内部的消费者通过ClusterIP发起调用,这个ClusterIP会被本地iptables机制截获,然后通过负载均衡,转发到目标服务Pod实例上。
- ClusterIP 确实是仅在 Kubernetes 集群内部可用的,这意味着它不能从集群外部直接访问。这是为了安全和隔离,确保只有集群内部的流量可以访问这些服务。
NodePort
- NodePort可以为外部提供服务。
- NodePort即节点Port,通常在部署Kubernetes集群系统时会预留一个端口范围用于NodePort,其范围默认为:30000~32767之间的端口。定义NodePort类型的Service资源时,需要使用.spec.type进行明确指定。
- NodePort实际是在Pod所在的物理机器上开了一个端口,让外部流量从这个端口先导流到自己的’port’,再导入’targetPort’(也就是Pod的端口)。
先创建delpoyment并做好标签
[root@k8s-master mainfests]# kubectl get pods --show-labels |grep myapp-deploy
myapp-deploy-69b47bc96d-4hxxw 1/1 Running 0 12m app=myapp,release=canary
myapp-deploy-69b47bc96d-95bc4 1/1 Running 0 12m app=myapp,release=canary
myapp-deploy-69b47bc96d-hwbzt 1/1 Running 0 12m app=myapp,release=canary
myapp-deploy-69b47bc96d-pjv74 1/1 Running 0 12m app=myapp,release=canary
myapp-deploy-69b47bc96d-rf7bs 1/1 Running 0 12m app=myapp,release=canary
再创建Service
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
selector:
app: myapp
release: canary
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30080
查询
[root@k8s-master mainfests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myapp NodePort 10.101.245.119 <none> 80:30080/TCP 5s
尝试从外部访问
下面的命令中的ip应该是集群中任意一个node的ip即可。
[root@k8s-master mainfests]# while true;do curl http://192.168.56.11:30080/hostname.html;sleep 1;done
myapp-deploy-69b47bc96d-95bc4
myapp-deploy-69b47bc96d-4hxxw
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-rf7bs
myapp-deploy-69b47bc96d-95bc4
myapp-deploy-69b47bc96d-rf7bs
myapp-deploy-69b47bc96d-95bc4
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-4hxxw
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-4hxxw
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-pjv74
myapp-deploy-69b47bc96d-95bc4
myapp-deploy-69b47bc96d-hwbzt
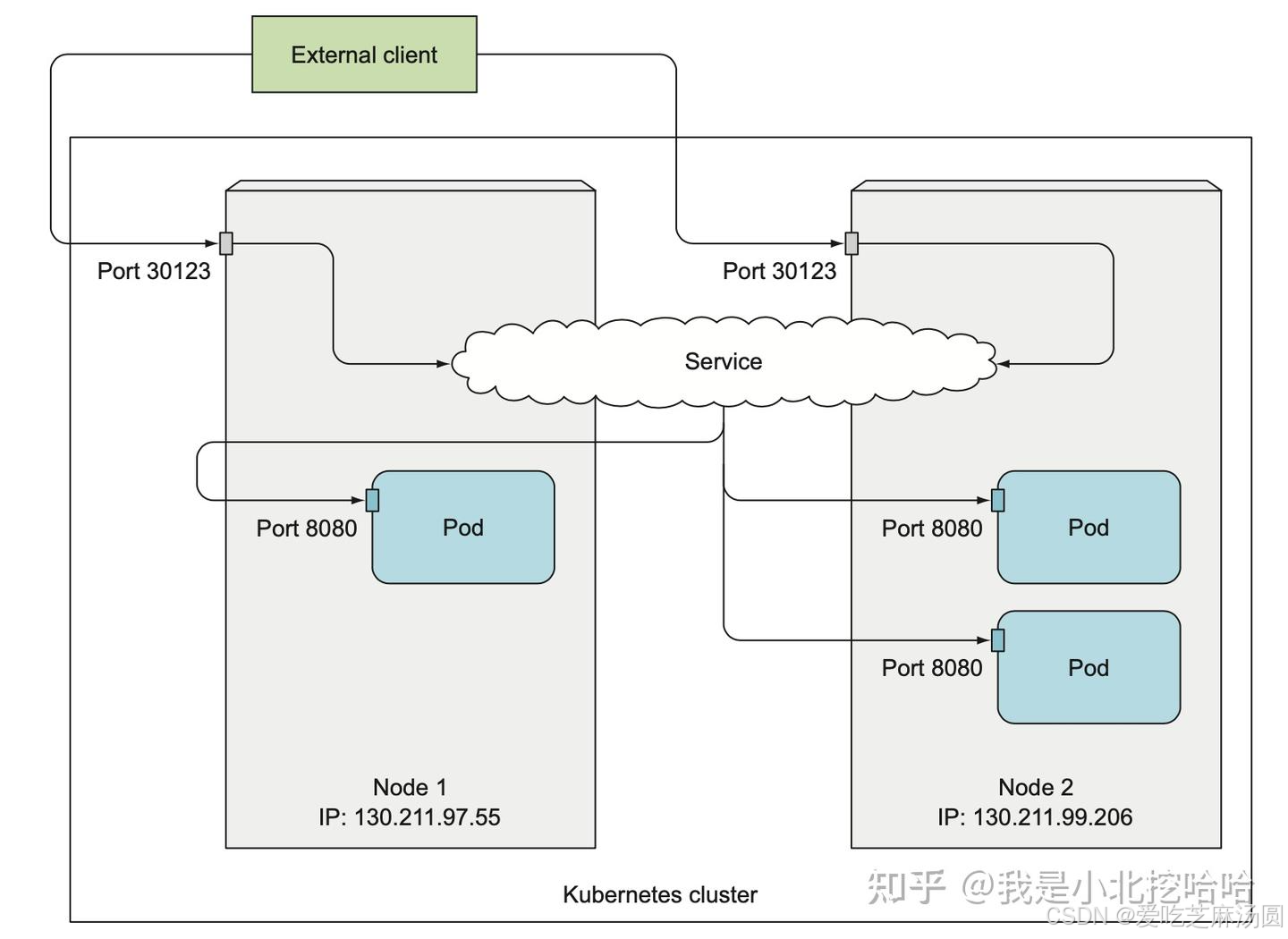
NodePort服务注册发现流程
- 在服务Pod实例发布时,Kubelet会负责启动Pod实例,启动完成后,Kubelet会把服务的PodIP列表汇报注册到Master节点。
- 使用使用NodePort发布服务,并指定一个30000~32767范围内的端口,所有Worker节点都会对这个端口进监听。 k8s在集群中创建出一个同名的Endpoints对象,用于存储该Service下的Pod IP。
- 运行在每个节点的Kube-Proxy会监听Service和Endpoints,并发现服务ClusterIP和PodIP列表映射关系,并在各自的node节点设置相关的iptables或者IPVS转发规则。
- 当外部流量到达任意节点的 NodePort 端口时,kube-proxy 配置的规则会将流量转发到后端的 Service。
- NodePort 本身并不提供负载均衡功能。 NodePort 使得服务可以通过节点上的静态端口对外访问,但负载均衡是由 Service 本身(通过 kube-proxy 设置的 iptables 或 IPVS 规则)来实现的。
LoadBalancer
LoadBalacer其实就是在客户访问最开始加入一个负载均衡器。
- 性能:NodePort 性能受限于节点数量和端口范围,适合小型集群;LoadBalancer 利用云服务提供商的高性能负载均衡器,适合大型集群。
- 安全性:NodePort 暴露节点IP和端口,安全性较低;LoadBalancer 由云服务提供商管理外部IP和端口,安全性较高。
- 成本:NodePort 无需额外费用,成本较低;LoadBalancer 需要支付云服务提供商的负载均衡器费用,成本较高。
- 灵活性:NodePort 配置简单,灵活性较低;LoadBalancer 支持多种负载均衡策略,灵活性较高。
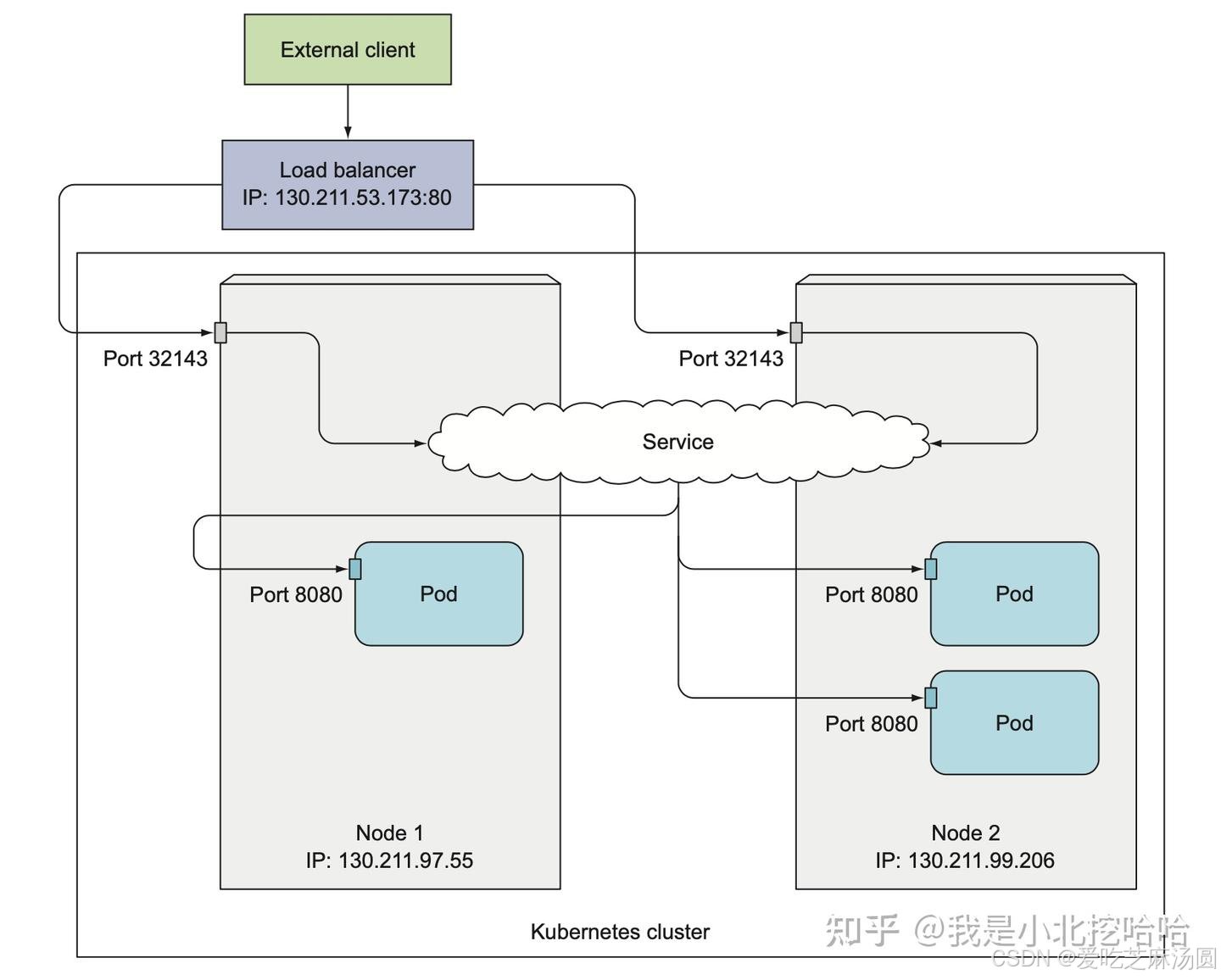
两种特殊的Service
pod会话保持(粘性会话)
Service资源还支持Session affinity(粘性会话)机制,可以将来自同一个客户端的请求始终转发至同一个后端的Pod对象,这意味着它会影响调度算法的流量分发功用,进而降低其负载均衡的效果。- 因此,当客户端访问Pod中的应用程序时,如果有基于客户端身份保存某些私有信息,并基于这些私有信息追踪用户的活动等一类的需求时,那么应该启用session affinity机制。
- Service affinity的效果仅仅在一段时间内生效,默认值为10800秒,超出时长,客户端再次访问会重新调度。
该机制仅能基于客户端IP地址识别客户端身份,它会将经由同一个NAT服务器进行原地址转换的所有客户端识别为同一个客户端,由此可知,其调度的效果并不理想。 - Service 资源 通过
.spec.sessionAffinity和.spec.sessionAffinityConfig两个字段配置粘性会话。.spec.sessionAffinity字段用于定义要使用的粘性会话的类型,它仅支持使用“ None” 和“ ClientIP” 两种属性值。- None就是随机访问,随机访问,默认就是None。
- ClientIP是来自于同一个客户端的请求调度到同一个pod中。
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
selector:
app: myapp
release: canary
sessionAffinity: ClientIP # 11
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30080
再次访问
[root@k8s-master mainfests]# whiletrue;do curl http://192.168.56.11:30080/hostname.html;sleep 1;done
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
myapp-deploy-69b47bc96d-hwbzt
通过打补丁的方式:
#session保持,同一ip访问同一个pod
kubectl patch svc myapp -p '{"spec":{"sessionAffinity":"ClusterIP"}}'
#取消session
kubectl patch svc myapp -p '{"spec":{"sessionAffinity":"None"}}'
Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。- 对这类 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了 selector。
- 这个选项允许开发人员自由寻找他们自己的方式,从而降低与 Kubernetes 系统的耦合性。
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
release: canary
clusterIP: "None" #headless的clusterIP值为None
ports:
- port: 80
targetPort: 80
headless貌似与starteful有关系,不太懂,回头再查资料~~
Kube-Proxy的三种模式
iptables和ipvs都是内核态也就是基于netfilter,只有userspace模式是用户态。
userspace模式
- kube-proxy 在用户空间监听一个端口,并将所有到 Service 的流量转发到后端 Pod。
- 具体来说,kube-proxy 为每个 Service 在节点上打开一个随机端口,并建立 iptables 规则将流量重定向到这个代理端口。然后,kube-proxy 将请求转发到后端 Pod。
- 这种模式的优点是实现简单,但缺点是性能较低,因为每个数据包都需要经过用户空间的处理,增加了额外的开销和延迟。
Iptables 模式
- 这是 kube-proxy 的改进版,相比 userspace 模式有显著的性能提升。在这种模式下,kube-proxy 使用 iptables 来设置网络规则,这些规则直接在内核空间进行处理。
- 当有新的 Service 创建时,kube-proxy 会生成相应的 iptables 规则,定义从 Service IP 和端口到后端 Pod 的 NAT 转发规则。
- 数据包在内核空间直接被转发到相应的后端 Pod,减少了上下文切换,提高了转发性能。
- 优点是性能更好,但在处理大量规则时,规则管理和更新可能会变得复杂。
Ipvs 模式
- 这是 kube-proxy 的最新实现方式,使用 Linux 内核中的 IP Virtual Server (IPVS) 技术。
- IPVS 是内核中的一个模块,专门用于负载均衡,支持多种调度算法,如轮询、最小连接数、最短延迟等。
- 数据包在内核空间通过 IPVS 直接转发,性能更高,同时支持更多的负载均衡算法和更复杂的网络规则。
- 优点是性能最佳,支持更多的负载均衡算法和规则,但需要内核支持 IPVS 模块。
通常情况下,默认使用 ipvs 模式,因为它提供了更好的性能和更多的负载均衡选项,尤其是在大规模集群中。
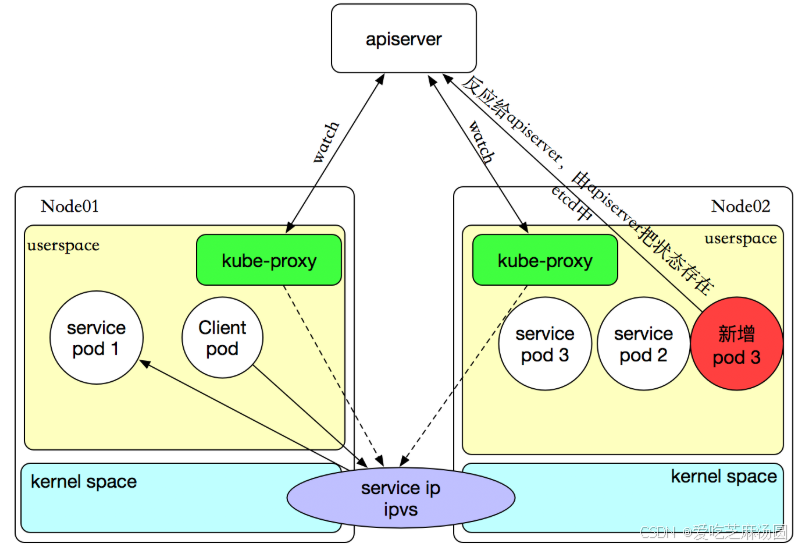
- 当用户在kubernetes集群中创建了含有label的Service之后,同时会在集群中创建出一个同名的Endpoints对象,用于存储该Service下的Pod IP。
- 运行在每个Node节点的kube-proxy会实时的watch Service和 Endpoints对象,并会在各自的Node节点设置相关的iptables或IPVS规则,用于之后用户通过Service的ClusterIP去访问该Service下的服务。
- 当kube-proxy把需要的规则设置完成之后,用户便可以在集群内的Node或客户端Pod上通过ClusterIP经过iptables或IPVS设置的规则进行路由和转发,最终将客户端请求发送到真实的后端Pod。
三、pod通讯
pod内部通讯
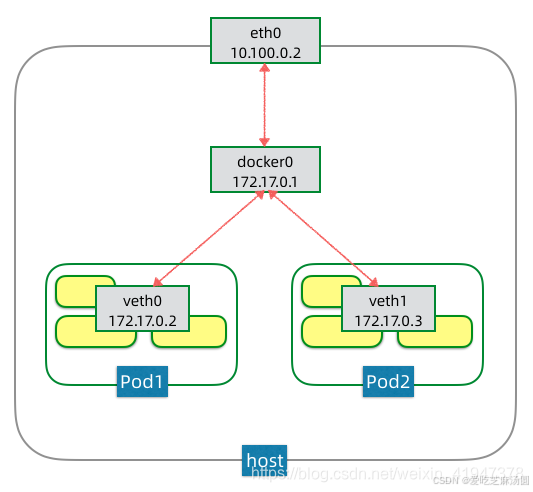
- eth0是节点主机上的网卡,这个是支持该节点流量出入的设备,也是支持集群节点间IP寻址和互通的设备。
- docker0是一个虚拟网桥,可以简单理解为一个虚拟交换机,它是支持该节点上的Pod之间进行IP寻址和互通的设备。
- veth0则是Pod1的虚拟网卡,是支持该Pod内容器互通和对外访问的虚拟设备。docker0网桥和veth0网卡,都是linux支持和创建的虚拟网络设备。
pod内部容器是通过共享一个虚拟网卡相互通信的,可以直接通过localhost相互访问,而这个虚拟网卡是通过一个特殊的容器pause创建的。
同node的pod通讯
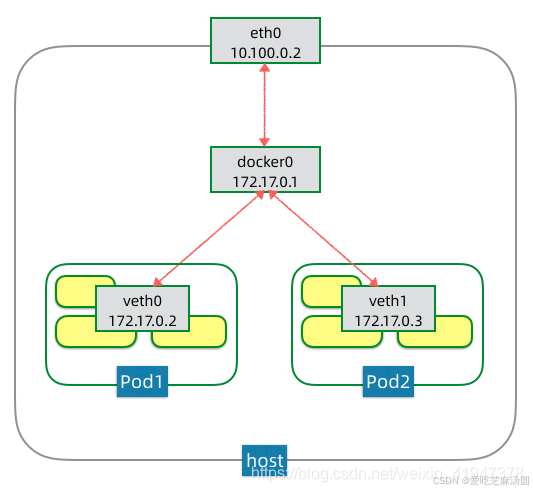
docker0是一个虚拟网桥,它是支持该节点上的Pod之间进行IP寻址和互通的设备。Pod的IP是由docker0网桥分配的,因为这些Pods都连在同一个网桥上,在同一个网段内,它们可以进行IP寻址和互通。
不同node的pod通讯
- 路由方案
通过路由设备为K8s集群的Pod网络单独划分网段,并配置路由器支持Pod网络的转发。- 这种方案依赖于底层的网络设备,但是不引入额外性能开销。
- 覆盖网络方案
- 如果底层的网络是你无法控制的,比如说公有云网络,或者企业的运维团队不支持路由方案,可以采用覆盖(Overlay)网络方案。
- 覆盖网络就是在现有网络之上再建立一个虚拟网络,实现技术有很多,例如flannel/weavenet等等,这些方案大都采用隧道封包技术。
简单理解,Pod网络的数据包,在出节点之前,会先被封装成节点网络的数据包,当数据包到达目标节点,包内的Pod网络数据包会被解封出来,再转发给节点内部的Pod网络。- 这种方案对底层网络没有特别依赖,但是封包解包会引入额外性能开销。
四、Ingress
为什么使用Ingress
- 我们可以使用 Ingress 来使内部服务暴露到集群外部去,它为你节省了宝贵的静态 IP,因为你不需要声明多个 LoadBalancer 服务了, 此次,它还可以进行更多的额外配置。
手动配置Nginx代理服务
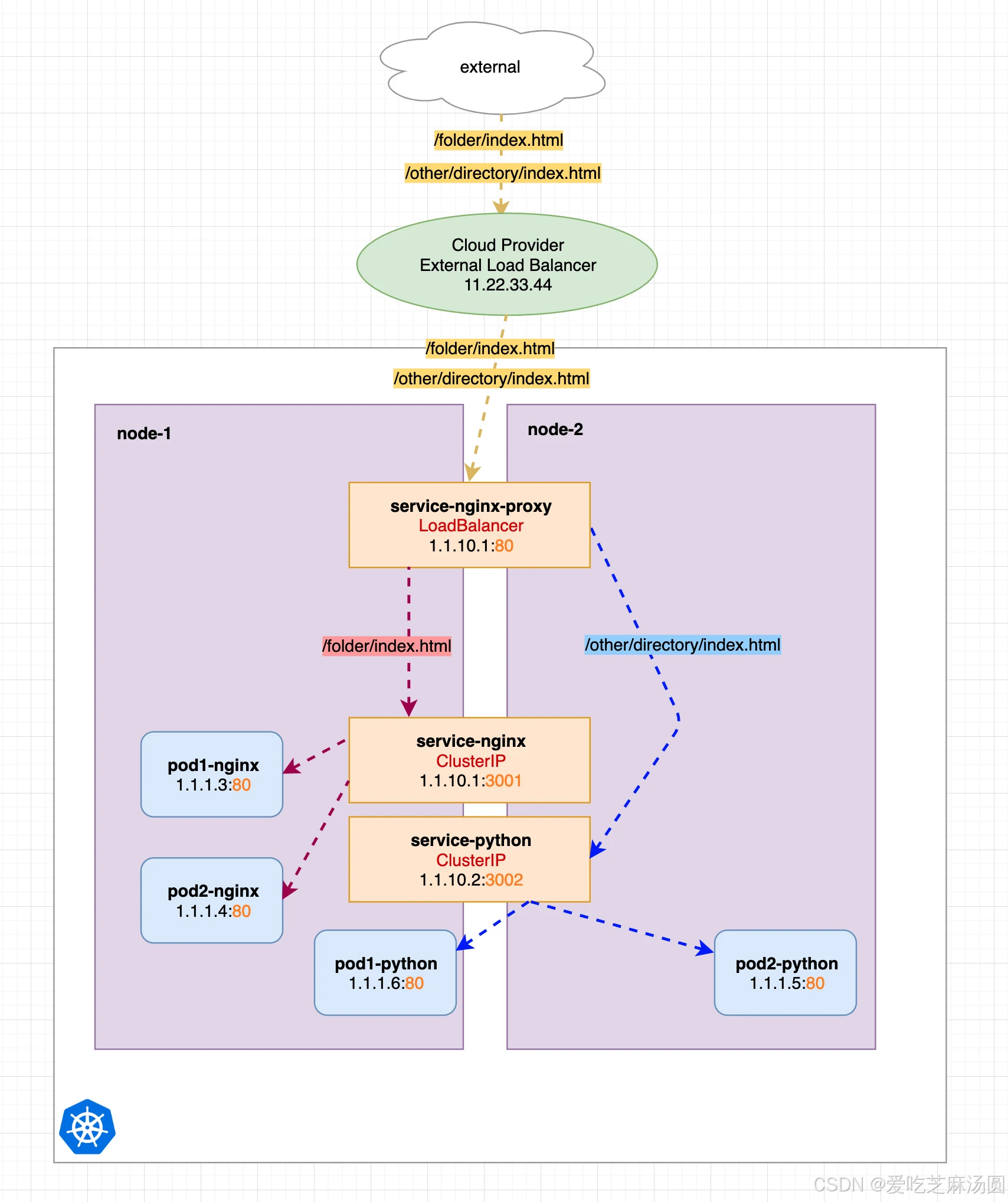
- 为了让ClusterIP类型可以暴露,可以手动配置Nginx代理服务。
- 我们新增了一个名为service-nginx-proxy的新服务,它实际上是我们唯一的一个 LoadBalancer 服务。service-nginx-proxy 仍然会指向一个或多个Nginx-pod-endpoints,之前的另外两个服务转换为简单的 ClusterIP 服务了。
使用Ingress代替手动的Nginx
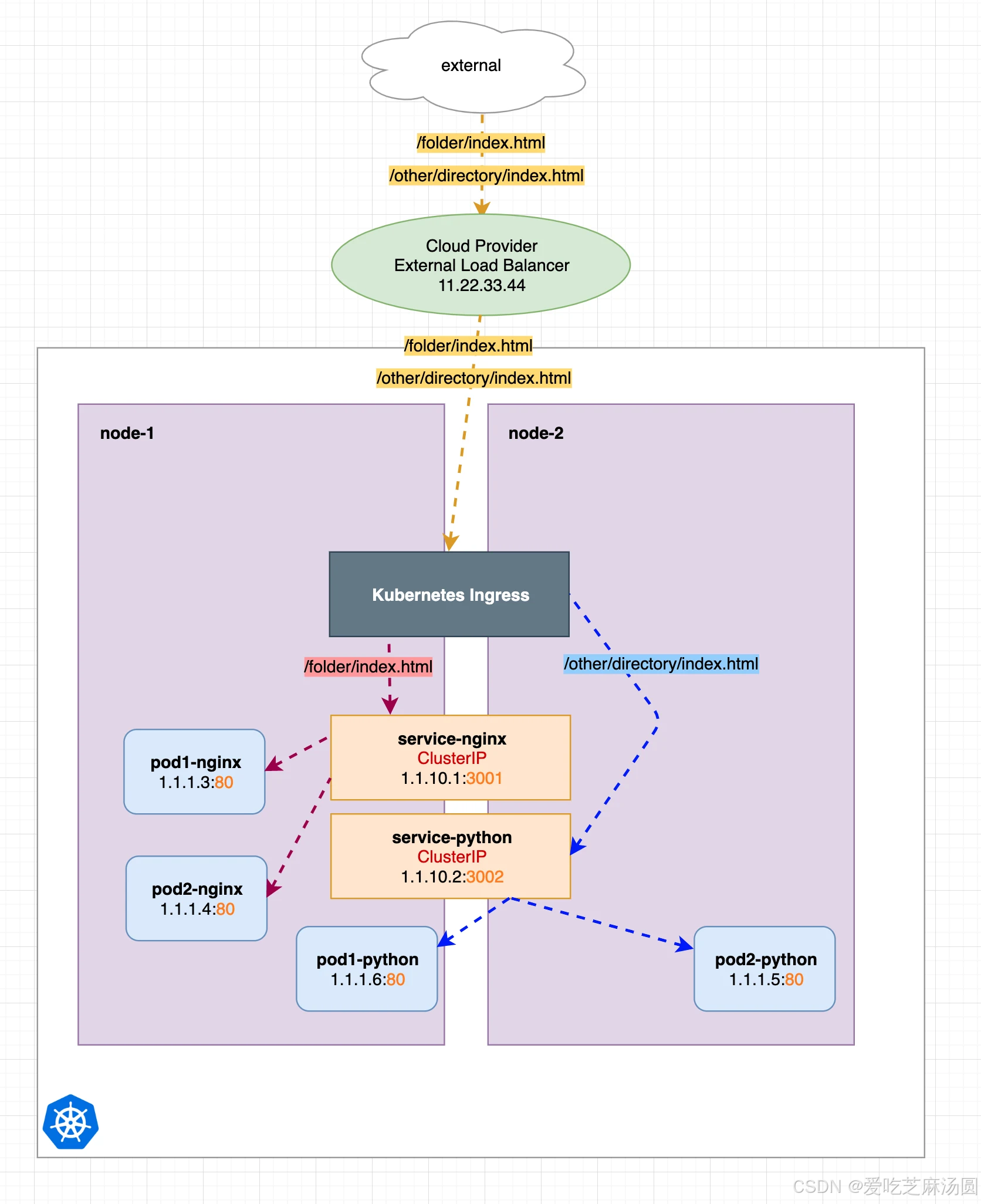
- 当我正确配置ingress后,即使是clusterip类型的service也可以暴露给外部。
- 现在我们将上面手动配置代理的方式转换为 Kubernetes Ingress 的方式,如下图所示,我们只是使用了一个预先配置好的 Nginx(Ingress),它已经为我们做了所有的代理重定向工作,这为我们节省了大量的手动配置工作了。
Ingress概述
-
当我正确配置ingress后,即使是clusterip类型的service也可以暴露给外部。
-
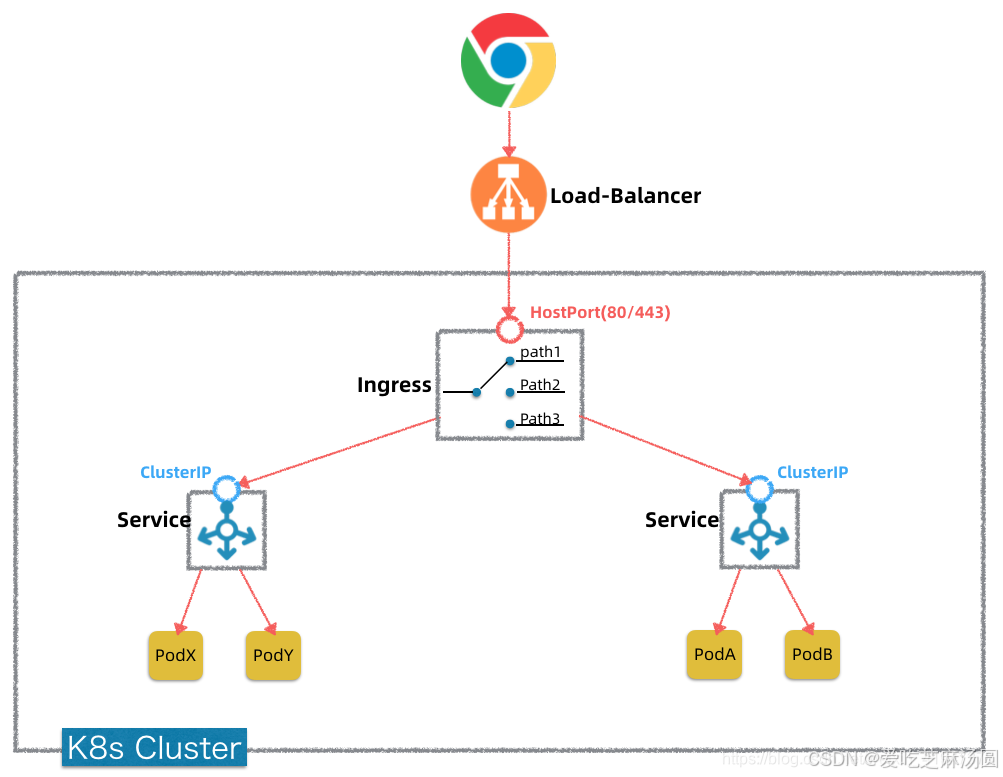
ingress可以简单理解为service的service,他通过独立的ingress对象来制定请求转发的规则,把请求路由到一个或多个service中。
这样就把服务与请求规则解耦了,可以从业务维度统一考虑业务的暴露,而不用为每个service单独考虑。
-
Ingress本质上就是K8s集群中的一个比较特殊的Service(发布Kind: Ingress)。
-
这个Service提供的功能主要就是7层反向代理(也可以提供安全认证,监控,限流和SSL证书等高级功能),功能类似Nginx。 -
这个Service对外暴露出去是通过HostPort(80/443),可以和上面LoadBalancer对接起来。
-
Ingress资源自身不能进行“流量穿透”,仅仅是一组规则的集合。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-myapp
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: myapp.magedu.com
http:
paths:
- path:
backend:
serviceName: myapp
servicePort: 80
定义了一个Ingress资源,其包含了一个转发规则:将发往myapp.magedu.com的请求,代理给一个名字为myapp的Service资源。
Ingress Controller概述
- Ingress资源自身不能进行“流量穿透”,仅仅是一组规则的集合。
- 这些集合规则还需要其他功能的辅助,比如监听某套接字,然后根据这些规则的匹配进行路由转发,这些能够为Ingress资源监听套接字并将流量转发的组件就是Ingress Controller。
Ingress控制器不是标准的k8s资源,仅仅是Kubernetes集群的一个附件,类似于CoreDNS,需要在集群上单独部署。
部署
详情见:
https://www.cnblogs.com/linuxk/p/9706720.html
https://www.qikqiak.com/post/visually-explained-k8s-ingress/
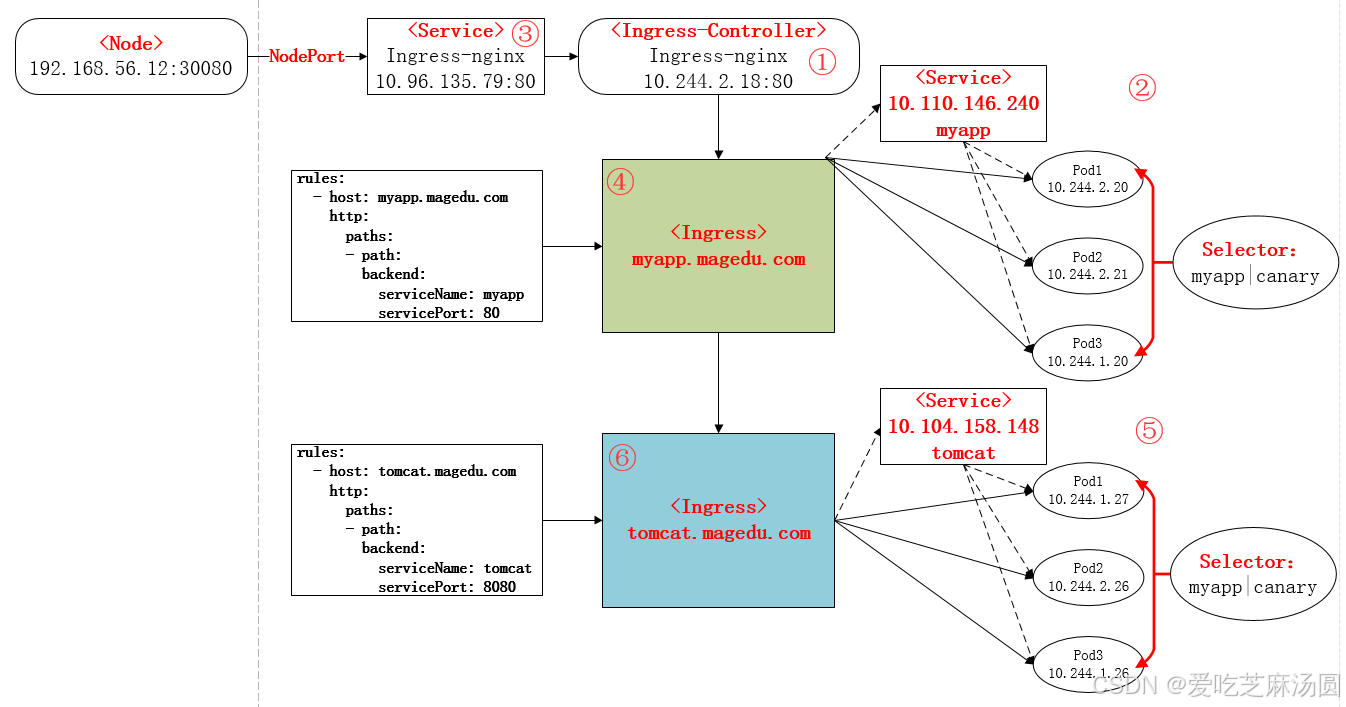
①下载Ingress-controller相关的YAML文件,并给Ingress-controller创建独立的名称空间;
②部署后端的服务,如myapp,并通过service进行暴露;
③部署Ingress-controller的service,以实现接入集群外部流量;
④部署Ingress,进行定义规则,使Ingress-controller和后端服务的Pod组进行关联。
本次部署后的说明图如下:
五、参考资料
https://www.cnblogs.com/linuxk/p/9706720.html
https://www.cnblogs.com/linuxk/p/9605901.html
https://zhuanlan.zhihu.com/p/367774885
https://www.qikqiak.com/post/visually-explained-k8s-ingress/

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









