




消息中间件
一、Kafka
1.1 基本概念
如何使用:
- 创建集群
- 创建topic
- 生产者逻辑
- 消费者逻辑
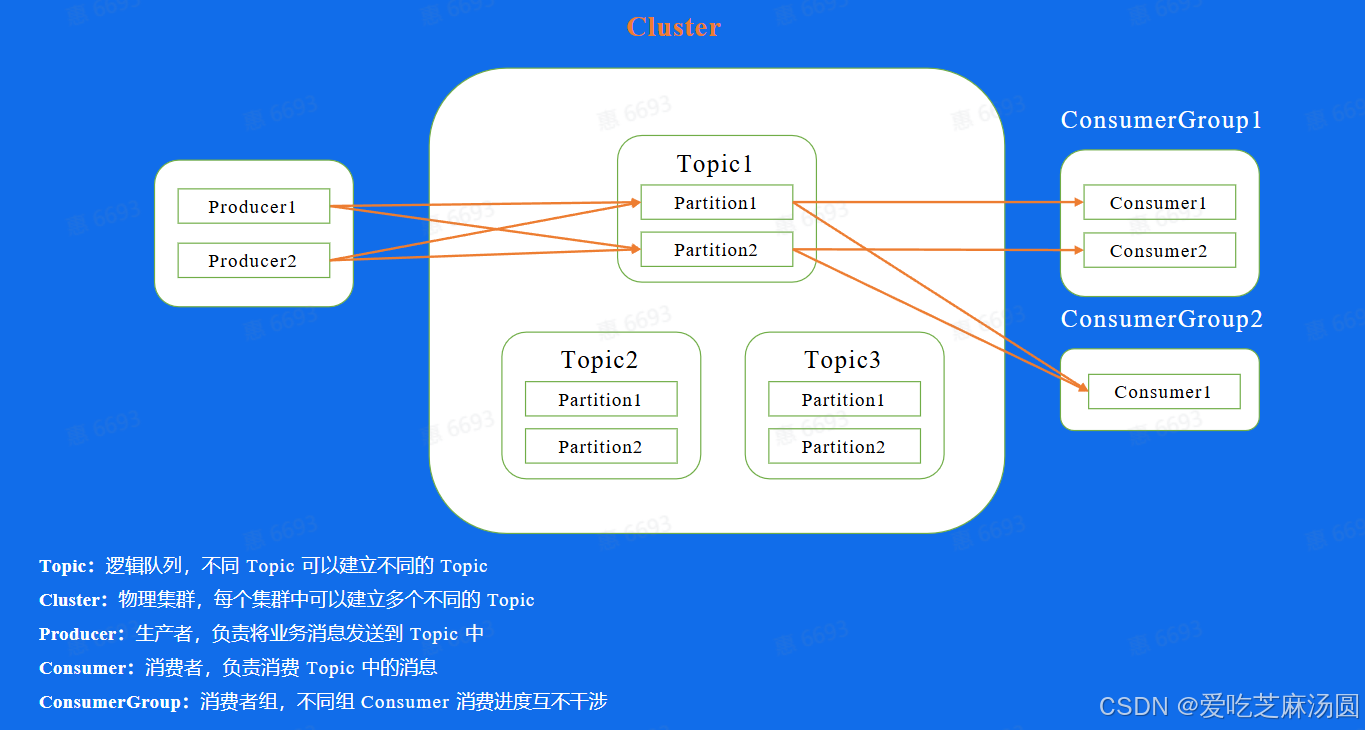
- 一个topic可以理解成一个业务场景
- 通常topic会有多个分片,分片之间可以并发处理,可以提高单个topic吞吐
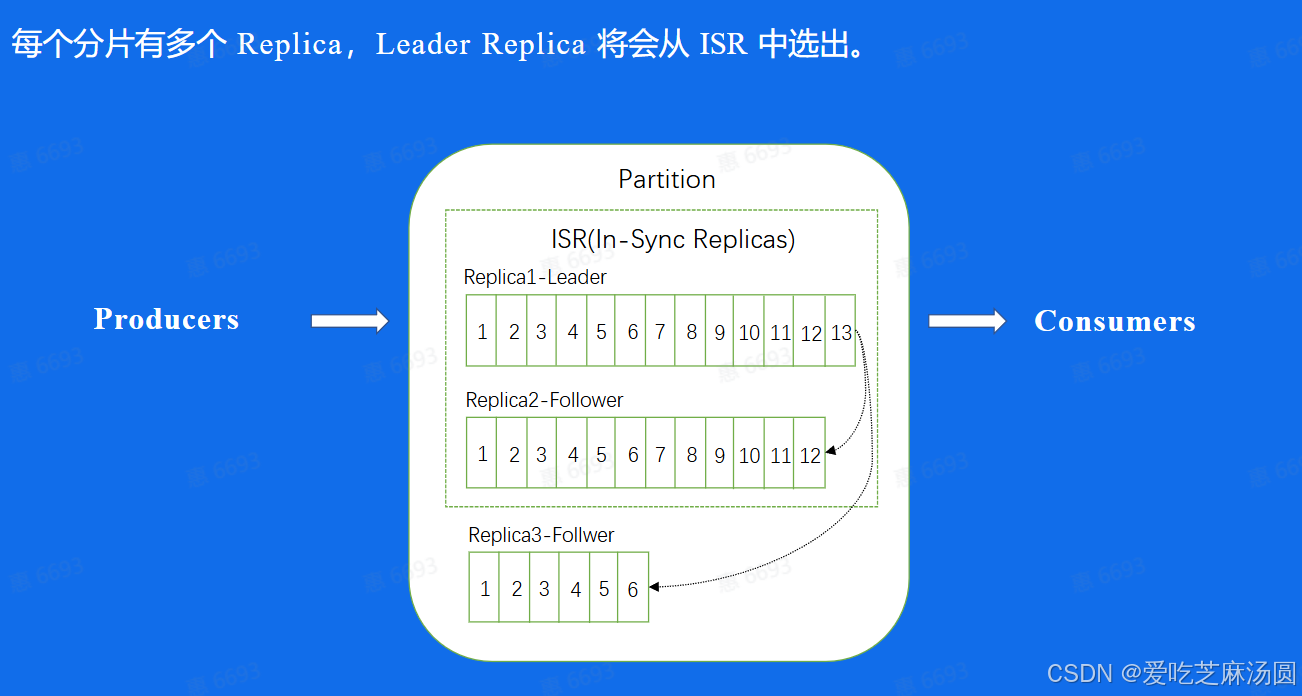
- 每个分片有多个副本,部署在不同的集群上,这是为了容灾。
- leader是进行对外的读入和读取的,follower是不断从leader拉取数据,努力保持和leader一致。
- 如何follower和leader差距过大(根据时间),就被踢出ISR,不允许系统宕机时它成为leader。
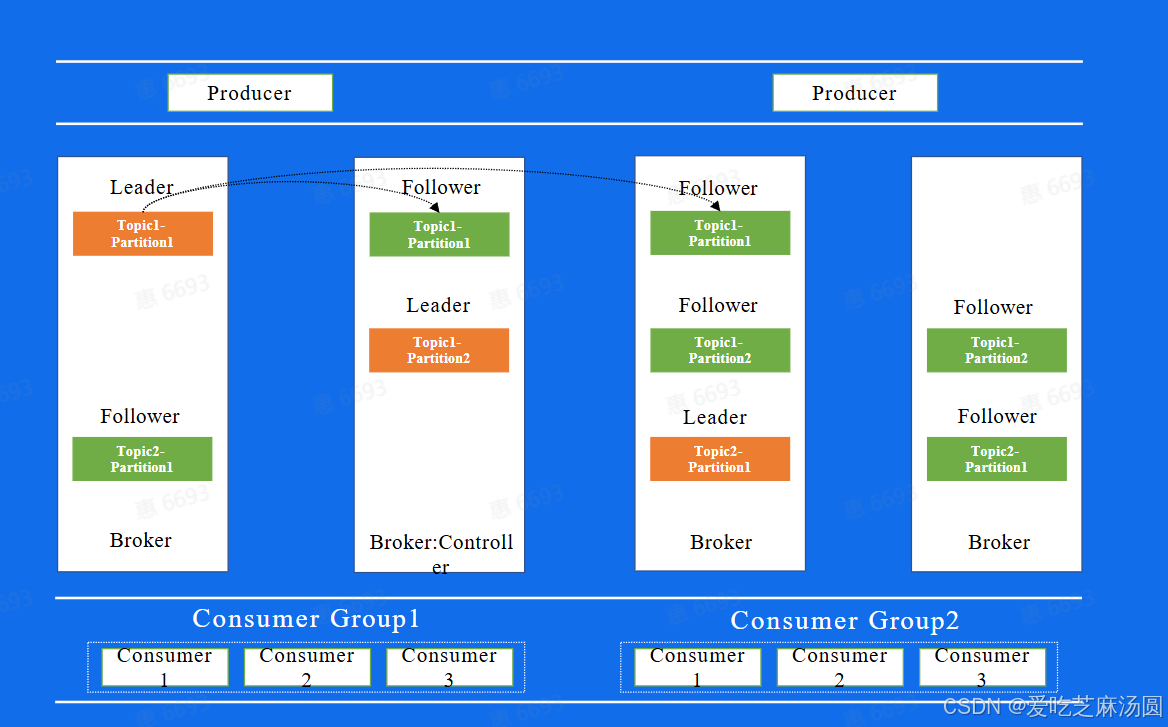
- 上面这幅图代表着Kafka中副本的分布图。
- Broker代表每一个Kafka的节点,所有的Broker节点最终组成了一个集群。
- 整个图表示,图中整个集群,包含了4个Broker机器节点,集群有两个Topic,分别是Topic1和Topic2, Topic1有两个分片, Topic2有1个分片,每个分片都是三副本的状态。
- 这里中间有一个Broker同时也扮演了Controller的角色, Controller是整个集群的大脑,负责对副本和Broker进行分配。
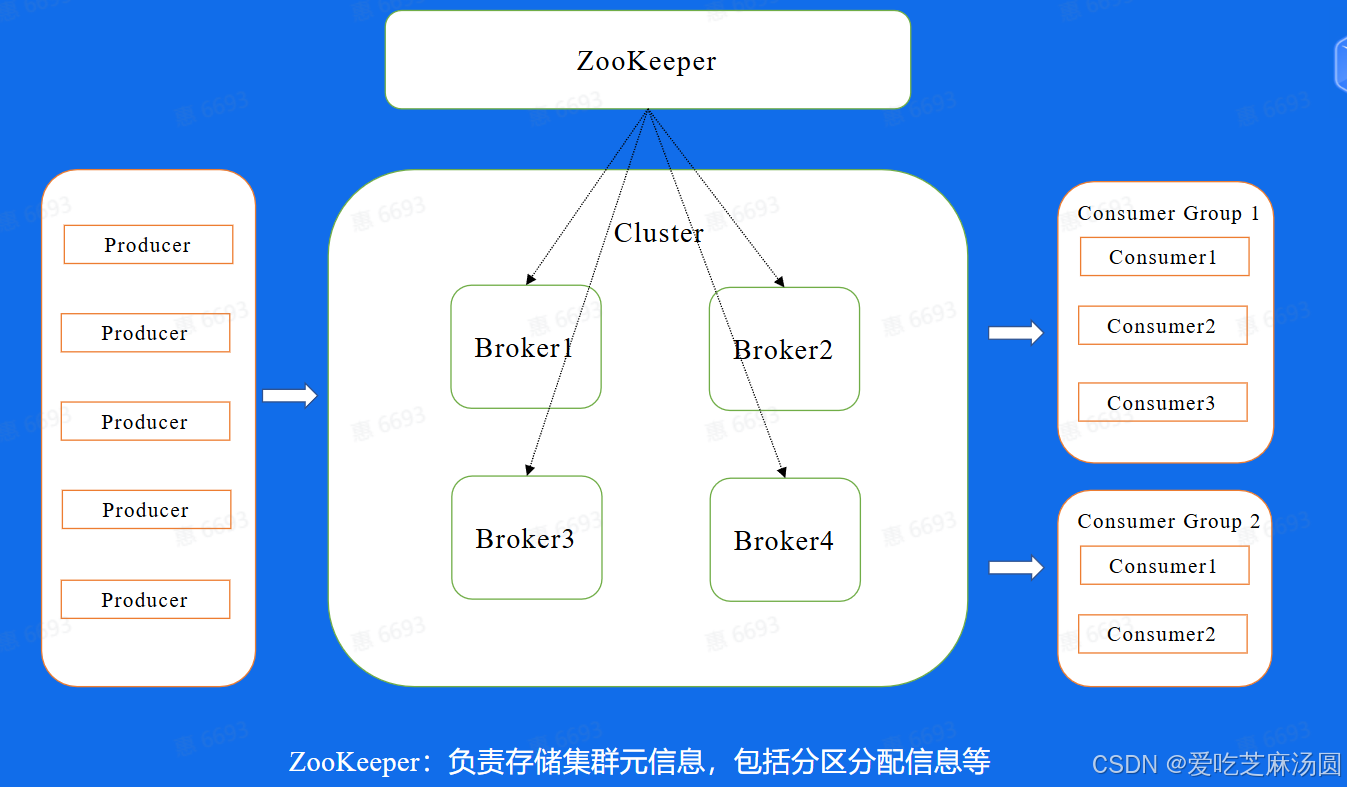
- 而在集群的基础上,还有一个模块是ZooKeeper,这个模块其实是存储了集群的元数据信息,比如副本的分配信息等等,Controller计算好的方案都会放到这个地方
1.2 消息传递过程
- 批量发送消息
- product通过数据压缩,减小消息大小。
- 消息被发送给broker后,以日志的形式写入磁盘。
- 以顺序写的方式写入磁盘(零拷贝),中间不会修改数据。
- consumer发送数据请求,通过二分法获取log。
- Consumer从Broker中读取数据,通过sendfile的方式,将磁盘读到os内核缓冲区后,直接转到socket buffer进行网络发送Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入
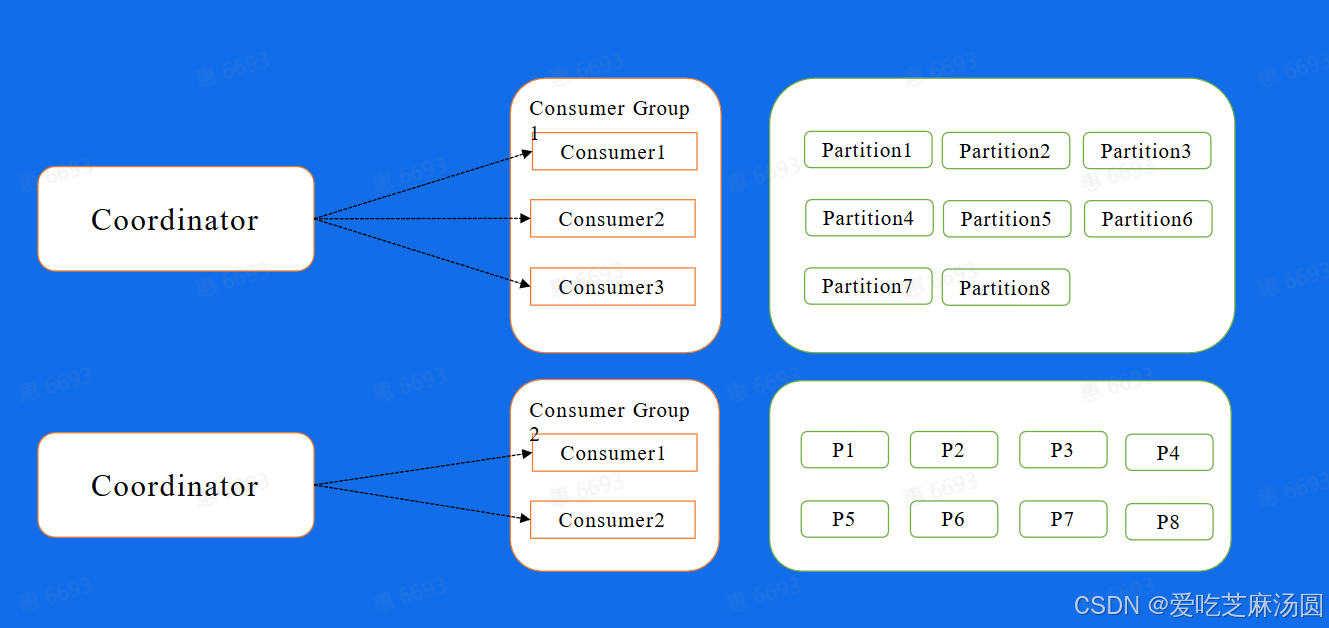
- Kafka也提供了自动分配的方式,这里也叫做High Level的消费方式,简单的来说,就是在我们的Broker集群中,对于不同的Consumer Group来讲,都会选取一台Broker当做Coordinator,而Coordinator的作用就是帮助Consumer Group进行分片的分配,也叫做分片的rebalance,使用这种方式,如果ConsumerGroup中有发生宕机,或者有新的Consumer加入,整个partition和Consumer都会重新进行分配来达到一个稳定的消费状态。
1.3 Kafka的部分问题
1.3.1 重启
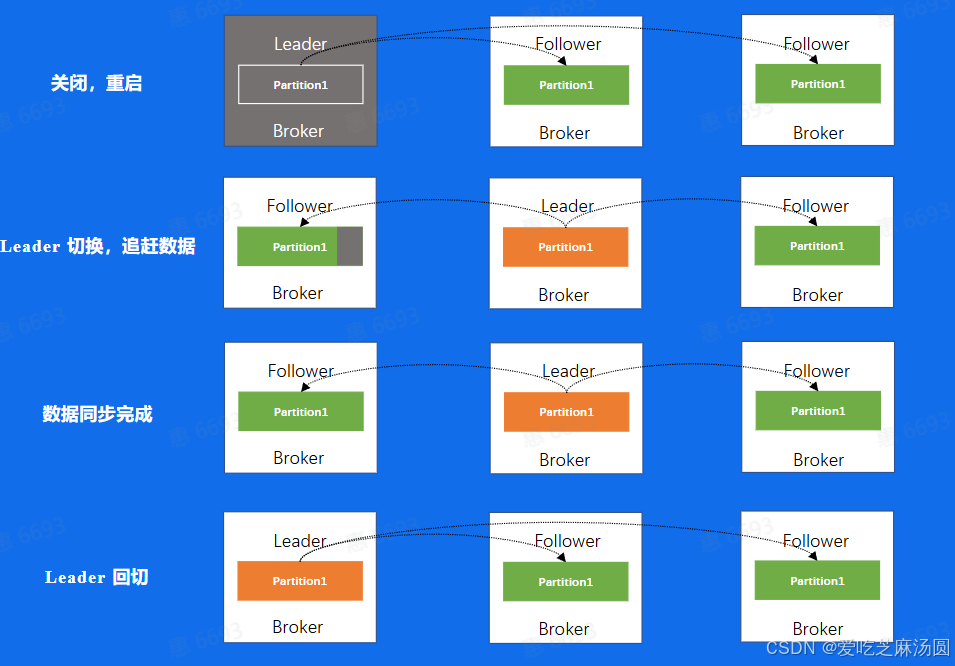
- 举个例子来说,如果我们对一个机器进行重启口首先,我们会关闭一个Broker
- 此时如果该Broker上存在副本的Leader,那么该副本将发生leader切换,切换到其他节点上面并且在ISR中的Follower副本,可以看到图中是切换到了第二个Broker上面而此时
- 因为数据在不断的写入,对于刚刚关闭重启的Broker来说,和新Leader之间一定会存在数据的滞后,此时这个Broker会追赶数据,重新加入到ISR当中
- 当数据追赶完成之后,我们需要回切leader,这一步叫做prefer leader,这一步的目的是为了避免,在一个集群长期运行后,所有的leader都分布在少数节点上,导致数据的不均衡
- 通过上面的一个流程分析,我们可以发现对于一个Broker的重启来说,需要进行数据复制,所以时间成本会比较大,比如一个节点重启需要10分钟,一个集群有1000个节点,如果该集群需要重启升级,则需要10000分钟,那差不多就是一个星期,这样的时间成本是非常大的。
- 不可以并发多台重启,在一个两副本的集群中,重启了两台机器,对某一分片来讲,可能两个分片都在这台机器上面,则会导致该集群处于不可用的状态。这是更不能接受的。
1.3.2 替换、扩容、缩容
- 替换,和刚刚的重启有什么区别,其实替换,本质上来讲就是一个需要追更多数据的重启操作,因为正常重启只需要追一小部分,而替换,则是需要复制整个leader的数据,时间会更长
- 扩容呢,当分片分配到新的机器上以后,也是相当于要从0开始复制一些新的副本
- 而缩容,缩容节点上面的分片也会分片到集群中剩余节点上面,分配过去的副本也会从0开始去复制数据以上三个操作均有数据复制所带来的时间成本问题,所以对于Kafka来说,运维操作所带来的时间成本是不容忽视的
1.3.3 负载不均衡
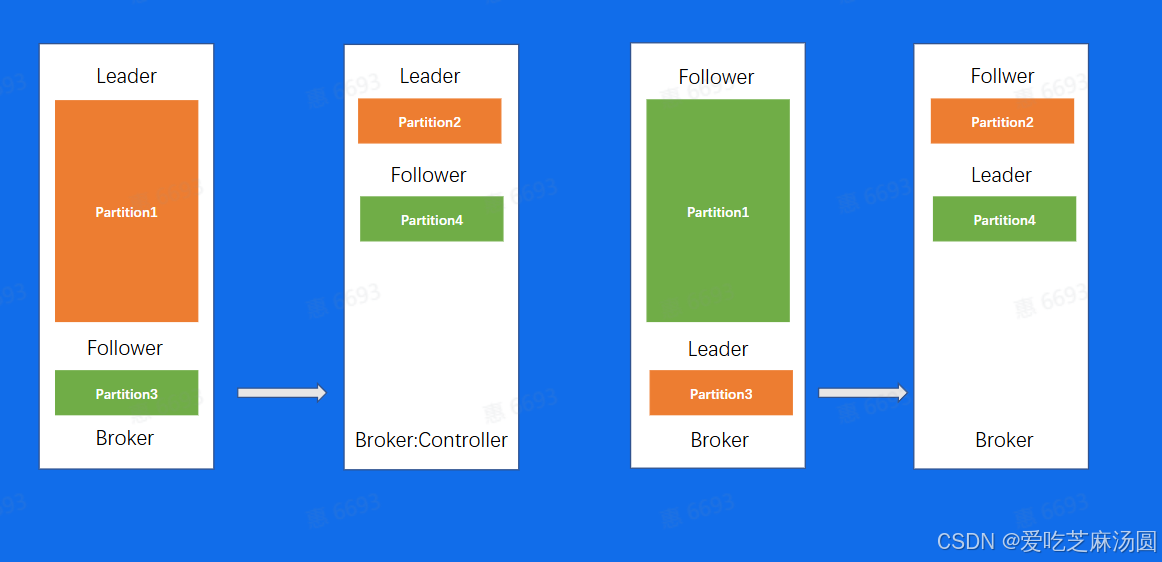
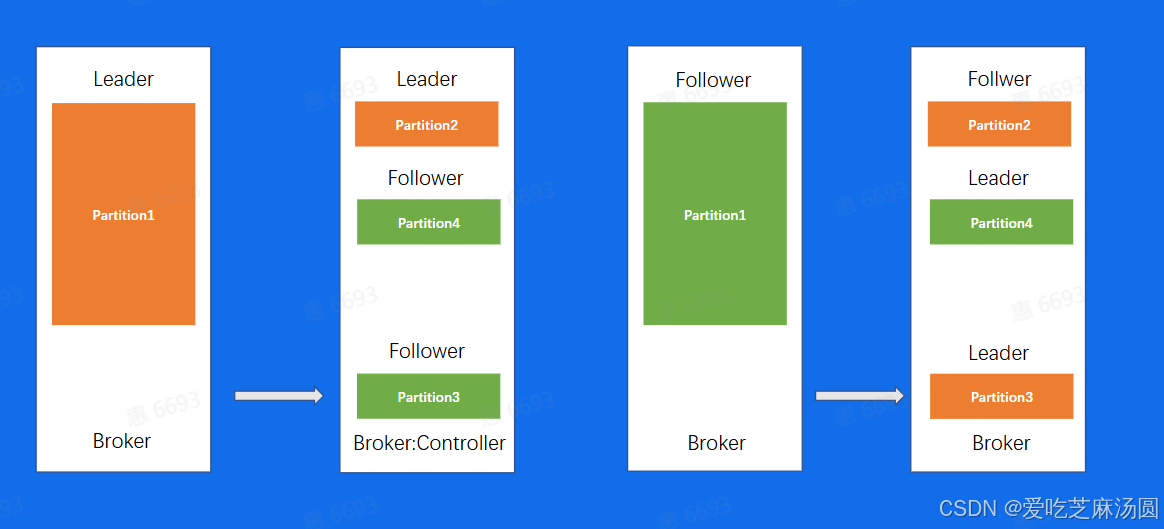
- 这个场景当中,同一个Topic有4个分片,两副本,可以看到,对于分片1来说,数据量是明显比其他分片要大的,当我们机器IO达到瓶颈的时候,可能就需要把第一台Broker上面的Partition3迁移到其他负载小的Broker上面
- 但我们的数据复制又会引起Broker1的10升高,所以问题就变成了,我为了去解决IO升高,但解决问题的过程又会带来更高的10,所以就需要权衡IO设计出一个极其复杂的负载均衡策略
1.3.4 问题总结
- 运维成本高
- 对于负载不均衡的场景,解决方案复杂
- 没有自己的缓存,完全依赖 Page Cache
- Controller 和 Coordinator和 Broker 在同一进程中,大量IO会造成其性能下降

















 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









