




 本文介绍了scikit-learn的数据变换库,包括如何使用管道(Pipeline)进行链式估计量操作,以及如何利用FeatureUnion组合特征空间。Pipeline方便了预处理步骤的串联,FeatureUnion则允许并行特征变换,两者结合可以构建复杂的数据处理流程。
本文介绍了scikit-learn的数据变换库,包括如何使用管道(Pipeline)进行链式估计量操作,以及如何利用FeatureUnion组合特征空间。Pipeline方便了预处理步骤的串联,FeatureUnion则允许并行特征变换,两者结合可以构建复杂的数据处理流程。
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
scikit-learn提供了一个数据变换库,可以实现清洗、缩减、扩展或产生特征表示。类似其它估计量,这些都由具有fit方法的类表示。fit方法从训练集学习模型参数(例如均值和标准差),transform方法应用这个变换模型到未知数据上。而fit_transform方法可以更方便高效地同时建模和变换训练数据。
管道:链式估计量
Pipeline能够把多个估计量链成一个。当预处理数据存在一个固定的步骤顺序时,例如,特征选择、归一化、分类,它是有用的。Pipeline服务于两个目的:
- 便利和打包
只需在你的数据上调用一次fit, predict, 就可以拟合整个估计过程。
- 联合参数选择
你可以在pipeline里立即grid search所有估计量的参数。
除了最后一个,在pipeline里的所有估计量,都必须被变换(即,必须有一个transform方法),最后的估计量可以是任何类型的(transformer, classifier等)。
使用方法
使用一个(key, value)对列表创建pipeline, 在这里key是一个字符串,表示你想要的步骤名字,value是一个估计量对象。
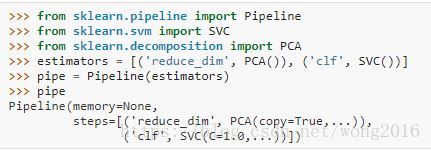
工具函数make_pipeline是pipeline的快速
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









