



本期采用matlab代码实现CNN分类。以Cifar10、MNIST数据集为例进行展示。代码直接过来复制就行!
一、Cifar10数据集简介
CIFAR10数据集一共有60000个样本,每个样本都是一张32×32像素的RGB图像(彩色图像),每个RGB图像又必定分为3个通道(R通道、G通道、B通道)。共60000个样本被分成了50000个训练样本和10000个测试样本。
CIFAR10数据集是用来监督学习训练的,且每个样本就一定都配备了一个标签值(用来区分这个样本是什么),不同类别的物体用不同的标签值,CIFAR10中一共有10类物体,标签值分别按照0~9来区分,分别是飞机( airplane )、汽车( automobile )、鸟( bird )、猫( cat )、鹿( deer )、狗( dog )、青蛙( frog )、马( horse )、船( ship )和卡车( truck )。
采用Cifar10数据集的CNN分类代码如下:
%微信公众号搜索:淘个代码,获取更多免费代码
%禁止倒卖转售,违者必究!!!!!
%唯一官方店铺:https://mbd.pub/o/author-amqYmHBs/workclc; clear; close all;
load cifar10;
%% 原始数据有6万个训练集和1万个测试集,当数据太大时,
% 程序跑起来会很慢,因此随机抽取一些数据即可验证方法准确性
% 选取10000个训练集,和1000个测试集
N_sample = 10000; %为了避免训练过于缓慢,这里仅取训练集的前10000组数据
N_test=1000; %为了避免训练过于缓慢,这里仅取测试集的前1000组数据
%% format the data
train_x = double(reshape(train_x(1:N_sample,:)',32,32,3,[]))/255;
train_x = permute(train_x, [2 1 3 4]);
train_y = double(train_y(1:N_sample,:));
test_x = double(reshape(test_x(1:N_test,:)',32,32,3,[]))/255;
test_x = permute(test_x, [2 1 3 4]);
test_y = double(test_y(1:N_test,:));
for i = 1:size(train_y,1)
[~,Train_y(i,1)]=max(train_y(i,:));
end
for i = 1:size(test_y,1)
[~,Test_y(i,1)]=max(test_y(i,:));
end
numClasses = max(Train_y);
Train_y = categorical(Train_y); %将标签转换为独热编码。
Test_y = categorical(Test_y); %将标签转换为独热编码。
% 创建CNN网络,
layers = [
imageInputLayer([size(train_x,1) size(train_x,2) size(train_x,3)], "Name","sequence")
convolution2dLayer([5,5],10,'Padding','same') % 卷积核大小为3*1 生成16个卷积
batchNormalizationLayer % 批归一化层
reluLayer %relu激活函数
maxPooling2dLayer([2,2],'Stride',2,"Name", "pool1")% 2x1 kernel stride=2
dropoutLayer(0.2)
convolution2dLayer([5,5], 24, 'Padding', 'same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer([2 1],'Stride',2,"Name", "pool2")% 2x1 kernel stride=2
dropoutLayer(0.2)
convolution2dLayer([5,5], 48, 'Padding', 'same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer([2 1],'Stride',2,"Name", "pool3")% 2x1 kernel stride=2
dropoutLayer(0.2)
flattenLayer
fullyConnectedLayer(128,'name','fullconnect1')
dropoutLayer(0.1)
fullyConnectedLayer(64,'name','fullconnect2')
dropoutLayer(0.1)
fullyConnectedLayer(numClasses,'name','fullconnect3') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
softmaxLayer('Name','softmax')
classificationLayer('name','output')];
% 参数设置
options = trainingOptions('adam', ... % 优化算法Adam
'MaxEpochs', 500, ... % 最大训练次数
'MiniBatchSize',628, ... %batchSize
'GradientThreshold', 1, ... % 梯度阈值
'InitialLearnRate', 0.001, ... % 初始学习率
'LearnRateSchedule', 'piecewise', ... % 学习率调整
'LearnRateDropPeriod', 250, ... % 训练250次后开始调整学习率
'LearnRateDropFactor',0.1, ... % 学习率调整因子
'ExecutionEnvironment', 'cpu',... % 训练环境
'Verbose', 1, ... % 关闭优化过程
'Plots', 'none'); % 画出曲线
% 训练
tic
net = trainNetwork(train_x,Train_y,layers,options);
toc
%analyzeNetwork(net);% 查看网络结构
% 预测
pred = classify(net, test_x);
accuracy=sum(Test_y==pred)/length(pred); %计算预测的确率
% 标准CNN作图
% 画方框图
figure('Position',[10,50,800,600])
set(gca,'looseInset',[0 0 0 0])
figure %创建混淆矩阵图
cm = confusionchart(Test_Y,pred);
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
xlabel('Predicted label')
ylabel('Real label')
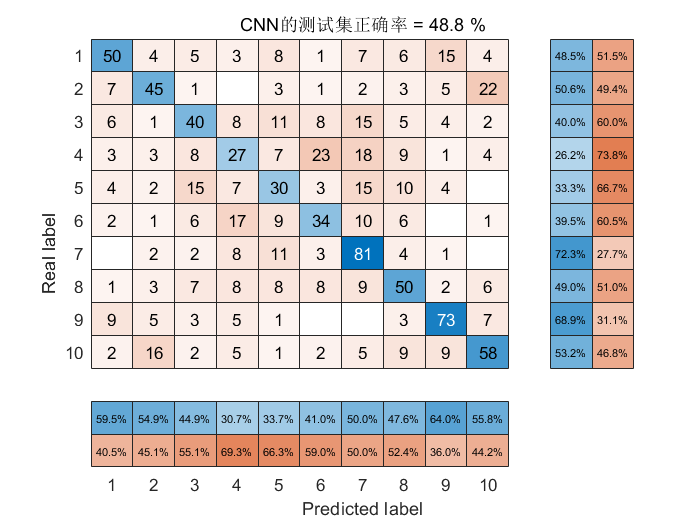
title(['CNN的测试集正确率 = ',num2str(accuracy*100),' %'])
% 作图
figure('Position',[50,50,800,600])
set(gca,'looseInset',[0 0 0 0])
plot(1:1:length(pred),Test_y,'*-','Color',[0 0.4470 0.7410],'LineWidth',1)
hold on
plot(1:1:length(pred),pred,'p-','Color',[0.9290 0.6940 0.1250],'LineWidth',0.1,'MarkerSize',3)
legend('预测类别','真实类别')
title(['CNN的测试集正确率 = ',num2str(accuracy*100),' %'])
xlabel('预测样本编号')
ylabel('分类结果')
box on
set(gca,'fontsize',12)
%微信公众号搜索:淘个代码,获取更多免费代码
%禁止倒卖转售,违者必究!!!!!
%唯一官方店铺:https://mbd.pub/o/author-amqYmHBs/work这个数据集分类比较困难,因此这里分类精度不是很高。作者在这里调整的网络并非最佳哈!大家可以自行再调一下网络。比如多增加几层卷积,全连接神经元,或者调整学习率,增大训练次数等。
二、MNIST数据集简介
关于MNIST数据集在很多图像识别的论文中都会用到,是一个很经典的数据集。MNIST手写数据集包含70000个样本,每个样本为28×28像素的灰度图片,其中训练集有60000张图片,测试集有10000张。MNIST数据集下载地址,包含了4 个部分:
训练集:train_x(9.45 MB,包含60,000个样本)。
训练集标签:train_y(28.2 KB,包含60,000个标签)。
测试集:test_x(1.57 MB ,包含10,000个样本)。
测试集标签:test_y(4.43 KB,包含10,000个样本的标签)。
采用MNIST数据集的CNN分类代码如下:
%微信公众号搜索:淘个代码,获取更多免费代码
%禁止倒卖转售,违者必究!!!!!
%唯一官方店铺:https://mbd.pub/o/author-amqYmHBs/workclc; clear; close all;
%% load MNIST dataset
% 60,000 training images in size of 28x28
% 10,000 testing images in size of 28x28
% 10 categories (0~9) with one-hot label
load mnist_uint8;
idx1 = 10000; %为了避免训练过于缓慢,这里仅取训练集的前1万组数据
idx2 = 3000; %为了避免训练过于缓慢,这里仅取测试集的前1千组数据
%% format the data
train_x = double(reshape(train_x(1:idx1,:)',28,28,1,[]))/255;
train_x = permute(train_x, [2 1 3 4]);
train_y = double(train_y(1:idx1,:));
test_x = double(reshape(test_x(1:idx2,:)',28,28,1,[]))/255;
test_x = permute(test_x, [2 1 3 4]);
test_y = double(test_y(1:idx2,:));
for i = 1:size(train_y,1)
[~,Train_y(i,1)]=max(train_y(i,:));
end
for i = 1:size(test_y,1)
[~,Test_y(i,1)]=max(test_y(i,:));
end
numClasses = max(Train_y);
Train_y = categorical(Train_y); %将标签转换为独热编码。
Test_y = categorical(Test_y); %将标签转换为独热编码。
% 创建CNN网络,
layers = [
imageInputLayer([size(test_x,1) size(test_x,2) size(test_x,3)], "Name","sequence")
convolution2dLayer([8,8],32,'Padding','same') % 卷积核大小为3*1 生成16个卷积
batchNormalizationLayer % 批归一化层
reluLayer %relu激活函数
maxPooling2dLayer([2,1],'Stride',2,"Name", "pool1")% 2x1 kernel stride=2
convolution2dLayer([4,4], 16, 'Padding', 2)
batchNormalizationLayer
reluLayer
maxPooling2dLayer([2 1],'Stride',2,"Name", "pool2")% 2x1 kernel stride=2
fullyConnectedLayer(numClasses,'name','fullconnect') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
softmaxLayer('Name','softmax')
classificationLayer('name','output')];
% 参数设置
options = trainingOptions('adam', ... % 优化算法Adam
'MaxEpochs', 30, ... % 最大训练次数
'MiniBatchSize',500, ... %batchSize
'GradientThreshold', 1, ... % 梯度阈值
'InitialLearnRate', 0.01, ... % 初始学习率
'LearnRateSchedule', 'piecewise', ... % 学习率调整
'LearnRateDropPeriod', 25, ... % 训练850次后开始调整学习率
'LearnRateDropFactor',1e-6, ... % 学习率调整因子
'L2Regularization', 0.001, ... % 正则化参数
'ExecutionEnvironment', 'cpu',... % 训练环境
'Verbose', 1, ... % 关闭优化过程
'Plots', 'none'); % 画出曲线
% 训练
tic
net = trainNetwork(train_x,Train_y,layers,options);
toc
%analyzeNetwork(net);% 查看网络结构
% 预测
pred = classify(net, test_x);
accuracy=sum(Test_y==pred)/length(pred); %计算预测的确率
% 标准CNN作图
% 画方框图
figure('Position',[10,50,800,600])
set(gca,'looseInset',[0 0 0 0])
figure %创建混淆矩阵图
cm = confusionchart(Test_Y,pred);
cm.ColumnSummary = 'column-normalized';
cm.RowSummary = 'row-normalized';
cm.Title = 'MNIST Confusion Matrix';
xlabel('Predicted label')
ylabel('Real label')
title(['CNN的测试集正确率 = ',num2str(accuracy*100),' %'])
% 作图
figure('Position',[50,50,800,600])
set(gca,'looseInset',[0 0 0 0])
plot(1:1:length(pred),Test_y,'*-','Color',[0 0.4470 0.7410],'LineWidth',1)
hold on
plot(1:1:length(pred),pred,'p-','Color',[0.9290 0.6940 0.1250],'LineWidth',0.1,'MarkerSize',3)
legend('预测类别','真实类别','NorthWest')
title(['CNN的测试集正确率 = ',num2str(accuracy*100),' %'])
xlabel('预测样本编号')
ylabel('分类结果')
box on
set(gca,'fontsize',12)
%微信公众号搜索:淘个代码,获取更多免费代码
%禁止倒卖转售,违者必究!!!!!
%唯一官方店铺:https://mbd.pub/o/author-amqYmHBs/work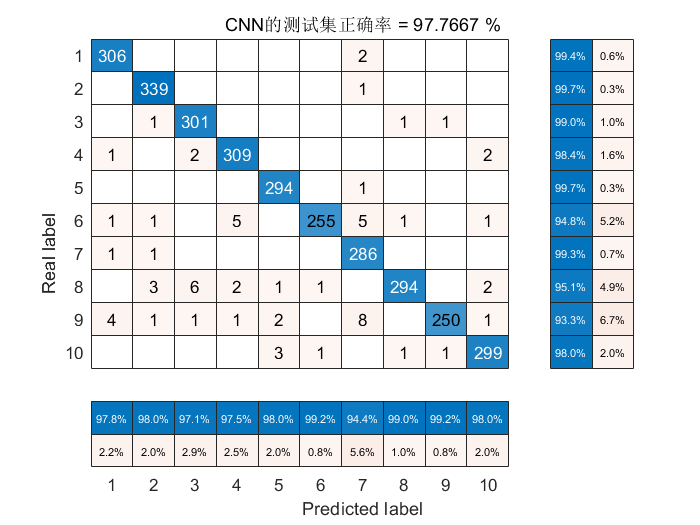
Cifar10、MNIST数据集获取链接为:
https://pan.baidu.com/s/1d72ns4qfxLu8Atee64LmAQ?pwd=zdrc


















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











